分布式人两个重要手段:Partition 和 Replicate。其宛如两板斧一样大道至简,不必故弄玄虚。本文聚焦于 复制 主题。
然而,一旦分布式开发者熟悉了这套模式,就会惊奇地发现,所有的分布式系统方案,本质上都是在回答这两个问题(也会惊奇地发现自己由小登向中登转变,难免有一丝淡淡的悲伤✋😭🤚)。

Table of Contents
1 背景和动机
让我们暂时忘记这些手段吧,不妨先来看看技术背景是什么。前文中,我们讨论了分布式系统中混沌的环境,网络、计算随时都可能崩溃、损坏。
如果我们仍然延续单机应用的做法,会发生什么?
- 数据安全性威胁:数据只有一份,先不考虑天灾,只是这块磁盘挂点后就再无退路可言!
- 数据单机瓶颈:磁盘/内存的读写总是有上限的,那超过上限的请求,怎么抗?
- 计算单机瓶颈:CPU 的计算能力和线程数量总是有上限的,那超过上限的请求,怎么抗?
如果我们有一台能够无限扩容的单机就好了!然而事实是残酷的。有个最简单的方式是花钱请人设计系统1!(这样我们就能把他们交付的系统当做单机用了!^_^ )。要么只能想一些工程手段去绕开单机的瓶颈。
分布式思想是如此地朴素:
- 单机无法满足要求,那多台机器咋样?
- 单机磁盘容易爆炸,那我就多复制几份可否?顺便顶一下磁盘 IO 流量?
- 单机计算不行,那我们就分开计算、最后合并结果如何?
现有常见的分布式系统便可以如下梳理:
| 系统 | 复制(Replication)核心思想 | 分区(Partition)核心思想 |
|---|---|---|
| GFS - 存储 | 数据副本:(默认3份)跨机架存储数据块,实现容错和高可用,避免单点/机架 故障导致数据丢失 | 数据分区:将大文件拆分为固定大小数据块(64MB),分散存储在不同节点,突破单机存储容量限制 |
| MapReduce - 计算 | 任务副本:当某个 Reduce 任务失败时,系统会在其他节点重新调度该任务(计算任务的复制) | 任务分区:将输入数据分片,每个分片对应一个 Map 任务;中间结果按 Key 分区,实现并行计算和相同 Key 的聚合处理 |
| Flink - 计算 | 任务副本:关键任务可配置 “备用任务(Standby Task)”,主任务故障时快速切换 | 任务分区:将数据流拆分为多个并行子流,通过灵活的分区策略(哈希、轮询等)分配给不同算子实例,提升计算并行度 |
| Kafka - 消息队列 | 数据副本:每个分区,Leader 负责读写,Follower 同步数据并作为故障备份 | 数据分区:将主题拆分为多个分区,作为并行读写的基本单位,通过 Key 路由保证相同消息的有序性和集中处理 |
这些系统无非是将任务或者数据进行分区和复制操作。鉴于我们是分布式存储漫游指南,后续本文内容都是指存储系统视角。
2 分布式存储引擎与复制组
复制组是分布式存储系统中的一个基本存储单元。这个单元目的就是将用户数据读写和内部的数据复制机制分层隔离。
对于用户:
- 带着自己的key和数据(或只携带数据)前来写入
- 开开心心地拿到成功的 Response 继续干活
- “不关心”2底层怎么达成的复制和一致性
对于分布式存储引擎:
- 输入是上层的一小块数据。
- 输出是一个代表数据路由的 key。用户可以通过这个唯一 key 来取回数据。
- 内部如何对数据复制、修复、甚至编码转换,都是对用户透明的2。
一个可能的分布式存储引擎系统设计例:
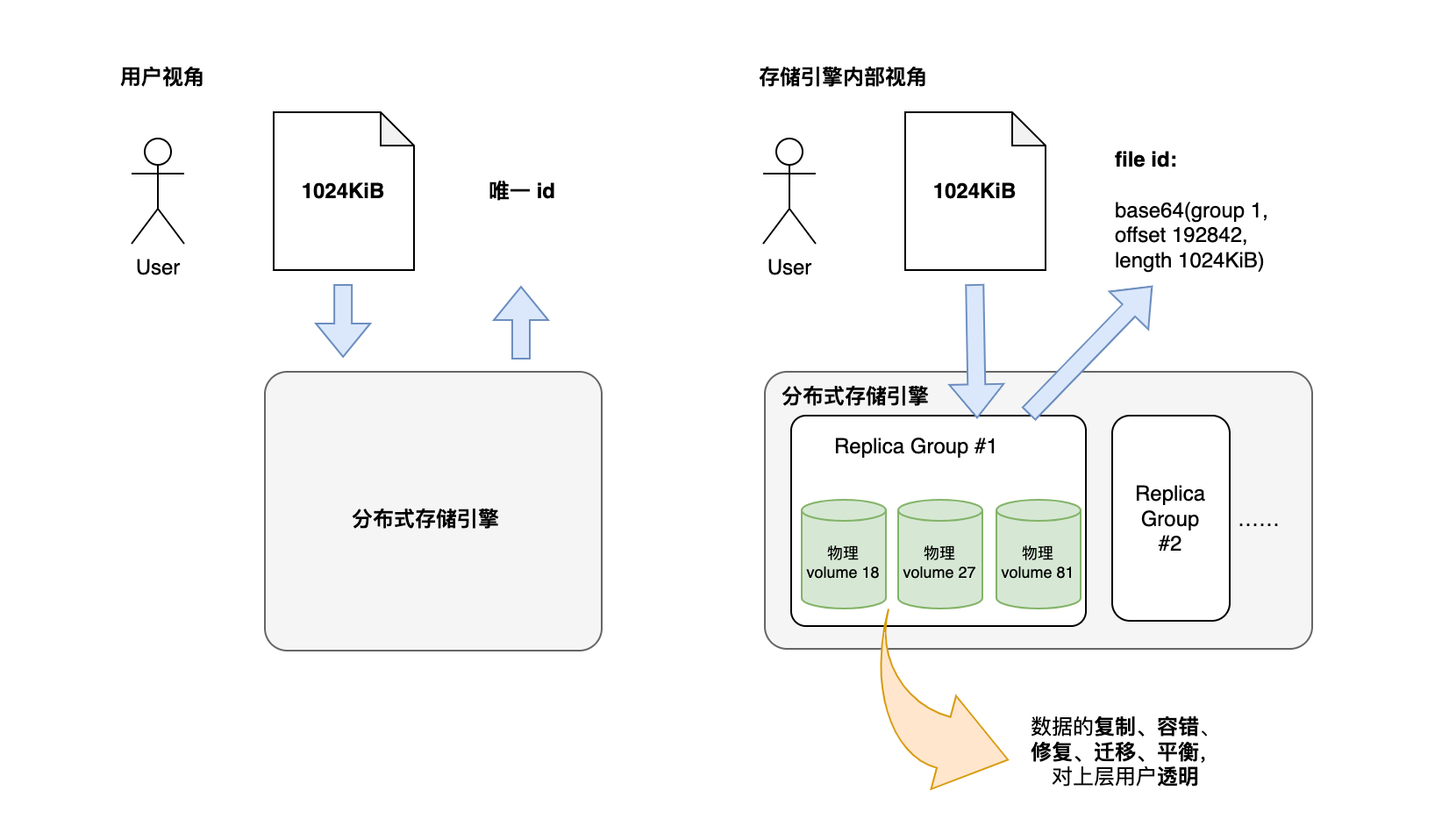
该例子中,将一组物理或虚拟的 volume 结成一组,编码类型为副本,数量为3。
设计这个单元需要考虑编码类型 (副本组/EC组)、容量规模(~64MiB or ~512GiB)。创建和删除形式中,它可能也是多样的 (静态逻辑卷/动态数据块)。各类系统(文件系统, 对象存储, 块存储等)根据需求设计合适的手段。以下使用表格总结可查证系统的复制组设计。
| 系统名称 | 类型 | 组织形式 | 创建方式 | 复制组规模 | 编码支持 |
|---|---|---|---|---|---|
| CubeFS | 文件系统 | 容量分区(DP) | 动态 | 每 DP 120GB(默认) | 副本/EC |
| Ceph | 对象存储 | 放置组(PG) | 静态预分配 | 单 PG 约 1-10 万个对象 | 副本/EC |
| Azure Storage | 存储底座 | Extent | 动态 | 每 Extent 1GB | 副本/EC |
值得指出的是,一切都是工程取舍。复制组越大,创建越静态,平衡迁移越重。但有一个巨大优势就是路由管理节点就可以很轻,甚至不可用也不影响用户流量。详细取舍我们将在 “分区” 部分讨论。
3 复制链路和一致性模型
数据复制总要选取一种具体的方式。使用单一维度来归纳复制手段实在困难。本节纯属作者根据个人理解,从复制链路、一致性达成条件来归纳,欢迎评论区展开讨论。
现在考虑一个最简单的 三副本数据复制 场景。
3.1 链路:主节点并行复制
(主节点)并行复制:即复制组中选取一个节点,用户先将数据发往这个确定的节点,由此节点负责向其余同伴发起请求。
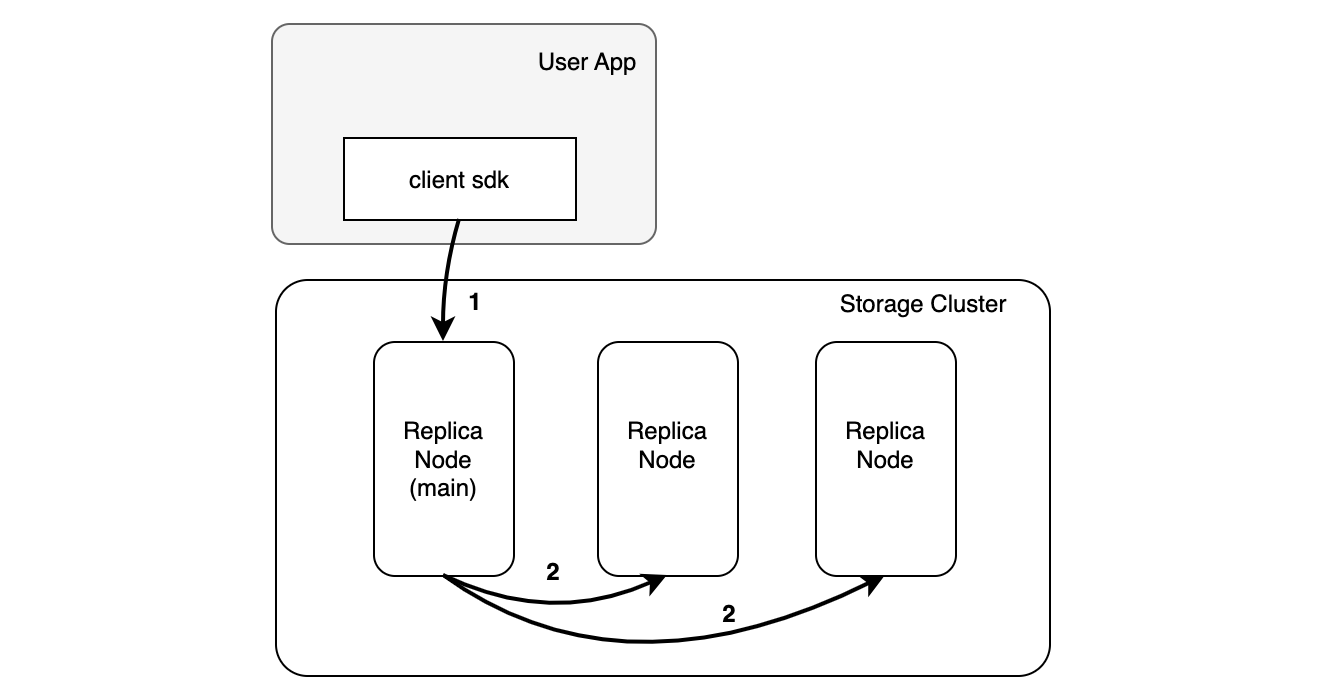
优势: 节省客户端与集群的流量
值得指出的是,复制必然意味着网络带宽的成倍增加。此模式在客户端和存储集群之间的流量仅为1倍。
优势: 更轻量的客户端
这个主要看用户的团队形态。此模式的客户端的设计可以更加轻量。在庞大用户场景,升级 client sdk 可能是个巨大工程。因此 client sdk 一旦定版,除非有恶性 bug 否则不需要上游团队配合更新,会减少很多工作量。
劣势:最大延迟
最大延迟是用户到主节点 + 主节点到最慢的复制节点中。
劣势:资源消耗
选取的主节点除了承担存储服务,也负责流量转发,消耗更多资源。
3.2 链路:主节点链式复制
(主节点)链式复制:用户发往复制组中其中一个节点,数据按次序接力复制。
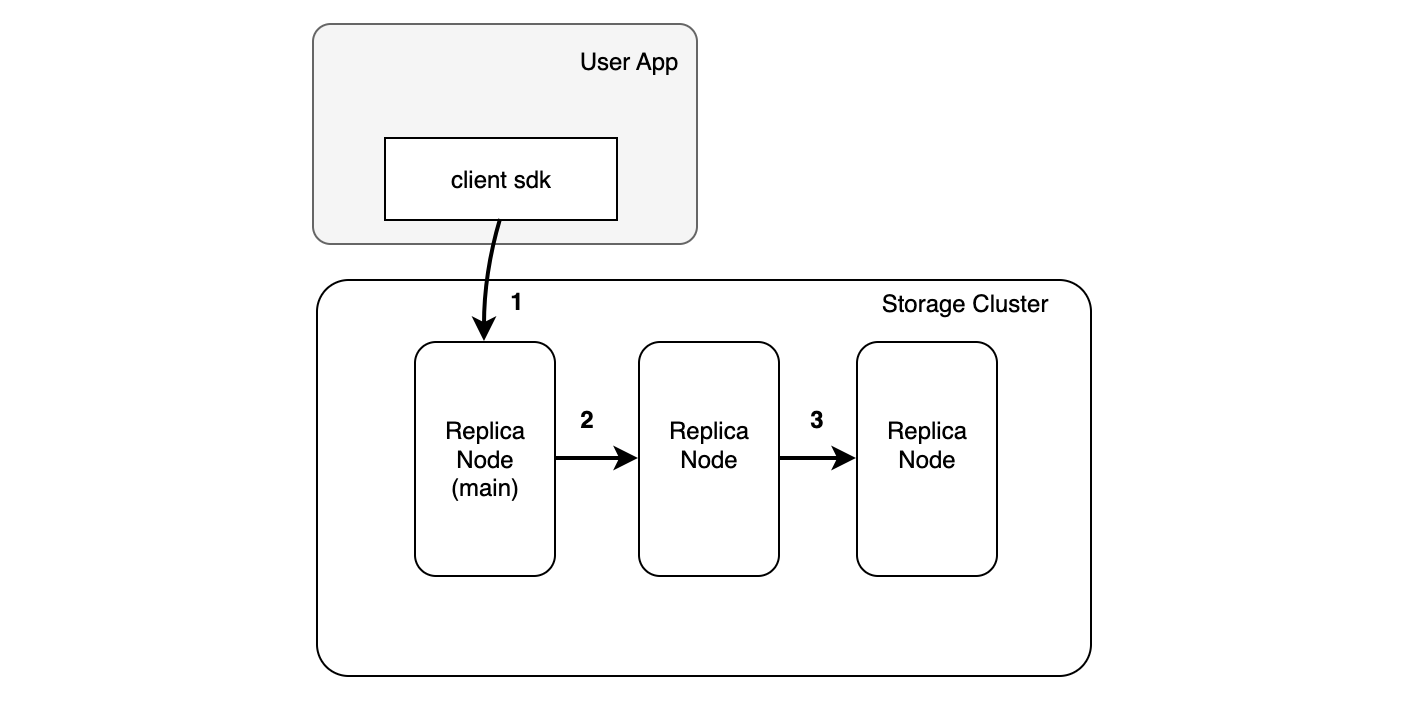
优势:一致性保障简洁
链式复制在节点故障时候可以指定新节点快速充足复制组。逐个复制直到最终节点,由最终节点确认复制成功。这种方式保证所有节点的全一致性是方便的。3FS 使用了这种链式复制。
优势:带宽均匀
链式复制相比于主节点并行复制,带宽会更均匀。但根据 Little's Law,复制副本数量不变,数据包在系统中传播的时间延长了,带宽峰值是没有节省的。
劣势:请求时延高
最大的缺点显而易见,请求延迟等于所有节点复制的加和。这在 HDD 组成的集群中大概率是不可接受的,除非有特别的理由(用户只看带宽不看吞吐,写少读多,或需要简化系统设计等)。
3.3 链路:客户端星形复制
星形复制:用户直接向复制组中所有节点发送请求。
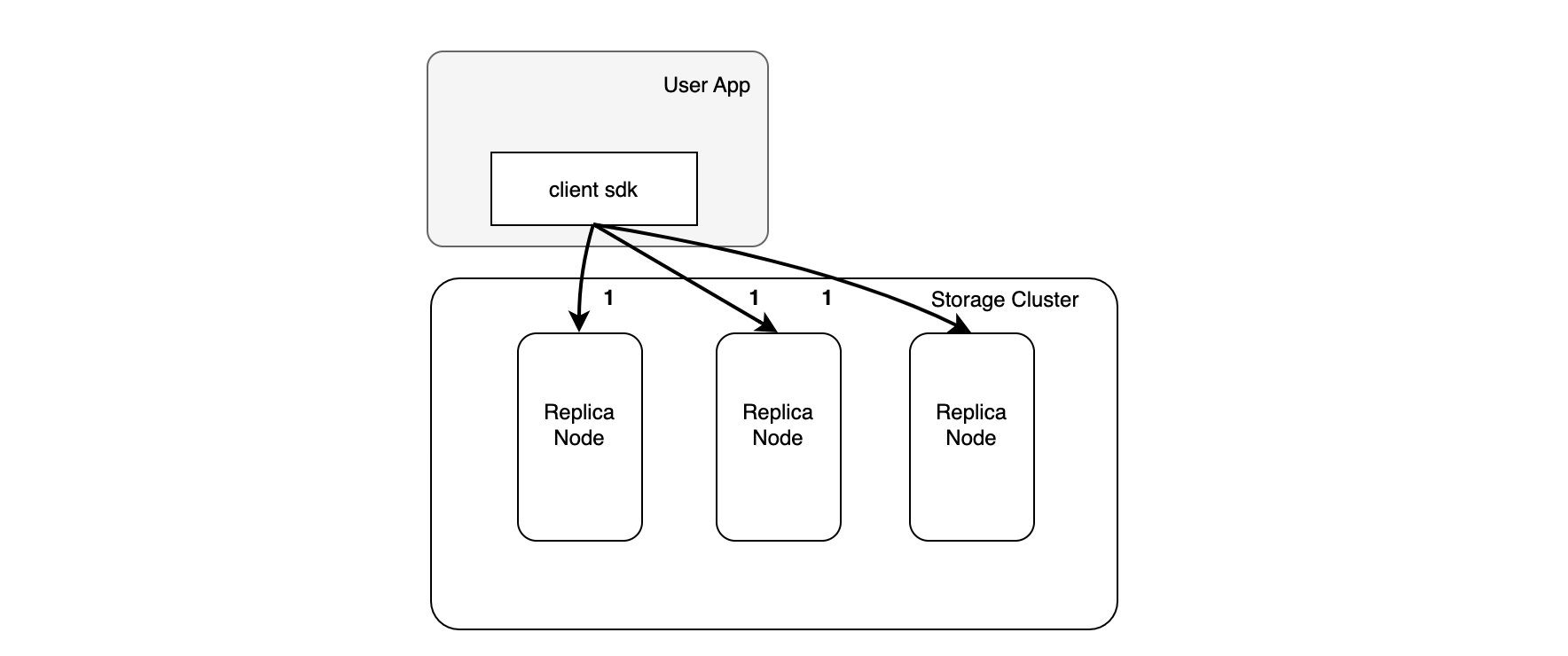
优势:复制时延低
少了 main 节点一跳的网络延迟,性能较好。
劣势:SDK 逻辑较重
主要是考虑用户更新 SDK 的成本,以及对 QoS 的控制力。
劣势:带宽放大
在用户到存储集群带宽放大了副本数倍数。
3.4 链路:Proxy 网关 or Client SDK
无论使用哪一种复制方式,系统设计者需要决定,是集成在用户 sdk 中,还是自己的网关(Proxy)代为执行。
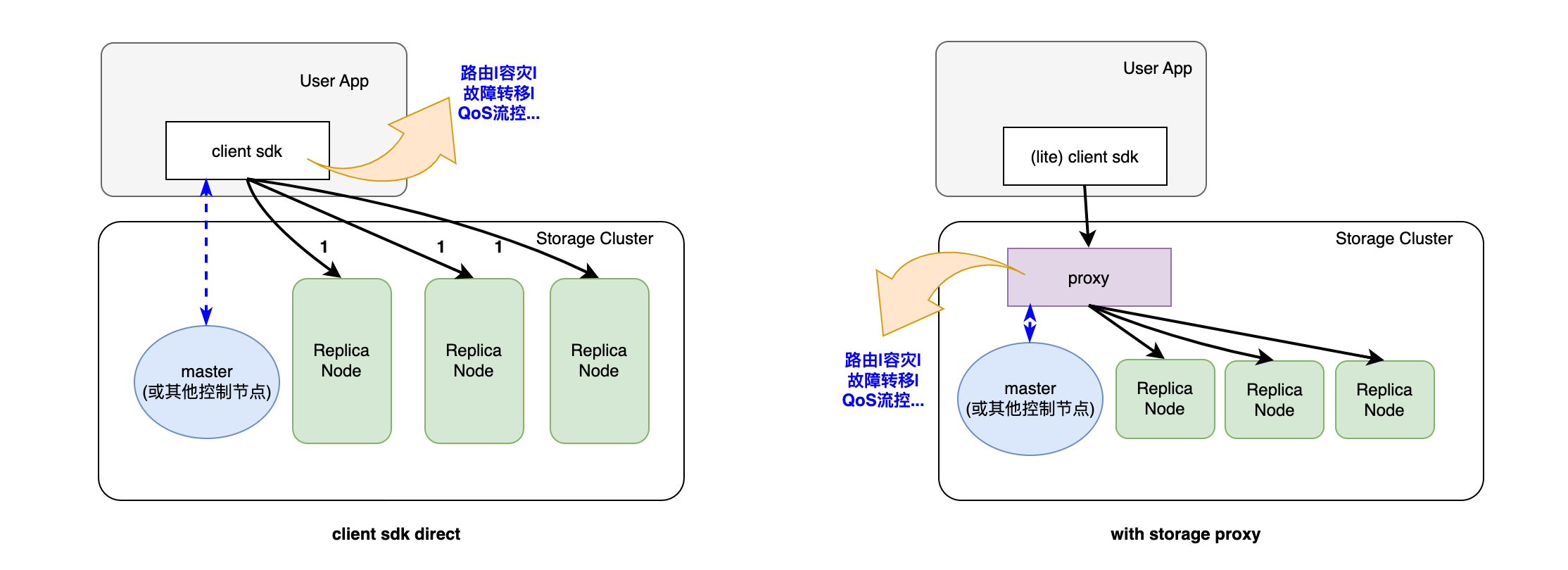
复制逻辑看似简单,但工业可用的存储产品中,除了需要和集群管理节点、元数据节点(比如 master 节点)交互,还要详细考虑容灾时刻的可用性保障。需要决定这些逻辑都需要考虑具体放在 client sdk 还是 proxy 中。
这种做法的一个思想是将用户读写请求的控制权稍微收敛在自己系统的模块中。控制权较强,我们就能更好地进行 QoS 控制。
优势: 能更好地进行 QoS 控制
考虑一个 EC(4,2) 类型读取,如果发现用户数据所在的分片无响应,主节点可以根据动态的全局策略(超时时间、全局的设备负载、动态限流等等)去进行修复读。相比于“客户端星形复制”,显然控制力更强。
限制因素
限制此类模式,转而使用重量级 client sdk 的考虑因素如下:
- 存储集群不想多做一层网关,保持设计简洁
- 用户 SDK 能接受重量级设计,以节省 Proxy 的资源
- 用户 IO 类型,如果是客户端强状态类型(比如流文件写入),则 IO 逻辑几乎只能放置在 client sdk 中
3.5 一致性:全一致性写
存储产品中比较多见的,还是全一致性的写,要求每个副本都写入成功才能返回用户成功。
此处涉及到的一个重要问题,是遇到故障了怎么办?要不要修复?
一种处理方式:令用户请求立即切换其他复制组写入。此处不一致是悬而未决的,系统可以自己决定异步修复,或者直接不予处理。
原则就是:
- 给用户返回成功的部分:存储系统必须保证此部分数据的安全性。
- 悬而未决的部分,存储系统自行决定。
全一致性写的好处是大大简化了副本的复制流程,不需要多数派写后续的补全和数据纠正。缺点是复制组牺牲了可用性。实际设计中,一定令复制组的数量足够多,以保障客户请求能切换写入。
3.6 一致性:多数派写
即数据复制到超过总人数一半以上即可认为写入成功。复制组自身具备故障转移后的修复。
基于 Raft 共识算法实现的写,可以认为是多数派写,由共识算法和合理的 FSM 状态机设计保证数据的一致性。
多数派写最大的好处就是系统中复制组可用性高。也因而总数量可以是有限的,简化了控制元数据节点的设计。
数据修复相对复杂一些,尤其是支持覆盖写语义时,需要确定顺序,不可避免地依赖 log 等技术手段,造成写 io 放大。严格定序也显示了并发度,吞吐受限。
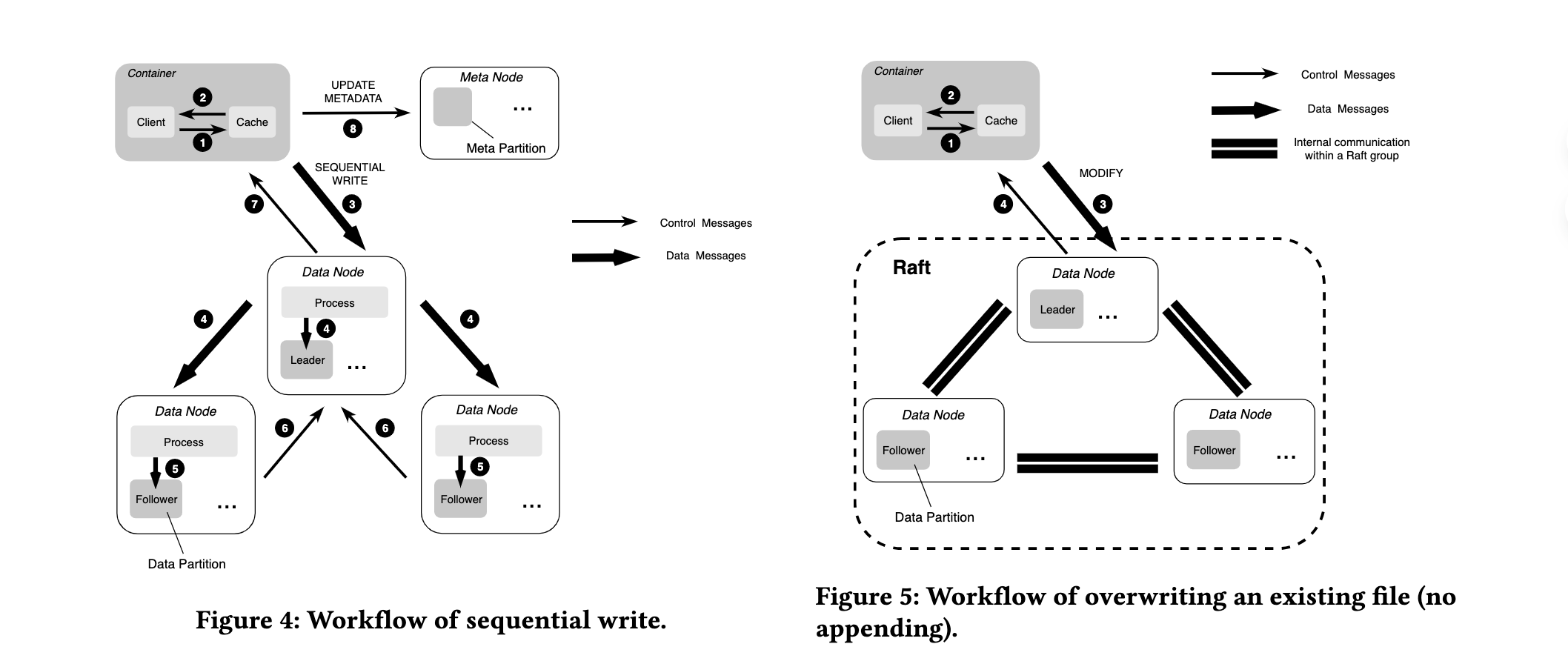
这些一致性手段可以组合使用。在 CubeFS 中,追加写使用了全一致性写,覆盖写使用 Raft 共识多数派写,如下图所示。
3.7 一致性:任意数量写
类似于 Dynamo,采用 Quorum 机制来在可用性与一致性之间找到平衡,即满足 W+R>N。其中 N 表示数据的副本数,W 表示写操作需要的最小确认节点数,R
表示读操作需要的最小确认节点数。
只要写成功需要的副本数与读成功需要的副本数之和大于副本总数,就能保证最终一致性。
此手段限制最为宽松,用户可以根据需要自由选择。但这种方式每次读需要访问多个节点。系统实现起来,还是需要修正不一致节点的数据。
4 小结
| 类别 | 具体类型 | 核心逻辑 | 核心优势 | 核心劣势 |
|---|---|---|---|---|
| 复制链路 | 主节点并行复制 | 主节点接收后,并行发往其他节点 | 省客户端流量,轻量SDK | 主节点负载高,时延看最慢节点 |
| 主节点链式复制 | 数据按节点次序接力复制 | 一致性易保障,带宽均匀 | 时延高(节点耗时累加) | |
| 客户端星形复制 | 客户端直接发所有节点 | 时延低(少主节点跳转) | SDK重,带宽放大(倍于副本数) | |
| Proxy/Client SDK | 复制逻辑集成于网关或SDK | 易做QoS控制,适配容灾 | 网关加层级,SDK适配复杂 | |
| 一致性模型 | 全一致性写 | 所有副本写成功才返回 | 流程简单,无后续纠正 | 可用性低,需多复制组 |
| 多数派写 | 超半数副本写成功即返回(如Raft) | 可用性高,简化元数据设计 | 修复复杂,吞吐受限 | |
| 任意数量写 | 按Quorum机制(W+R>N)平衡 | 灵活,保障最终一致性 | 读需多节点,需修正不一致 |
本文总结了前往分布式存储中登之路必知必会的一些复制手段。笔者认为,这些手段没有一个最狠最强,根据需求合理使用即可。
下篇文章我们将讨论分布式存储系统的分区与路由。
5 继续阅读
- 几乎人人都有的书 《设计数据密集型应用》3 的 “复制”章节详细描述了更全面的复制手段。 (不过根据作者实际体验,若不带着实际的问题,很难体会到一些手段的动机、思想和目的。)



