在扩展到分布式之前,我们先来弄明白单机 IO 的手段。同步/异步/Poller/线程池,眼花缭乱的名词,是否在故弄玄虚?

目录计划
- 分布式存储漫游指南 1: 2025年了,存储硬件啥样了?
- 分布式存储漫游指南 2: 单机磁盘 IO 的二三事 (同步 I/O 篇)
- 分布式存储漫游指南 3: 单机磁盘 IO 的二三事 (异步 I/O 篇)
- 分布式存储漫游指南 4: 复制和分区, 我变复杂了、但也可靠了
- 分布式存储漫游指南 5: 控制节点 —— 数据节点的管理、路由与迁移修复
- 分布式存储漫游指南 6: 元数据服务与垃圾回收 (GC)
- 分布式存储漫游指南 7: S3 协议, 对象存储的事实标准
- 分布式存储漫游指南 番外1: CDN, 其实我也是存储节点
- 分布式存储漫游指南 8: 容灾与跨区异步复制
Table of Contents
0 前言
我工作使用的第一门编程语言是 Go,享受了大量原生 Goroutine、GMP 调度器的便利,我以为编程语言天生具备并发能力是一件很自然的事情。
从事分布式存储工作后,发觉有经验的同事在做系统设计时,一定会重点关注 IO 和线程模型。IO 包括用户请求到本机 IO 整个链路。而线程模型和 IO 是否阻塞、负载和性能需求息息相关。必须掌握这些,才能针对不同的用户需求设计出最佳的存储系统。
这也迫使我从系统编程语言的角度重新思考、实践了一些常见的 IO 模式。这个过程反而令我更加理解了 Goroutine 和 Go Runtime 的设计动机、了解了更多 syscall 的基础概念。
本文以小型原型为线索,记录了笔者在此主题上的所见所闻。受限于笔者的经验,本文讨论的 IO 模型以及代码实验限定在 Linux 平台上。如有谬误,感谢读者交流、指正!
Linux IO 可根据以下性质分类1
- 是否被 Kernel Page Cache 缓存(📦 Buffered/🎯 Direct)
- 是否会发生阻塞 (⏳ Sync/⚡Aysnc)
| I/O Type | ⏳ Sync I/O (Blocking) | ⚡ Async I/O (Non-blocking) |
|---|---|---|
| 📦 Buffered I/O | read(), write() |
io_uring, libaio |
| 🎯 Direct I/O | read(), write() with O_DIRECT flag |
io_uring, libaio with O_DIRECT flag |
你可以根据自己的需求选择任意一种、甚至多种合适的方式一起使用,比如写时候使用 Sync + Bufferd I/O,读的时候使用 Async + Direct I/O。
如果你是新手开发者,可以暂时搁置所有 async 相关的疑惑。不要急,今天就让我们只在 同步 IO (Sync I/O) 的世界四处看看!
1 同步 IO (Sync I/O)
一次性读完整个 Linux IO 编程接口文档,再进行编程,这也太难了!我们不妨把需求简化到极致:仅仅读写一次文件,先不计较任何的并发和性能,写完就可以交差!
1.1 posix 标准接口
对于这种简单需求,posix 标准为我们提供了一些 api 接口。
| 函数名 | 原型 |
|---|---|
lseek |
off_t lseek(int fd, off_t offset, int whence); |
write |
ssize_t write(int fd, const void *buf, size_t count); |
read |
ssize_t read(int fd, void *buf, size_t count); |
pwrite |
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset); |
pread |
ssize_t pread(int fd, void *buf, size_t count, off_t offset); |
其中:
fd: 文件描述符buf: 数据缓冲区(void*类型)count: 操作字节数(size_t类型)offset: 偏移量(off_t类型)whence: 基准位置(SEEK_SET/SEEK_CUR/SEEK_END)
在 posix 世界中,所有的文件操作,都要打开一个这个文件,得到 int 类型文件描述符 fd。为了读写它,有一个偏移游标 offset。
我们要么先去 seek 到这个 offset,然后读写文件。这期间还要注意线程安全,seek+read/write 并不是原子的。
要么使用 pwrite/pread 在一次调用中原子性地指定 offset 完成读写。
| api | lseek |
write/read |
pwrite/pread |
|---|---|---|---|
| 用途 | 移动文件指针 | 基础读写操作 | 定位读写(不移动指针) |
| POSIX 标准 | POSIX.1-1988 | POSIX.1-1988 | POSIX.1-2001 (XSI 扩展) |
| 原子性 | ❌ 非原子 | ❌ 非原子 | ✅ 原子操作 |
| 线程安全 | ❌ 需额外保证 | ❌ 需保证 | ✅ 线程安全 |
| 文件指针影响 | ✅ 修改指针位置 | ✅ 读写后指针移动 | ❌ 不影响指针位置 |
| 典型使用场景 | 随机访问文件 | 顺序读写 | 多线程/多进程并发读写 |
1.2 Code Snippet
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main() {
int fd = open("testfile.txt", O_RDWR | O_CREAT, 0644);
if (fd == -1) {
perror("open failed");
exit(1);
}
// 使用write写入数据
const char *msg1 = "Hello, world!\n";
write(fd, msg1, strlen(msg1));
// 使用lseek移动指针并写入
lseek(fd, 100, SEEK_SET);
const char *msg2 = "At position 100\n";
write(fd, msg2, strlen(msg2));
// 使用pwrite在特定位置写入(不移动指针)
const char *msg3 = "Written with pwrite at 200\n";
pwrite(fd, msg3, strlen(msg3), 200);
// 读取文件内容
char buffer[256];
lseek(fd, 0, SEEK_SET); // 回到文件开头
ssize_t bytes_read;
while ((bytes_read = read(fd, buffer, sizeof(buffer))) > 0) {
write(STDOUT_FILENO, buffer, bytes_read);
}
// 使用pread从特定位置读取
printf("\nReading with pread from position 100:\n");
bytes_read = pread(fd, buffer, sizeof(buffer), 100);
write(STDOUT_FILENO, buffer, bytes_read);
close(fd);
return 0;
}运行一下
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 01 ./01_sync_io.cpp
➜ snip git:(master) ✗ ./01
Hello, world!
At position 100
Written with pwrite at 200
Reading with pread from position 100:
At position 100
Written with pwrite at 2001.3 什么是“同步”? 为什么关注阻塞?
“同步”,指的是 Synchronous I/O,简写为 Sync I/O。是指调用的进程这期间会被阻塞 Block。我们不得不回顾一下线程模型。
强如 128 cores 的 Linux Server 其实是个大单片机!
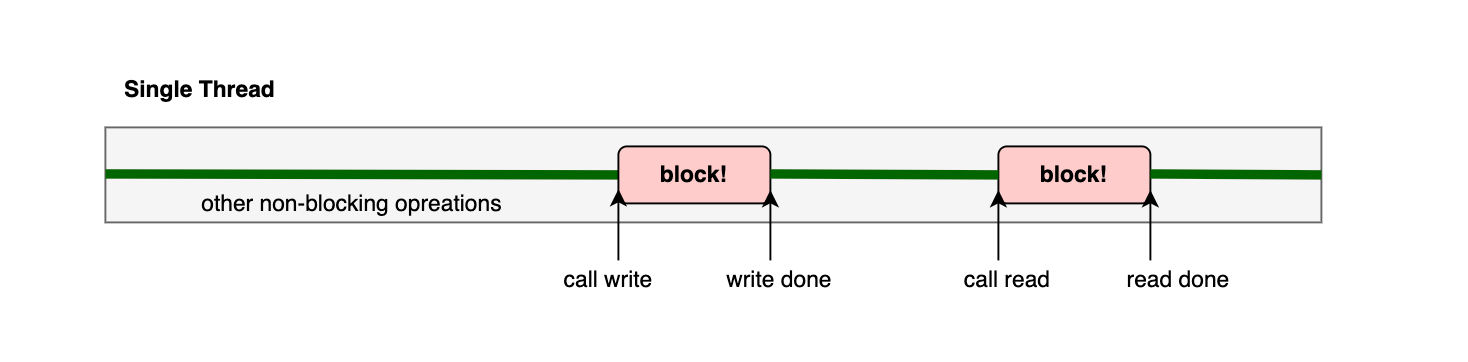
图: 单线程程序被阻塞
我们启动的单线程程序在调用 write/read 时,会进入阻塞状态。这期间 CPU 虽然可以调度给其他程序,但我们进程傻傻地(也只能傻傻地)等待这个调用返回。
示例程序的规模完全不需要担心阻塞带来的性能问题。当我们单机需要处理几十万 iops 和 数十 GBps 的流量时,阻塞以及线程上下文切换,对我们系统设计、性能的影响是巨大的。
必须意识到,实际的产品中,我们整个程序除了执行 IO 操作,还需要处理用户请求 socket、执行相关的业务逻辑、编解码等。阻塞会导致该线程强行 “闲置”。为了达到性能要求,榨干现代存储硬件给我们提供的吞吐能力,整个工程必须合理地安排线程工作内容。
因此,使用线程池管理所有阻塞 IO 的模式应运而生。我们将在稍后探索 同步 IO 的线程池模式。
1.4 Stream IO
除了 posix read/write 外,还有一种不同角度考虑的 IO 方式,流式 I/O (Stream I/O)。流式 I/O 在低级 IO 接口上构建了一层缓冲区,可以攒一些输入输出后在进行刷盘,减少系统调用和读写次数。
C 语言提供的常用流式 IO 接口如下。
| 函数 | 头文件 | 描述 |
|---|---|---|
fopen() |
<stdio.h> |
打开文件并关联到 FILE* 流对象 |
fclose() |
<stdio.h> |
关闭流并刷新缓冲区 |
fread()/fwrite |
<stdio.h> |
二进制数据的缓冲读写 |
fgets()/fputs |
<stdio.h> |
文本行的缓冲读写 |
fprintf()/fscanf |
<stdio.h> |
格式化的缓冲读写 |
setbuf()/setvbuf |
<stdio.h> |
手动控制缓冲区策略 |
fflush() |
<stdio.h> |
强制刷新输出缓冲区 |
构建存储引擎时,开发者更常见希望自己针对需求自行构建刷盘、缓冲策略,因此较少见到使用 Stream IO 构建存储引擎。其多见于日志系统的存储和读取。因此本篇不会详细介绍。
注意:此处的 Stream I/O 不是指 kernel 提供的 buffer/cache 缓存。此处指的是编程语言为我们包装的带缓冲的 I/O 库。比如我们上面 C 语言的 stdio.h,Go 语言提供的 bufio 包。
1.5 确保数据到达硬盘
LWN 上一篇文章 Ensuring data reaches disk 2 向存储系统程序员强调了持久化的认知。
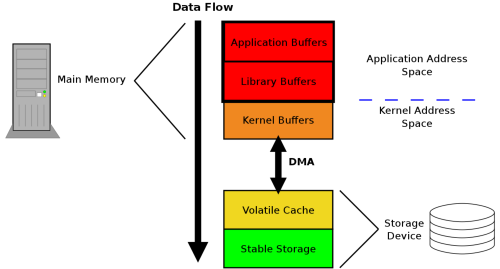
图: 数据读写的全链路 2
除了我们应用程序构建的缓存外,还可能经过 Stream IO 库提供的缓冲、Kernel 提供的 Page Cache、存储硬件上的易失/非易失性缓存,最终落在磁盘上。只有数据到达了非易失存储,才能认为数据安全保存。
一种方式是通过显式调用 sync 接口强制刷盘。另一种方式是打开文件时候指定 O_SYNC 或 O_DSYNC,在文件写入时候会被立即写入稳定存储。
值得注意的是,以上调用都是在应用程序角度尽可能执行落盘操作。例如 kernel 挂载磁盘时使用了 nobarrier,也无法保证磁盘控制器缓存的实际刷新。
性能方面,使用 O_SYNC,也代表每次写入都会写入 Kernel Page Cache 后强制落盘,性能预期会有比较大的下降。使用 fio 压测磁盘性能时,可以使用 --sync=1 观察 sync 写入性能。
例如:
fio --name=dsync_test --filename=fio_testfile --size=10G --rw=rw --rwmixread=50 --bs=4096 --ioengine=io_uring --iodepth=16 --direct=1 --sync=1 --numjobs=8 --runtime=60 --time_based --group_reporting2 直接 IO (Direct I/O)
2.1 kernel page cache
在了解 Direct I/O 之前,比如先了解下 “不直接” IO 是什么东西。Page Cache 是内核用于优化 I/O 性能的重要机制。它们通过减少磁盘访问次数、加速数据读写,显著提升系统整体性能。
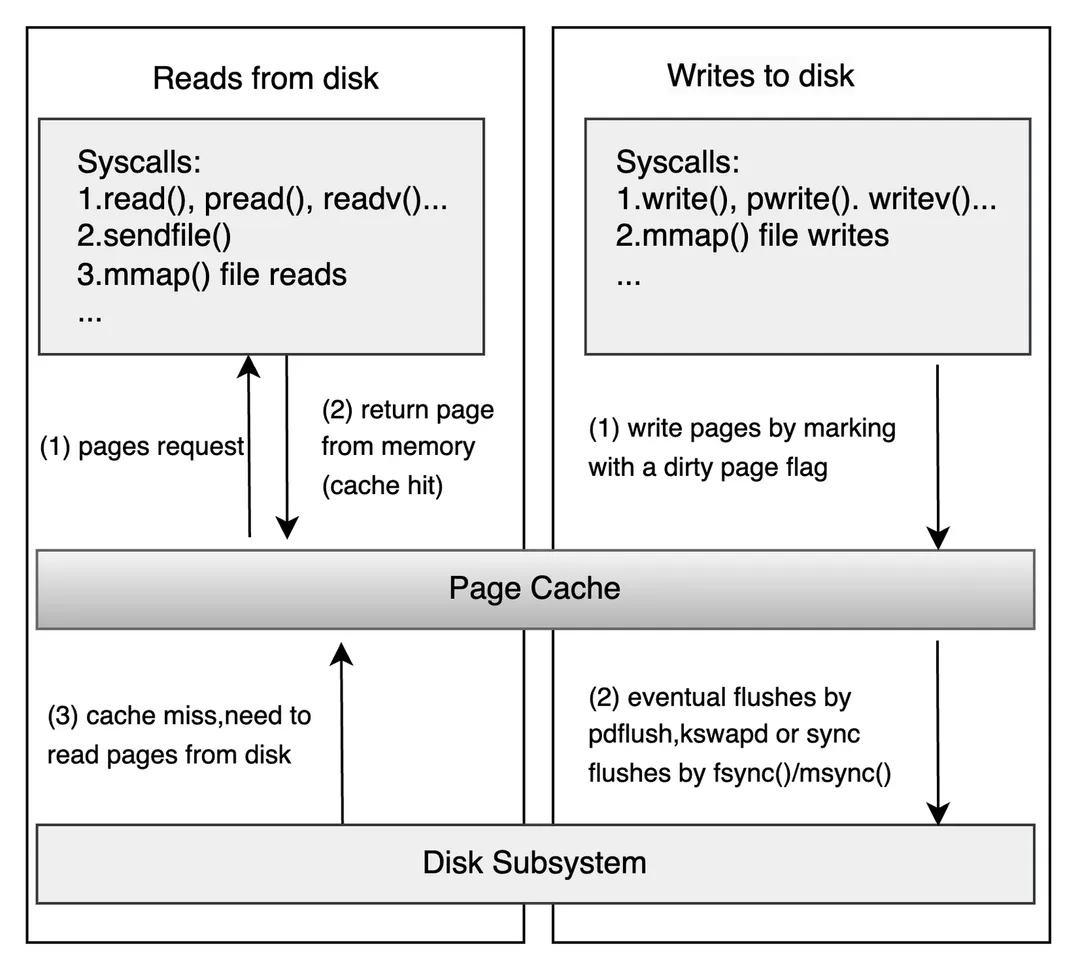
图:Page Cache 层示意图 3
当我们直接打开一个普通文件不设置 O_DIRECT 时,所有的读写默认经过 Page Cache。(有例外是某些直接设备打开会自带 DIRECT 属性,我们这里不去深究,聚焦于本地磁盘普通文件。)
// 使用 bufferd I/O
int fd = open("testfile.txt", O_RDWR | O_CREAT, 0644);2.2 基本使用
man 中向我们很好地描述了 DIRECT 的用法和注意事项。
O_DIRECT (since Linux 2.4.10)
Try to minimize cache effects of the I/O to and from this file. In general this will degrade perfor‐
mance, but it is useful in special situations, such as when applications do their own caching. File
I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to
transfer data synchronously, but does not give the guarantees of the O_SYNC flag that data and neces‐
sary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to
O_DIRECT. See NOTES below for further discussion.
A semantically similar (but deprecated) interface for block devices is described in raw(8).O_DIRECT 尝试最小化文件 I/O 的缓存效应,数据直接在用户空间缓冲区和存储设备之间传输,绕过内核页缓存。适用于需要自行管理缓存的应用程序(如数据库),但通常会导致性能下降。默认会尽力同步传输数据,但不保证数据和元数据的完整同步(需配合 O_SYNC 实现严格同步)。
限制:
对于开发者,最大的限制就是读写文件时,地址、长度和文件偏移必须满足对齐要求(通常是文件系统块大小的倍数,如 4KB)。一些文件系统 (比如 XFS) 和高版本的内核可能放宽到 512B 的对齐 4。手册中提到可以使用 ioctl(2) 的 BLKSSZGET 操作获取边界 4。对应的 shell 操作为
blockdev --getss对齐的内存可以使用 posix_memalign 申请
void* aligned_alloc(size_t size) {
void* ptr = nullptr;
if (posix_memalign(&ptr, PAGE_SIZE, size) != 0) {
perror("posix_memalign failed");
exit(EXIT_FAILURE);
}
return ptr;
}一般来讲,4KiB 是最常见的对齐 size。我们开发系统时候,需要在目标环境进行充分测试。
2.3 Code Snippet
#include <iostream>
#include <fcntl.h>
#include <unistd.h>
#include <cstdlib>
#include <cstring>
#include <sys/stat.h>
#include <sys/types.h>
// 获取系统页面大小(通常为4096字节)
const size_t PAGE_SIZE = sysconf(_SC_PAGESIZE);
// 分配对齐的内存
void* aligned_alloc(size_t size) {
void* ptr = nullptr;
if (posix_memalign(&ptr, PAGE_SIZE, size) != 0) {
perror("posix_memalign failed");
exit(EXIT_FAILURE);
}
return ptr;
}
int main() {
const char* filename = "direct_io_example.bin";
const size_t file_size = PAGE_SIZE * 4; // 4页大小
const int flags = O_RDWR | O_CREAT | O_DIRECT;
const mode_t mode = S_IRUSR | S_IWUSR; // 用户读写权限
// 1. 打开文件(使用O_DIRECT标志)
int fd = open(filename, flags, mode);
if (fd == -1) {
perror("open failed");
exit(EXIT_FAILURE);
}
// 2. 分配对齐的内存缓冲区
char* write_buf = static_cast<char*>(aligned_alloc(file_size));
char* read_buf = static_cast<char*>(aligned_alloc(file_size));
// 3. 准备写入数据
const char* message = "Hello, Direct I/O World!";
strncpy(write_buf, message, strlen(message));
std::cout << "Writing data: " << message << std::endl;
// 4. 写入文件(必须对齐的写入)
ssize_t bytes_written = write(fd, write_buf, file_size);
if (bytes_written == -1) {
perror("write failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
std::cout << "Wrote " << bytes_written << " bytes" << std::endl;
// 5. 将文件指针重置到开头
if (lseek(fd, 0, SEEK_SET) == -1) {
perror("lseek failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
// 6. 读取文件
ssize_t bytes_read = read(fd, read_buf, file_size);
if (bytes_read == -1) {
perror("read failed");
close(fd);
free(write_buf);
free(read_buf);
exit(EXIT_FAILURE);
}
std::cout << "Read " << bytes_read << " bytes" << std::endl;
std::cout << "Data read: " << read_buf << std::endl;
// 7. 清理资源
close(fd);
free(write_buf);
free(read_buf);
// 删除测试文件
unlink(filename);
return 0;
}运行一下
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 02 ./02_direct_io.cpp
➜ snip git:(master) ✗ ./02
Writing data: Hello, Direct I/O World!
Wrote 16384 bytes
Read 16384 bytes
Data read: Hello, Direct I/O World!2.3 为什么 Direct IO 有对齐要求?
现代存储设备(如 HDD、SSD、NVMe)的 I/O 操作通常以固定大小的块(通常为 512B、4KB 等)为单位进行,这是硬件设计的基本约束。
当使用 O_DIRECT 时,数据直接在用户空间缓冲区和存储设备之间传输(通过 DMA),而 DMA 控制器对内存访问有以下要求:
- 内存对齐:DMA 控制器通常需要缓冲区地址对齐到块大小边界(如 4KB),否则无法高效操作。
- 传输块大小:DMA 传输的字节数必须是块大小的整数倍,否则硬件无法处理。
即使我们不使用 O_DIRECT,内核通的页面缓存(Page Cache)和 I/O 调度器也要将用户空间的非对齐请求转换为硬件兼容的对齐操作。此时针对某个 4KiB 页的一部分并发读写,也可能遇到奇怪的问题。
2.4 为什么数据库引擎喜欢 Direct IO?
2.4.1 自行优化读取策略
数据库引擎往往自己需要实现内存缓存机制。如果仍然使用 page cache,将导致多一份内存缓存,效率不佳。
使用 page cache 时,kernel 提供了一些 hint 来提示用户的读写模式。用户可以使用 fadvise 来提示自己的读写模式。
int fd = open("large_file.bin", O_RDONLY);
posix_fadvise(fd, 0, 0, POSIX_FADV_SEQUENTIAL); // 提示顺序访问
// ... 读取文件
close(fd);内核会根据提示做一些预读 (readahead) 等操作。这些操作经过用户层的自行实现后,就没有必要了。另外用户层针对自己模式的优化性能天花板会比内核的通用高。
2.4.2 可预测的性能
避免内核做其他优化,有助于开发者根据磁盘的负载准确预计压力。每个请求也不会因为内存淘汰、sync 刷盘有较大的波动。
存储开发者处理前台用户写入时,更喜欢稳定可预测的性能,反而不是 boost 一个高峰然后反复波动的性能。
2.5 fsync 性能
要求数据写入即落盘的存储引擎 (比如写 raft log)应特别关注硬件 fsync 性能。存储引擎的日志系统一般对 fsync 的性能要求高,因为必须要等待成功落盘持久化才能进行下一步操作。文章 5 提到一个小技巧,可以把 WAL 和其他内容分离。日志专门写在 fsync 性能高的介质(一般这种介质比如傲腾的容量偏小),而其他持久化内容可以写在普通介质上。
有几个比较有趣的现象:
- 企业级的存储硬件,往往 fsync 性能远远高于消费级硬件5。
- raid 卡如果提供了非易失性缓存,对小型 io 性能有提升。硬件缓存做了一层写流量的整形。
2.6 一些讨论
2.6.1 一定首选 O_DIRECT 吗?
笔者认为不是这样的。一般看系统的需求和阶段。如果用较少的工作量就能满足需求,系统的内存较为充足,那么使用 Page Cache 绝对是性价比最高的选项。
系统当然可以先实现为默认 4KiB 对齐,后续遇到性能瓶颈再自行设计内存缓存策略。
2.6.2 使用 O_DIRECT 后还需要 O_SYNC 吗?
手册 4 明确描述:默认会尽力同步传输数据,但不保证数据和元数据的完整同步(需配合 O_SYNC 实现严格落盘数据安全性保证)。
2.6.3 O_DIRECT / O_SYNC / Sync IO 傻傻分不清?
笔者这里多啰嗦一句,Sync 翻译为 “同步”,在新手开发者入门时确实容易感到歧义。其实只要理解了他们的含义后就非常明确:两者完全不是一个概念。
O_SYNC是指数据被刷到稳定介质上,是数据安全性的 “刷盘”。打开文件时候设置这个 FLAG 即可。Sync I/O则是指这个 IO 调用会不会阻塞进程。进程需要 “同步” 等待操作完成才能返回继续运行。
3 内存映射 IO (mmap I/O)
3.1 概念
内存映射 mmap 则是从完全不同的角度处理文件读写:将整个文件透明地映射成一段内存,像操作指针一样去读写这块内存区域。
首先使用 mmap 映射打开的文件,随后可以像操作内存一样,直接使用 strncpy 之类的操作。最后使用 munmap 解除映射并清理资源。
#include <iostream>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <cstring>
int main() {
const char* filepath = "mmap_example.txt";
const size_t filesize = 4096; // 4KB文件大小
// 1. 创建并打开文件
int fd = open(filepath, O_RDWR | O_CREAT, (mode_t)0600);
if (fd == -1) {
perror("Error opening file for writing");
return 1;
}
// 2. 调整文件大小
if (lseek(fd, filesize-1, SEEK_SET) == -1) {
close(fd);
perror("Error calling lseek() to stretch the file");
return 1;
}
if (write(fd, "", 1) == -1) {
close(fd);
perror("Error writing last byte of the file");
return 1;
}
// 3. 将文件映射到内存
char* map = (char*)mmap(0, filesize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (map == MAP_FAILED) {
close(fd);
perror("Error mmapping the file");
return 1;
}
// 4. 写入数据到内存映射区
const char* text = "Hello, mmap world!";
strncpy(map, text, strlen(text));
// 5. 从内存映射区读取数据
std::cout << "Read from mmap: " << map << std::endl;
// 6. 清理
if (munmap(map, filesize) == -1) {
close(fd);
perror("Error un-mmapping the file");
return 1;
}
close(fd);
return 0;
}运行一下
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 03 ./03_mmap.cpp
➜ snip git:(master) ✗ ./03
Read from mmap: Hello, mmap world!3.2 优势和局限性
mmap 数据直接从磁盘映射到用户空间,避免了内核缓冲区到用户缓冲区的拷贝。
还有一种用得比较多的方式是作为进程间通信使用,直接共享内存交换数据。
笔者很少见到使用 mmap 作为读写数据引擎的基本方式。在构建存储引擎时,有开发者批评 mmap 的劣势在于不能完全掌控背后内核的内存管理和刷盘机制6。
开发者如果使用 mmap,尤其是文件远远大于机器内存的情况下需要调优。RocksDB 曾遇到一个未设置 fadvise 导致性能下降的 issue7。Rocksdb 手册8 提到如果数据在内存 fs 中,开启 mmap 会带来比较大的性能提升,否则应该谨慎试用 mmap 选项。
4 同步 IO 的线程池模式 (thread-pool)
4.1 动机
在上文中,我们已经意识到了 Sync IO 调用会阻塞我们的线程。这期间对 CPU 反而是闲置,这就是我们常说的 I/O 密集任务。(另一个反面是计算密集型任务,会持续占用 CPU 进行有效计算。)
这种线程闲置也会导致同时提交到存储硬件的 IO 操作变少,很难榨干存储硬件能力,尤其是 SSD 介质。
因此,一种自然而然的模式就应运而生了。既然阻塞一个线程,那我们就用一组线程,提高整体的并发 —— 将所有同步 IO 交由一组线程执行。
接下来我们实现一个示例程序作为演示,包含 1 组 IO 线程,还有额外 1 个线程模拟用户的 rpc 读写逻辑。
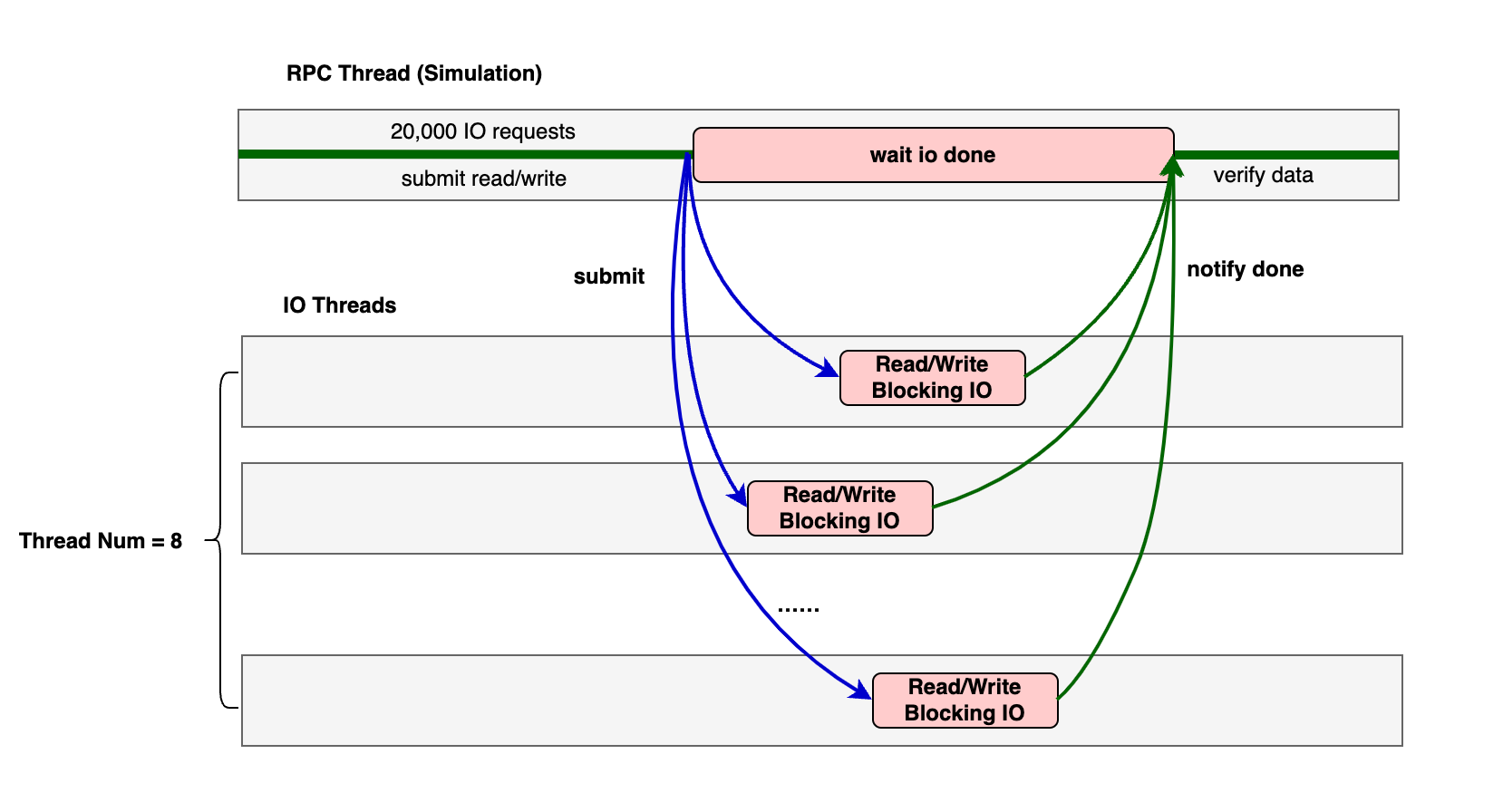
图: 示例程序的线程分工
4.2 Code Snippet
4.2.1 简单的线程池实现
我们新建一个 IOThreadPool 类,构造时使用 std::thread 创建线程。RPC 模拟线程可以通过 enqueue 提交任务函数进入队列。工作线程从队列里取出任务并执行。
class IOThreadPool {
public:
explicit IOThreadPool(size_t num_threads) : stop(false) {
for (size_t i = 0; i < num_threads; ++i) {
// create worker thread
workers.emplace_back([this] {
// worker loop
while (true) {
std::function<void()> task;
// fetch task
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock,
[this] { return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty())
return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
// do task
task();
}
});
}
}
void enqueue(std::function<void()> task) {
{
std::unique_lock<std::mutex> lock(queue_mutex);
if (stop) {
throw std::runtime_error("enqueue on stopped ThreadPool");
}
tasks.push(task);
}
condition.notify_one();
}
~IOThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers) {
worker.join();
}
}
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex queue_mutex;
std::condition_variable condition;
std::atomic<bool> stop;
};4.2.2 模拟用户 rpc 线程
创建一个线程来模拟用户读写的 rpc 执行。这里我们处理内存,提交 IO 任务,等待所有 IO 执行完成,最终进行数据验证。
这里我直接提交了 lambda 函数。由 IO Thread Pool 工作进程执行。lambda 函数内的 IO 操作完成后,设置同步原语标记这笔 IO 完成。
注意:我在写操作使用了 fsync 保证数据安全性。这将导致 IO 阻塞时间变长,以突出 IO 线程池的效果。
void simulate_user_rpc(IOThreadPool &pool, int fd) {
std::vector<std::shared_ptr<IOResult>> write_results;
auto start_time = std::chrono::high_resolution_clock::now();
// sequential write
for (int i = 0; i < IO_COUNT; ++i) {
auto write_buf = std::make_shared<std::array<char, BLOCK_SIZE>>();
char content_char = 'A' + (i % 26);
memset(write_buf->data(), content_char, BLOCK_SIZE);
off_t offset = i * BLOCK_SIZE;
auto result = std::make_shared<IOResult>();
write_results.push_back(result);
pool.enqueue([fd, offset, write_buf, result] {
ssize_t ret = pwrite(fd, write_buf->data(), BLOCK_SIZE, offset);
auto completed = true;
if (fsync(fd) == -1) {
std::cerr << "fsync failed" << std::endl;
completed = false;
}
{
std::lock_guard<std::mutex> lock(result->mutex);
result->fd = fd;
result->offset = offset;
result->result = ret;
result->completed = completed;
result->buffer = std::move(write_buf);
}
result->cv.notify_one();
});
}
// random read
std::vector<std::shared_ptr<IOResult>> read_results;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, IO_COUNT - 1);
for (int i = 0; i < IO_COUNT; ++i) {
int block_num = dis(gen);
off_t offset = block_num * BLOCK_SIZE;
auto read_buf = std::make_shared<std::array<char, BLOCK_SIZE>>();
auto result = std::make_shared<IOResult>();
read_results.push_back(result);
pool.enqueue([fd, offset, read_buf, result] {
ssize_t writen = pread(fd, read_buf->data(), BLOCK_SIZE, offset);
{
std::lock_guard<std::mutex> lock(result->mutex);
result->result = writen;
result->fd = fd;
result->offset = offset;
result->completed = true;
result->buffer = std::move(read_buf);
}
result->cv.notify_one();
});
}
// wait for all write operations to complete
bool write_all_success = true;
for (auto &result : write_results) {
std::unique_lock<std::mutex> lock(result->mutex);
result->cv.wait(lock, [&result] { return result->completed; });
if (result->result != BLOCK_SIZE) {
write_all_success = false;
std::cerr << "IO operation failed with return: " << result->result << std::endl;
}
}
// wait for all read operations to complete
bool read_all_success = true;
for (auto &result : read_results) {
std::unique_lock<std::mutex> lock(result->mutex);
result->cv.wait(lock, [&result] { return result->completed; });
if (result->result != BLOCK_SIZE) {
read_all_success = false;
std::cerr << "IO operation failed with return: " << result->result << std::endl;
} else {
// check data integrity
char expected_char = 'A' + (result->offset / BLOCK_SIZE) % 26;
std::vector<char> compare_buffer(BLOCK_SIZE, expected_char);
if (std::memcmp(result->buffer->data(), compare_buffer.data(), BLOCK_SIZE) != 0) {
read_all_success = false;
std::cerr << "Data integrity check failed at offset: " << result->offset
<< std::endl;
}
}
}
auto end_time = std::chrono::high_resolution_clock::now();
if (write_all_success && read_all_success) {
std::cout << "All IO operations completed successfully!" << std::endl;
std::cout << "Total IO operations: " << IO_COUNT * 2 << std::endl;
std::chrono::duration<double> elapsed = end_time - start_time;
std::cout << "Elapsed time: " << elapsed.count() << " seconds" << std::endl;
std::cout << "IOPS: " << IO_COUNT * 2 / elapsed.count() << std::endl;
std::cout << "Throughput: "
<< static_cast<double>(IO_COUNT * 2 * BLOCK_SIZE) / elapsed.count() /
(1024 * 1024)
<< " MB/s" << std::endl;
} else {
std::cout << "Some IO operations failed!" << std::endl;
}
}4.2.3 初始化并运行
int main(int argc, char *argv[]) {
const std::string test_file = "io_pool_test.bin";
size_t num_io_threads = 4;
if (argc > 1) {
try {
num_io_threads = std::stoul(argv[1]);
if (num_io_threads == 0) {
std::cerr << "Thread count must be greater than 0, using "
"default value 4"
<< std::endl;
num_io_threads = 4;
}
} catch (const std::exception &e) {
std::cerr << "Invalid thread count argument, using default value 4: " << e.what()
<< std::endl;
}
}
std::cout << "Using IO thread pool size: " << num_io_threads << std::endl;
int fd = open(test_file.c_str(), O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
std::cerr << "Failed to open file" << std::endl;
return 1;
}
try {
IOThreadPool pool(num_io_threads);
simulate_user_rpc(pool, fd);
} catch (const std::exception &e) {
std::cerr << "Error: " << e.what() << std::endl;
close(fd);
return 1;
}
close(fd);
return 0;
}运行一下看看
➜ snip git:(master) ✗ g++ -Wall -Wextra -g -o 04 ./04_io_thread_pool.cpp
➜ snip git:(master) ✗ ./04 8
Using IO thread pool size: 8
All IO operations completed successfully!
Total IO operations: 1000000
Elapsed time: 89.6841 seconds
IOPS: 11150.3
Throughput: 43.5557 MB/s4.3 性能和讨论
笔者设置不同的线程数,在同机器上的 SATA SSD 和 NVMe SSD 上尝试。其中,IO 大小 4KiB,关注 IOPS。
SATA SSD
| 设备类型 | 线程数 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|---|
| SATA SSD | 2 | 1,000,000 | 33.7835 | 29,600.2 | 115.626 |
| SATA SSD | 8 | 1,000,000 | 25.2971 | 39,530.3 | 154.415 |
| SATA SSD | 64 | 1,000,000 | 26.4295 | 37,836.5 | 147.799 |
| SATA SSD | 128 | 1,000,000 | 29.108 | 34,354.8 | 134.199 |
| SATA SSD | 256 | 1,000,000 | 34.9604 | 28,603.8 | 111.733 |
| SATA SSD | 512 | 1,000,000 | 43.883 | 22,787.8 | 89.015 |
NVMe SSD
| 设备类型 | 线程数 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|---|
| NVMe SSD | 2 | 1,000,000 | 30.7639 | 32,505.7 | 126.975 |
| NVMe SSD | 8 | 1,000,000 | 15.191 | 65,828.4 | 257.142 |
| NVMe SSD | 64 | 1,000,000 | 12.6304 | 79,173.9 | 309.273 |
| NVMe SSD | 128 | 1,000,000 | 20.4492 | 48,901.6 | 191.022 |
| NVMe SSD | 256 | 1,000,000 | 43.5615 | 22,956.1 | 89.672 |
| NVMe SSD | 512 | 1,000,000 | 55.7664 | 17,931.9 | 70.047 |
可以看到,我们的线程数从 2 开始增加,性能逐渐提升。但线程数过大之后,反而逐渐下降。相比于单线程顺序读写,使用线程池模式无疑提高了我们系统的 IO 性能!真是令人愉悦。
但开发者要时刻记得我们最初的动机:同步 IO 不能榨干硬件性能,所以用线程池来凑。但随着线程数量增长,上下文切换带来的代价开始逐渐显现,系统的瓶颈反而逐渐转移到了线程切换和线程间同步上面。此时操作系统的 CPU 消耗也会变高
观察到 SATA SSD 在线程池模型下、线程数为 8 时性能较好,初步认为达到了硬件性能预期。我们也有理由怀疑,虽然 NVMe SSD 在线程数为 64 时表现较好,是不是远远没有达到其硬件能力? 更多地掣肘我们的,可能是线程间的切换和同步代价了(考虑线程锁效率?NUMA消耗?大量线程切换导致的 sys cpu 占用等等)。单个 IO 线程只能同时进行一个 IO,而我们又不能无限地增大线程数量。
笔者深深地认为,选择合适 IO 模型,一定要评估我们系统的实际需求和硬件的规模。比如:
- 系统需求:注重高扩展性?高性能?
- 硬件规模:HDD/SSD?单机器 CPU 和 disk 配比?
5 小结
本文和读者一起探索了 Linux 世界的同步磁盘 IO。
- 我们一开始完全不关心性能,体验了单线程的同步 bufferd IO。(1.1 节)
- 然后意识到了同步 IO 调用的阻塞问题。(1.3 节)
- 意识到了数据安全性如何保证。(1.5 节)
- 学会了如何绕过 kernel page cache,直接操作硬盘。 (2 节)
- 简单了解了 Stream IO (1.4 节) 和 mmap (3 节)。
- 最终尝试使用线程池模式改善了并发 IO 性能。(4 节)
我们已经意识到了单纯的线程池同步 IO,总是有一定掣肘(线程间同步代价、单机线程总数)。这将限制我们打造极限高性能的存储系统。有没有其他的方式另辟蹊径呢?不用着急,我们将在下一篇文章探索另外一片全新的大陆:异步 IO (Async I/O)!
参考资料
-
[我选了几个 emoji 希望能帮助读者理解,但让文章产生一股子 AI 味道 👊🤖🔥]() ↩



