
EC/LRC 参数选型、存储与修复成本核算模型,以及不同业务场景下的编码配置建议。


当 AI 助手开始读取代码、调用工具和执行命令,隐私问题就不再只是"会不会拿去训练"了。 0. 写在前面 这篇文章不是劝大家停止使用 AI 工具。笔者自己也很难回到没有 LLM Agent 的工作流里。 真正想讨论的问题是:我们正在把什么交给远端模型?这些数据经过哪些服务?谁能看见,谁能修改,谁能触发本地工具调用?出了问题以后,能不能审计和追责? 过去一两年,LLM Agent 正在从聊天窗口渗透到越来越多的实际工作流里。Cursor、Claude Code、Codex、Cline 这类工具让模…
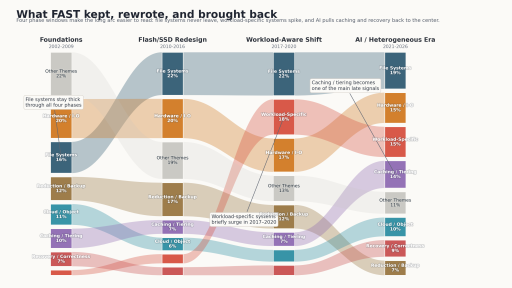
基于 FAST 2002–2026 论文集,本文梳理了存储系统研究从文件系统、Flash/SSD 到 KV cache、checkpoint 与 model loading 的迁移轨迹,重点讨论 AI 时代哪些老问题被重新推回了舞台中央。

本文面向中重度使用 LLM coding 并思考未来开发范式的工程师,以及构建大型商业项目的一人公司开发者。本文描述 BMAD v6 的工作机制、与传统敏捷开发的关系,以及人类在流程中的位置。以及笔者实际体验的一些感受。



最近季度,笔者用了一些时间尝试在实际生产系统 (分布式存储领域) 中引入大模型 LLM 和 Agent 技术,以探索大模型在日常开发、运维、以及系统问题分析的能力边界。






在扩展到分布式之前,我们先来弄明白单机 IO 的手段。同步/异步/Poller/线程池,眼花缭乱的名词,是否在故弄玄虚?



项目使用 tikv 作为分布式 KV 引擎构建了元数据服务。随着业务增长,P99 延迟急剧升高。在调优 tikv server 收获甚微后,我们把目光转回 tikv-client,结合源码和线上 metrics 分析可能的瓶颈和优化手段。

📚 分布式存储漫游指南 - 绝赞连载中!

适合分布式系统开发者、学习者和对存储技术感兴趣的朋友。逐渐整理成开源书籍。如系列文章对您有帮助,请务必给个 ⭐ 支持下!万分感谢!
⭐ GitHub / 在线阅读💬 团子云技术 - 微信公众号

同步更新技术文章和快讯
扫码关注 第一时间获取 😁
最近评论
SPtuan 发布于 2 个月前(05月19日)
tju pt 发布于 2 个月前(05月17日)
SPtuan 发布于 2 个月前(05月11日)
SPtuan 发布于 2 个月前(05月11日)
millie 发布于 2 个月前(05月10日)