本文是笔者设计流量复制方案时的一次调研。调研了7层流量复制组件 GoReplay,并 review 了其中一些Plugin的具体实现。
Table of Contents
1 背景
本文是针对流量复制需求进行的技术调研,包含方案、开源组件和一些想到的细节。
流量复制一般是指,在生产环境中引出一部分真实请求,通过过滤、修改导向被测试环境,来验证测试环境的压力抗性和数据正确性。常见的场景是压力测试、灰度测试等。
2 方案
本次调研的方案是旁路复制方案,即不通过耦合业务逻辑,直接在网络协议栈层进行流量的监听和复制。
根据需求判断,这样做的好处是业务无感,不会干涉正常的业务逻辑,通过牺牲一些性能和定制潜力,快速实现流量复制。
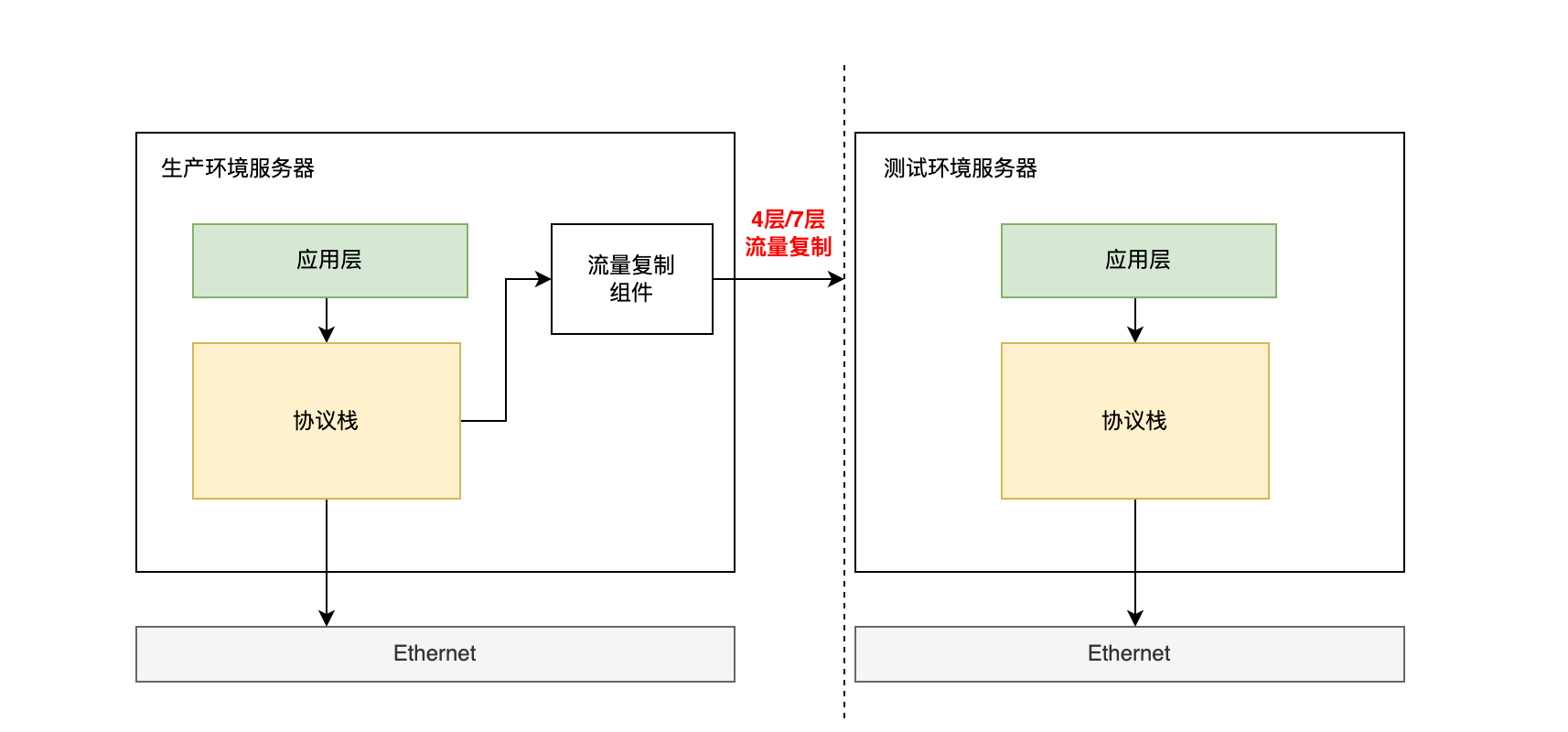
3 组件
3.1 TCPCopy
https://github.com/session-replay-tools/tcpcopy/
| 实现语言 | C |
|---|---|
| stars | 4.1K |
| 流量复制 | 4层 |
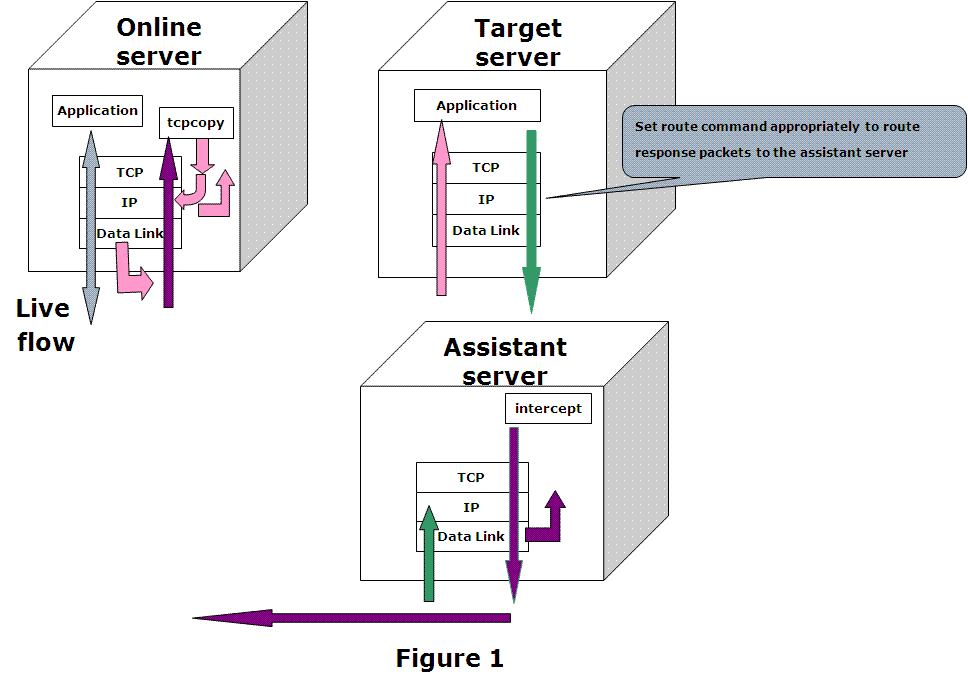
TCPCopy复制的是4层TCP流量,使用 raw socket 方式捕获数据包,并处理发送的目标服务器。
TCPCopy需要部署一个辅助服务器 intercept 用于接收目标服务器的响应数据包。
3.2 GoReplay
https://github.com/buger/goreplay
| 实现语言 | Go |
|---|---|
| stars | 15K |
| 流量复制 | 7层 |
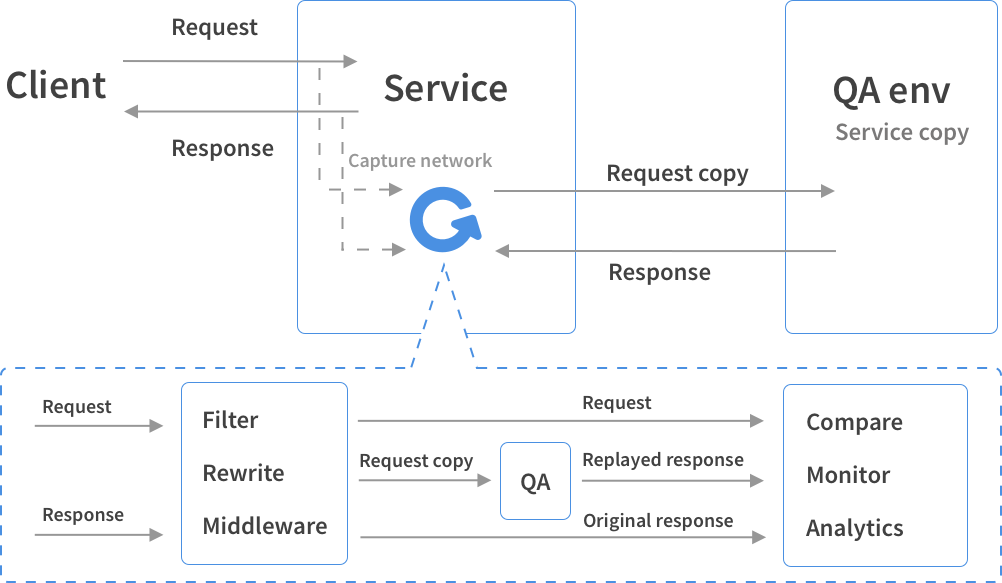
GoReplay使用Go语言开发,捕获的是第7层HTTP流量。GoReplay同样是旁路复制,将HTTP请求转发到目标地址,不需要更改生产环境的基础架构。
相比TCPCopy, GoReplay的部署更加简单一些,使用go的二进制可执行程序,直接指定参数转发即可。不需要辅助服务器处理回包。
3.3 4层or 7层?
4层流量复制
- 对链路的模拟更加完整,比如重现TCP包不完整等链路情况
- 除了复制HTTP请求外,也可以适配更多基于TCP应用(如MySQL、Kafka等)
- 因不涉及7层应用层的解析,失去了应用层的过滤功能
7层流量复制(HTTP)
- GoReplay部署更加简便
- 可以根据请求内容进行过滤和限流,甚至定制自己的中间件处理
结合背景和本文实际需求,最终选择了GoReplay这一组件。
4 Goreplay
GoReplay项目自身的 wiki 对使用方法写得比较详细。
这里是主要结合源代码对流量复制的原理和实际使用的细节进行探究。
注:笔者阅读的分支是 release-1.3,版本 5532132e2a11189c0a1f13ea5d1a991f68b48202,追踪时间为2022年06月27日。
4.1 管道Plugin设计
GoReplay中每个input和ouput组件都是以Plugin方式实现,符合Unix的哲学,管道的输入和输出。
// plugins.go
// PluginReader is an interface for input plugins
type PluginReader interface {PluginRead() (msg *Message, err error)
}
// PluginWriter is an interface for output plugins
type PluginWriter interface {PluginWrite(msg *Message) (n int, err error)
}
// PluginReadWriter is an interface for plugins that support reading and writing
type PluginReadWriter interface {
PluginReader
PluginWriter
}
因此我们在 wiki 中可以看到比较优雅的 --input 和 --output 选项。
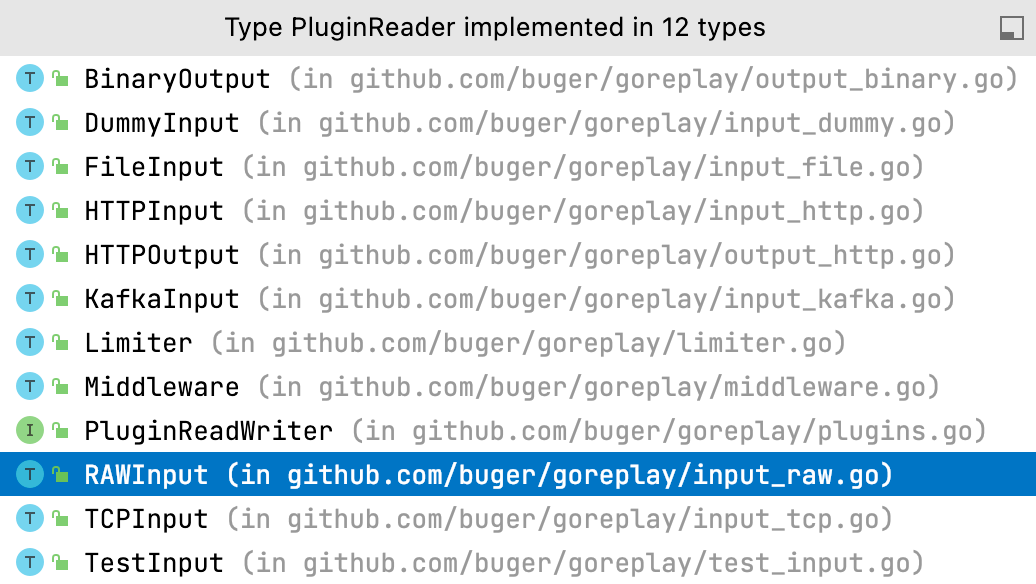
我们使用的默认 libpcap 引擎,就是初始化在 pluginReader 的实现 RAWInput 中。
4.2 流量捕获
默认使用的是 libpcap 引擎,可以使用 raw_socket 引擎作为替代。
sudo gor --input-raw :80 --input-raw-engine "raw_socket" --output-http "http://staging.com"
我们重点看一下 libpcap 流量捕获Plugin相关的流程。
(我自己也顺便梳理了一遍实现,学习一下常见模式。 )
libpcap
libpcap 是用于数据包捕获的函数库,调试利器 tcpdump 就是基于该库。
libpcap 可以使用经典的bpf技术对数据包进行捕获和过滤。比如在我们使用 tcpdump 过滤某个端口时,会使用bpf在内核中进行过滤。
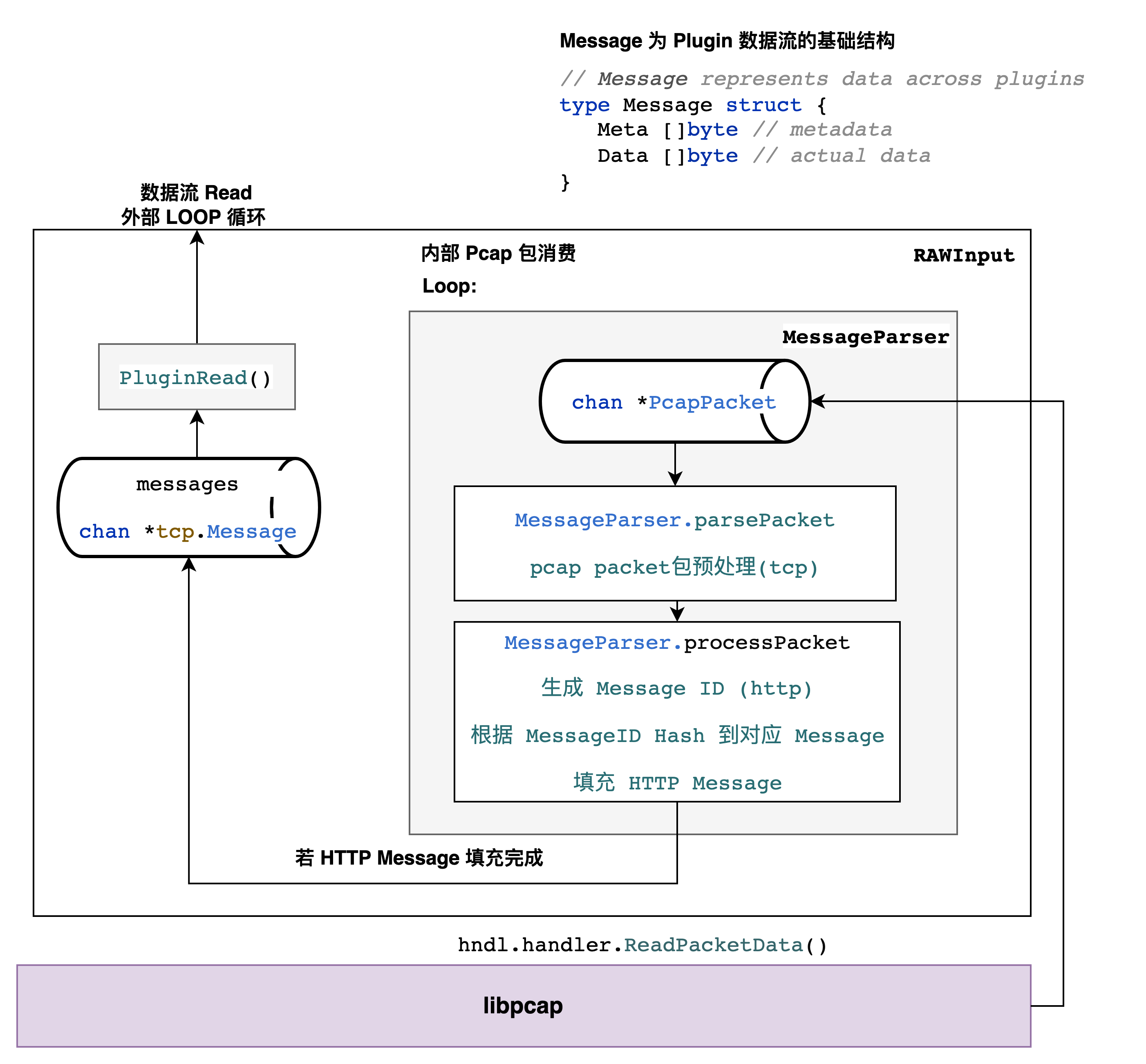
RAWInput tcp数据包消费
通过 PluginRead 进行循环,在 chan RawInput.listener.Messages() 这个管道中等待并弹出 Message,流程如图。
HTTP包拼接
相同的HTTP数据包享有相同的MessageID,生成规则如下
func (pckt *Packet) MessageID() uint64 {
if pckt.messageID == 0 {
// All packets in the same message will share the same ID
pckt.messageID = uint64(pckt.SrcPort)<<48 | uint64(pckt.DstPort)<<32 |
(uint64(ip2int(pckt.SrcIP)) + uint64(ip2int(pckt.DstIP)) + uint64(pckt.Ack))
}
return pckt.messageID
}
MessageID生成规则比较巧妙,详情见 ISSUE #916
4.3 HTTPS相关
GoReplay虽然提供了 --input-tcp-secure 选项用于设置证书和key,但该选项并不是HTTPS流量捕获。其是为了分布式流量转发设计的tcp tls加密。参看 issue #529。
一般直接捕获HTTPS的比较麻烦的,因为原理上是必须有服务端的证书和秘钥才能解密流量。
用的比较多的方式是在接入层/网关的TLS终止之后,再捕获HTTP流量。
4.4 回包处理
作为在生产环境的旁路,我们当然不希望测试服务器的响应对生产环境造成影响。
回包处理,我们可以看一下HTTP Client的实现。
// output_http.go
func (o *HTTPOutput) sendRequest(client *HTTPClient, msg *Message) {
// ......
resp, err := client.Send(msg.Data)
// ......
if o.config.TrackResponses {o.responses <- &response{resp, uuid, start.UnixNano(), stop.UnixNano()- start.UnixNano()}
}
if o.elasticSearch != nil {o.elasticSearch.ResponseAnalyze(msg.Data, resp, start, stop)
}
}
当然是符合我们的预期的。当需要跟踪Responses时或者向ES记录数据时,resp才会被处理。
4.5 定制:中间件
由于遵循了数据流in/out的设计理念, 可以在数据处理过程中自己定制中间件,实现诸如:
- 修改Header/请求内容
- 新增/修改token
等需要灵活定制功能。
具体可以参考wiki。其提供了go, js等语言的中间件实例。
4.6 其余功能
- 限流
- 过滤(Header等)
- Real-IP写入Header
- HTTP方法和正则表达式过滤HTTP请求
- Url Rewrite
对于更高级的用法
- 生产机器仅转发流量,拼接、过滤等操作交给其余分布式机器
- 写入ES/Kafka
5 小结
本文是笔者设计流量复制方案时的一次调研。调研了7层流量复制组件GoReplay的使用方法和特性,并review了其中一些Plugin的具体实现。
使用GoReplay进行流量复制适合在一些需要快速验证的场景。其部署简单、结构容易理解。
但是若需要公司平台级别的流量复制服务多个团队,在大型集群中操作流量,仍然需要进行建设和定制。




不知道说啥,开心快乐每一天吧!