RocksDB 可靠性和高性能是众所周知的。将其部署在分布式文件系统也是一种趋势,体现了存算分离的思路。
本文先讨论官方的分布式改造论文 Disaggregating RocksDB: A Production Experience,随后记录一些自己的想法。

Table of Contents
1 论文: Disaggregating RocksDB
@article{dong2023disaggregating,
title={Disaggregating rocksdb: A production experience},
author={Dong, Siying and P, Shiva Shankar and Pan, Satadru and Ananthabhotla, Anand and Ekambaram, Dhanabal and Sharma, Abhinav and Dayal, Shobhit and Parikh, Nishant Vinaybhai and Jin, Yanqin and Kim, Albert and others},
journal={Proceedings of the ACM on Management of Data},
volume={1},
number={2},
pages={1--24},
year={2023},
publisher={ACM New York, NY, USA}
}1.1 论文做了什么?
论文将原本部署在本地 SSD 的 RocksDB 部署在 Meta 内部的分布式文件系统 Tectonic 上,发展了分布式 RocksDB。论文讨论了分布式改造后的优势和代价,并研究了 RocksDB 在分布式存储环境中的挑战和改进措施。
1.2 工程背景和动机
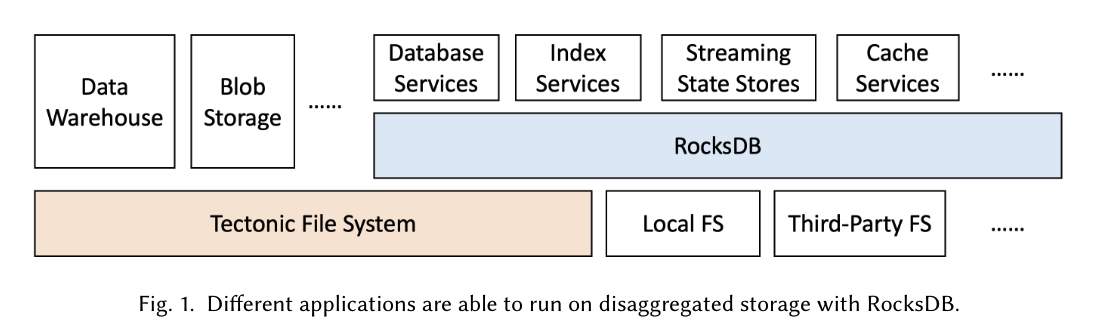
RocksDB 将下层存储使用 env 接口进行解耦。这意味着可以适配不同的本地或分布式文件系统。而且,LSM-Tree 的数据结构非常适合分布式存储。
RocksDB 的使用现状:RocksDB 在 Meta 内部有广泛的应用。LSM-tree 利用得较好。如果能适配 RocksDB on Tectonic,自然能解耦业务使用和底层存储产品,提供更好的产品体验和容量管理成本。这其实也是工程成本的考量。
分布式存储的收益:使用分布式存储代替每个集群单机部署的 SSD,能够更好地整合存储资源。单独部署的一个一个用户集群,要么需要留一些磁盘余量、要么 CPU 和 SSD 资源不容易匹配。将有状态的 SSD 像资源池一样托管给分布式存储,有利于资源使用率和服务管理成本。
服务启动调度简化:有状态数据,容灾和备份交给了底层分布式存储。业务节点仅需要调度就可以快速拉起。
1.3 工程挑战
性能下降:将本地 SSD 更换成分布式存储后,性能是下降的。业务需要考虑能否接受这个代价。
冗余开销:底层的文件系统一般会对数据做多副本的冗余,不同的文件可以选择不同的冗余度。
IO fence:发生故障转移时,需要设计机制保证多写入者的 io fencing。需要保证只有一个节点能够修改数据。
RocksDB 的 远程IO:RocksDB 一开始是为本地 IO 设计的。遇到一些错误将视为损坏,令数据库进入只读或致命错误状态。但是对于远程 IO,需要容忍一定分布式文件系统的错误,制定合适的错误处理策略。
1.4 RocksDB 的 IO 需求
RocksDB 被设计为追加写模式,需要分布式文件系统支持以下模式
- 按名称路由到文件
- 文件支持追加写
- 文件支持以偏移量 offset 方式读
- 文件支持目录语义(或桶的语义)
论文也给出了需要实现的接口:
https://github.com/facebook/rocksdb/blob/7.6.fb/include/rocksdb/file_system.h
笔者注:
对分布式存储不了解的读者可以阅读 Meta 分布式存储 Tectonic 论文,简单了解其接口语义和容灾思想即可。其实 Tectonic 也是个追加写的存储系统,两者相性较好。
另外,追加写文件系统是比较受欢迎的,我们见到 BigTable、HBase、Spanner 都是基于追加写文件系统的。
1.5 架构概览
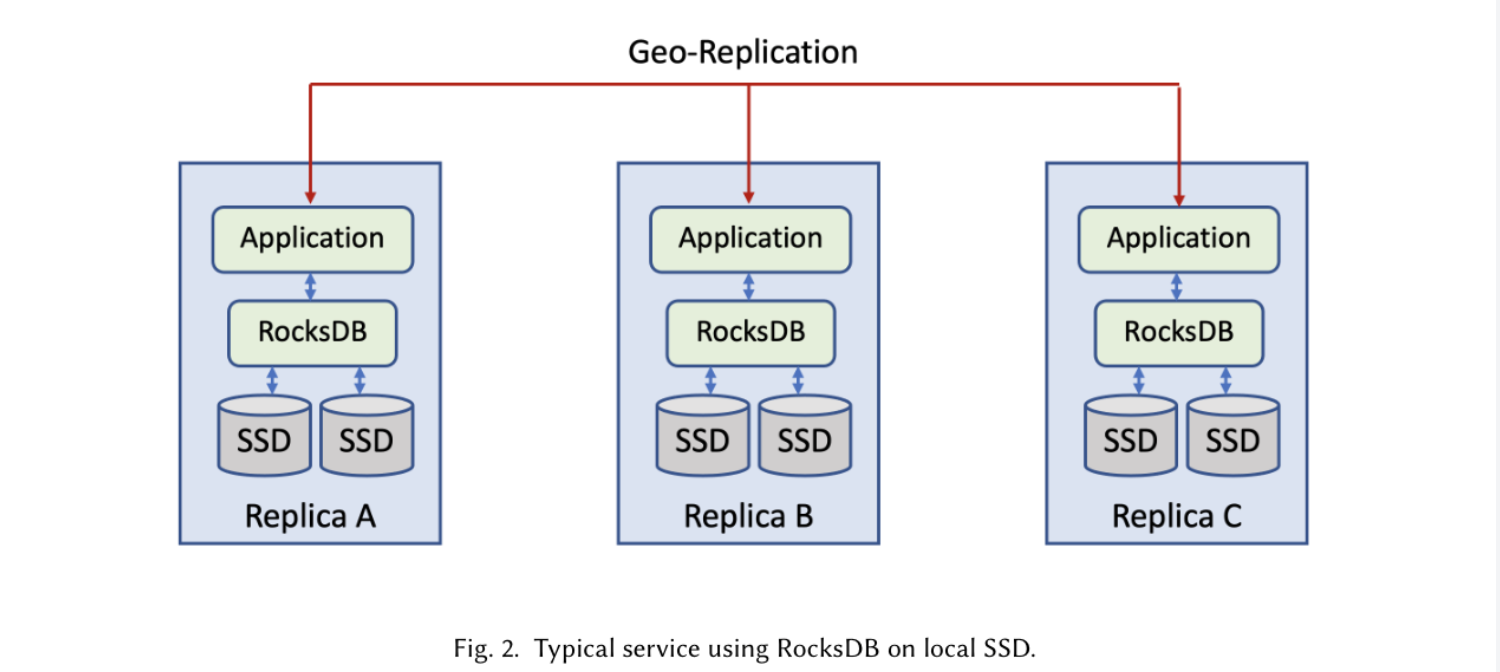
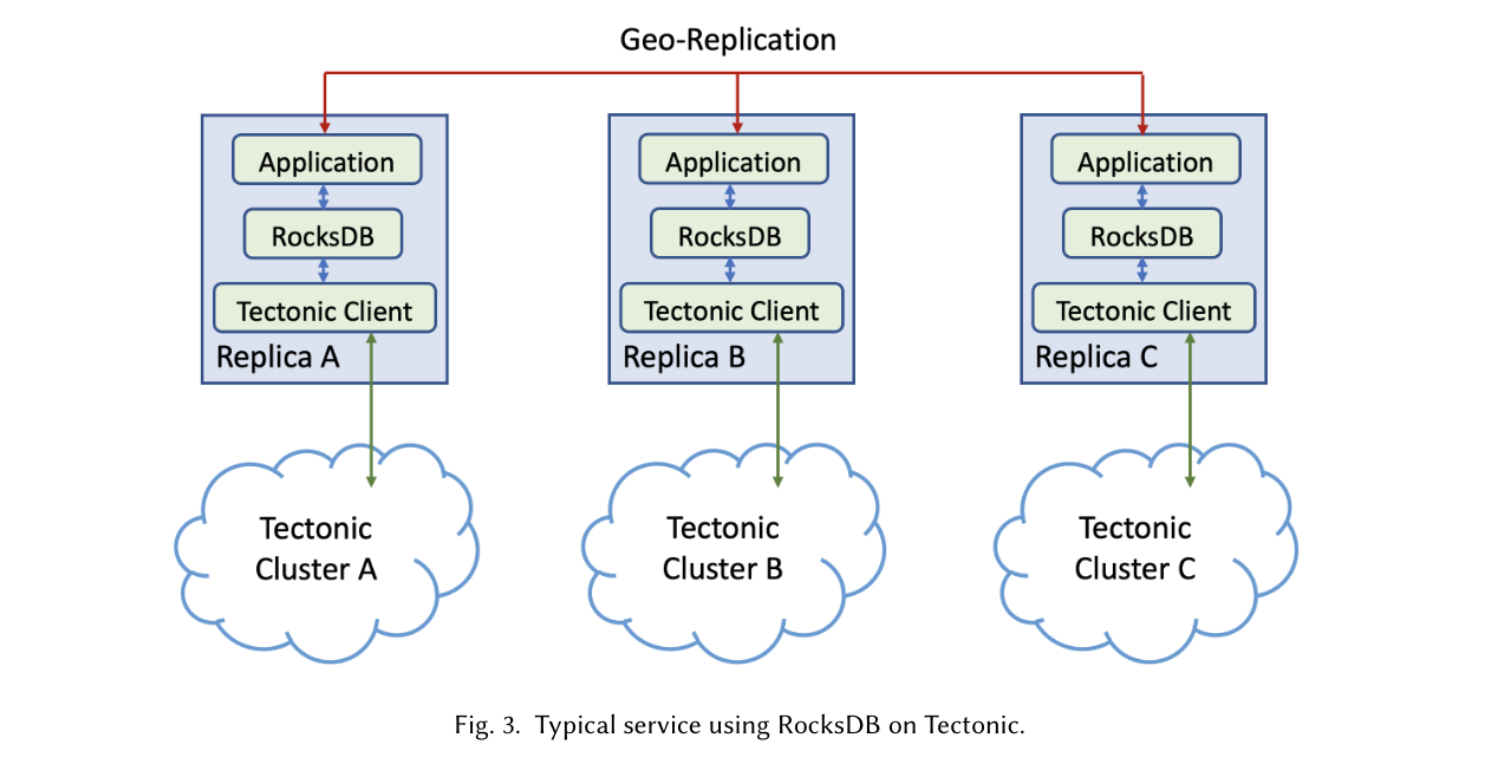
业务原本的产品形态如图2。实际上是改在 3 地区副本复制的模式中,替换原来的裸 SSD 为 Tectonic Client,将数据持久化在下层分布式存储。
笔者注:底层分布式存储,一般会有副本冗余以应对磁盘故障等场景。副本数是大于 1 的(比如双副本是 2,EC4+2 是 1.5)。单就图中形态而言,改造后数据的整体副本数反而升高的,从 3 倍提升到 3×(Tectonic副本数)。不过有一个收益,磁盘的故障修复在单个 Geo 中就可以完成了。我们不必过度纠结这个形态,关注单 Geo 中的 RocksDB 改造即可。
笔者注:在分布式存储上,上层是否有必要使用共识算法组成的分布式集群?
1.6 措施:性能优化
1.6.1 尾部延迟优化
为了消除分布式文件系统的尾部延迟,更准确地说,是掩盖。
- 主动多次请求 原文叫做主动重建。遇到某个节点速度较慢时,再次发出请求,取两者最先返回的相应。但是要注意,如 EC 这种数据,可能会导致重建,导致集群压力更大。这里要合理设置阈值。
- 追加写切换 使用 Quorum/Subnet 的写成功即认为成功。或遇到延迟时结束该节点组的追加写,记录元数据长度后,立刻尝试选择新的节点进行追加写。
- 提前获取写入许可 对大型写入的优化,分类许可获取和数据传输。第一阶段,存储节点通过自己的资源情况,决定是否授予 RocksDB 写入大块数据。第二阶段,RocksDB 选择最早相应的节点集合进行写入。
1.6.2 元数据缓存
基于一个前提:RocksDB 独占底层目录。因此可以缓存元数据,也可以保持一致性。
1.6.3 本地 SSD 缓存
使用本地机器的 SSD 作为读密集型的 cache。这实际上就是 RocksDB 的 SecondaryCache,基于 Cachelib。
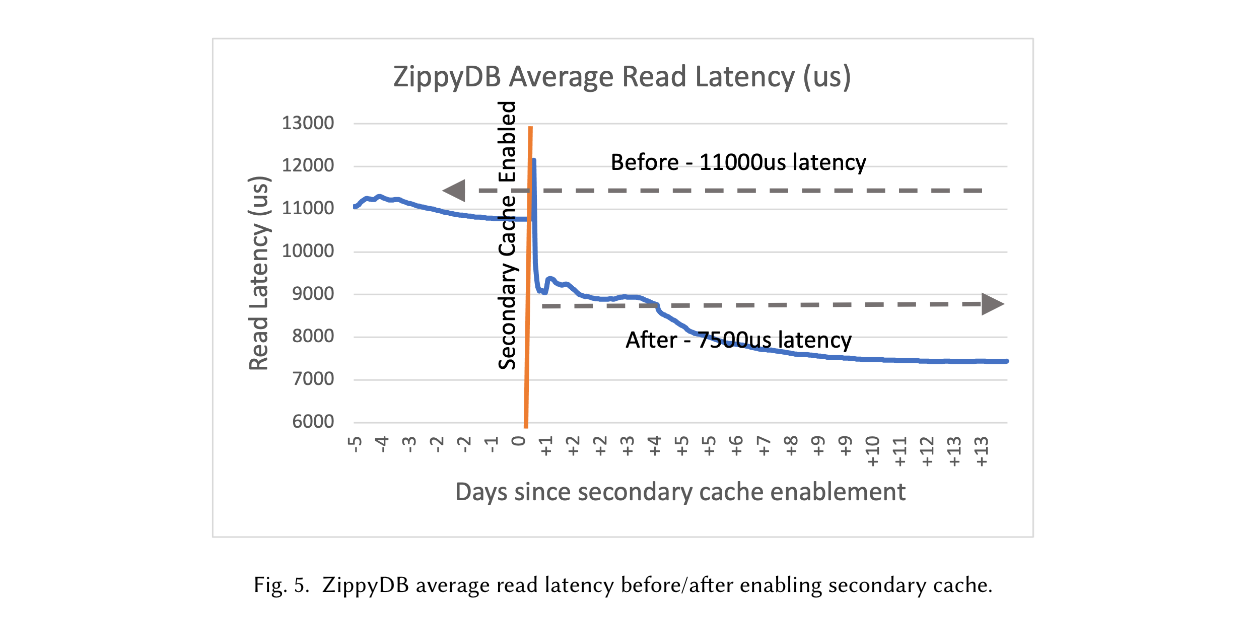
上图可以看到,二级缓存在读密集型应用中收益很大。
1.6.4 IO 参数调节
认为分布式文件系统的特征像 HDD。相比于本地 SSD:
- 读写延迟上升
- 更喜欢大 IO
因此倾向于 HDD 的模式配置 RocksDB IO 参数。以下是文章提出的一些做法:
- 压缩 IO: RocksDB 的压缩读写IO是顺序的,通常将压缩读取大小配置为 4MB 或 8MB,压缩写入缓冲大小配置为64MB或更大。代价是 IO 延迟可能增加
- 使用动态预读大小:尤其是 MultiGet 方法和迭代器可能导致预读流量增加。这里使用历史数据统计设置预读大小。
- 启用并行 IO:虽然每次 IO 的延迟有所上升,加起来有叠加效应。读 SST 文件时并行多个块读取。
- 压缩调优:控制 SST 大小,过小会导致文件数量增多。论文的值是 <64MiB 才会观测到性能下降。
1.7 措施:低开销的冗余
| 总结如下: | 文件类型 | 编码方式/方案 | 核心选择理由 | 额外说明 |
|---|---|---|---|---|
| SST 文件 | [12,8] 纠删码(8个数据块+4个校验块) | 1. 空间与带宽效率高:仅产生1.5倍存储/带宽开销,远低于副本模式(如R3的3倍开销),适配SST文件占存储主导、对成本敏感的特点; 2. 耐久性达标:可匹配Meta 6-12个故障域的部署架构,满足高耐久性SLA(服务等级协议)要求。 |
无对齐或填充需求,适合SST文件一次性写入、后续只读的特性。 | |
| WAL 及其他日志文件(默认场景) | 5副本(R5)编码 | 1. 低尾部延迟:副本编码无需纠删码的计算开销,对小尺寸(子块级)追加写入友好,可满足WAL对写入延迟的严格要求; 2. 无格式限制:无需像纠删码那样要求写入大小对齐或填充,适配WAL高频小批量追加的场景; 3. 可用性充足:基于主机故障概率模型,R5可满足Meta对日志文件的高可用性需求。 |
适用于日志更新频率中等、对延迟敏感的场景。 | |
| WAL 及其他日志文件(高更新场景) | 条带化 [12,8] 纠删码(8KB条带) | 1. 降低带宽开销:将R5副本的5倍网络开销降至1.5倍,解决高更新场景下副本模式带宽成本过高的问题; 2. 适配顺序读特性:日志文件以顺序读为主,条纹化设计虽可能增加随机读复杂度,但对实际访问模式影响极小; 3. 兼容性优化:通过预定义条纹大小(如8KB)和零填充处理非对齐数据,规避纠删码对写入大小的限制。 |
需在客户端缓存条纹数据,待累积完整条纹后再编码写入,平衡开销与延迟。 |
笔者注:
值得指出的是,特意为 append 日志做了 EC 条带类型的 append 语义。这部分需要文件系统支持。
1.8 措施:多写入者的数据完整性保护(IO Fencing)
严格约定了只有一个 RocksDB 实例能够读写同一个 RocksDB 目录。使用了一种叫做合作式 io fencing 策略。
这部分需要分布式文件系统 Tectonic 提供,使用递增的 token 决定目录的可写者。
- 如果新写入者令牌更新,更新目录令牌
- 防止旧令牌持有者任何的更新操作(文件创建、重命名、删除)
- 遍历目录下所有可修改的文件
a. 更新令牌到文件元数据上
b. 去存储节点封存文件尾部的可写块(此时如果有过期 token 节点尝试写入,则该节点可获知自己的 token 过期)
在这期间,如果发现更高的 token,则将这次 io 隔离视为失败,不再尝试打开 RocksDB 并修改。
笔者注:看起来没有使用心跳 + 超时 + token 的模式。这其实简化了系统复杂度和负载。
1.9 措施:适配远程 IO
其实就是本地 IO 变成分布式网络 IO 后的策略变化。
- 超时时间:用户前台读写和压缩分别设置不同的超时
- 错误处理:分布式系统的错误更加常见,有些是可重试恢复的。根据底层返回的可重试性、影响范围决定处理策略。
1.10 更多工作和挑战
文章撰写时社区在做的一些工作:
- 从节点:次级实例,从节点,提供从读和快速故障恢复。
- 远程压缩:其他实例执行压缩,避免争抢 CPU 影响主实例的服务质量。
1.11 一些性能指标
所有除了 Tectonic ENV 组件外的模块和改进都已经合入 RocksDB 了。
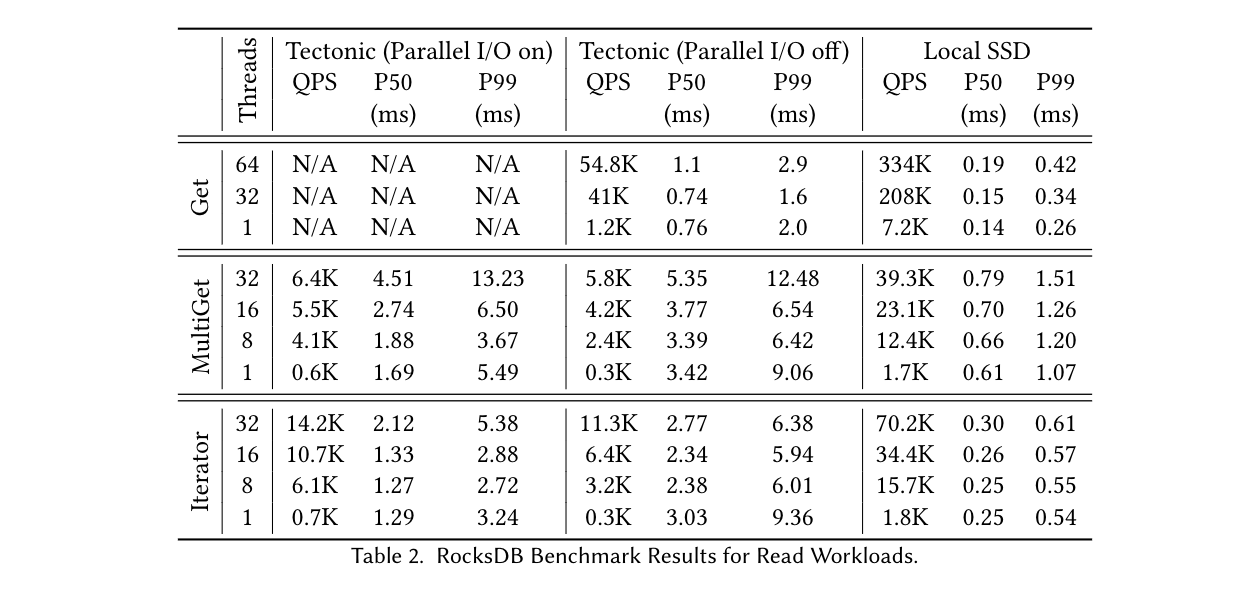
原文给出了基于 ZippyDB 的 RocksDB 性能对比和用户端到端性能对比,可以查看原文。这里大概感受下不同并发度下 Get 操作的延迟数量级。
2 一些思考
结合实际的工作经历思考这个模式。
2.1 存算分离的收益
追求存算分离的系统结构一般见到如下动机:
更好的资源整合(池化)
无论是公司内部服务还是外部服务,涉及到大规模部署和多集群时,用户的读写模型和对时延的要求可能完全不同的。这导致 CPU/内存/网络/存储 无法最优匹配。
在整个集群的视角,就是会有很多资源因不匹配导致浪费了。所以考虑将计算资源和存储资源解构,分别池化。
解耦应用层直接管理存储
这也是一个重要的好处。应用层(数据库、KV 等产品)期望将存储解耦交付给底层存储团队,自己专心做好应用层的特有逻辑和故障转移。在很多大型公司更符合团队的划分和效率最大化。
构建一个分布式存储产品,如果从最底层的 disk io,再到共识算法设计、数据分区和复制机制做起,再构建上层应用(数据库组件、流处理组件),是一项很大的工程。
说白了,上层产品团队可能根本不想耗费大部分时间做这些繁琐的分布式 IO 机制,就可以将数据的冗余、复制、IO 托管给底层产品。这会导致自己的产品过于复杂,还可能和存储耦合在一起。
应用层将有状态的存储托管给底层产品,自己便可以向无状态演化。专注于自己产品的逻辑。做好故障转移机制,天生容易实现极度方便的扩缩容。
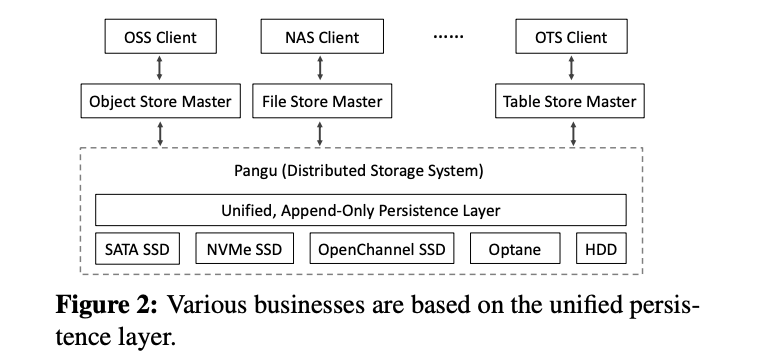
图中是 Pangu 存储底座的产品形态概览,目的是构建一个通用的存储底座,上层团队如 OSS,NAS 等分别构建自己的产品。
云存储成本
S3 对象存储也是一种事实标准,各个云厂商和公司内部一般都有团队提供,且价格相较于块存储较为划算。这也是很多产品直接基于 S3 存储去构建的原因。
2.2 append-only 追加写
RocksDB 的数据结构 (LSM-tree) 不断生成 append-only 的 sst file,看起来也很适合基于 Tectonic 的分布式文件系统上 (毕竟 Tectonic 也是 append-only)。
笔者认为追加写文件系统是比较受欢迎的,见到 BigTable、HBase、Spanner 都是基于追加写文件系统的。追加写实际上牺牲了随机写的语义,换取了分布式系统设计和容灾机制的简化。也许我们会开一篇新的的专题和读者一起讨论。
2.3 单机引擎适配分布式系统的挑战
远程 IO 适配
RocksDB 虽然针对远程文件系统做了优化,但开发者在针对自己的 FS 适配时,还是要对其前台 IO 流程和 Compaction 流程充分理解和跟踪,并做好压测和故障场景测试。
高可用和容灾设计
容灾和故障转移方面,对于超高可用要求的关键业务,开发者如果只编写 env 层进行适配,笔者认为不容易将高可用和快速故障转移做到极致。
比如写 wal 策略能够和底层 fs client 结合起来,以及能否实现从节点实时升级为主写节点。必要的话可能还是需要自己魔改一个分支出来。
2.4 故障转移怎么做?
直接基于存储层做一个 主-从 实例是一种最容易想到的方案。
一个关键的变量是底层分布式系统能提供多大的读写能力,是否支持大量 RocksDB 实例 (百万) 同时拉起,直接决定了上层的故障恢复策略。
如果读写延迟接近于机械硬盘的 S3 集群,RocksDB 计算节点不可避免需要一层 SSD 作为 wal 和 Compaction 缓存层,利用大 IO 异步同步到存储集群。
也有方案比如论文中的 ZippyDB。仅仅是将 RocksDB 本地 SSD 更换为分布式文件系统,上层仍然保留 raft 共识多节点的所有结构。这样上层系统无需改动,但是牺牲了分布式存储带来的许多优势(冗余度、透明故障迁移等)。这种方案保留了共识算法带来的优点 (以及所有缺点 :-) )。
3 小结
博客总结了 meta 关于 RocksDB 存储计算解耦工程论文,并把笔者的一些观察和思考记录下来。希望能和有经验的读者能够多多交流。




Nice blog here