项目使用 tikv 作为分布式 KV 引擎构建了元数据服务。随着业务增长,P99 延迟急剧升高。在调优 tikv server 收获甚微后,我们把目光转回 tikv-client,结合源码和线上 metrics 分析可能的瓶颈和优化手段。

Table of Contents
1 背景
项目使用 tikv 作为分布式 KV 引擎构建了元数据组件。随着业务增长、tikv store 和 region 数量的迅速上升,我们发现高峰时用户读写的 P99 延迟开始急剧上升,甚至达到秒级。同时读写事务失败率大幅上升,服务质量下降。
服务使用了 tikv-client 作为客户端。最初观察自己服务的资源使用率,发现无论是 cpu、网络都占用不高,因此首先怀疑服务端瓶颈。
同事们随后做了 tikv server 端和 OS 层面的大量调优,包括 grpc 相关、raft 线程控制和 rocksdb 相关设置。发现效果不太理想。当时和社区的一些咨询见[1]。
后续偶然发现,扩容我们自己的服务(即 tikv-client)实例数对系统吞吐延迟都有质的提升,故视线转回 tikv-client。但是有很大的疑惑:为什么看起来资源使用率比较低,但是横向扩容仍然有效?是不是单个 tikv-client 有某种瓶颈(比如锁),导致单实例支撑有限?(现象看起来太像是单实例内有某种全局锁了)。
经过仔细阅读源码和线上 metrics 信息,我们找到了可能导致读写上升的原因,并总结一些自己的经验,共同讨论。
2 tikv、percolator 与 tikv-client txn
2.1 关键前提
tikv 基于 percolator 实现,关于 percolator 官方和社区有很多优秀的文章,我们不再赘述,不过还是要有其中的关键理解:
- tikv 的分布式事务,需要 server 和 client 紧密配合,意味着 tikv-client 有重的事务处理逻辑。[2]
- tikv 事务是 snapshot 级别隔离,除非显式调用 PessimisticLock,最后 2PC 提交的模型是乐观事务模型。[3]
- 一个 "复杂的 txn",本质上是由多个 kv get/put/del/lock 等操作组成。
客户端有较重的事务处理逻辑,我们引用一张 tidb 的示意图说明[4]。
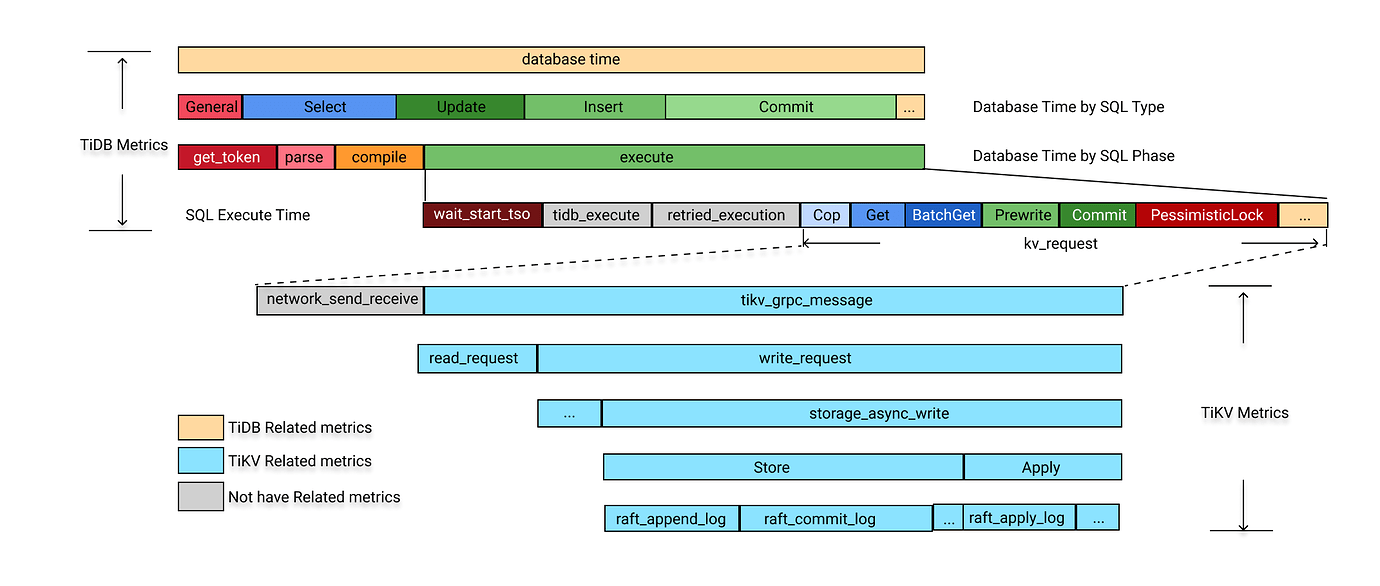
2.2 tikv 基本读写流程
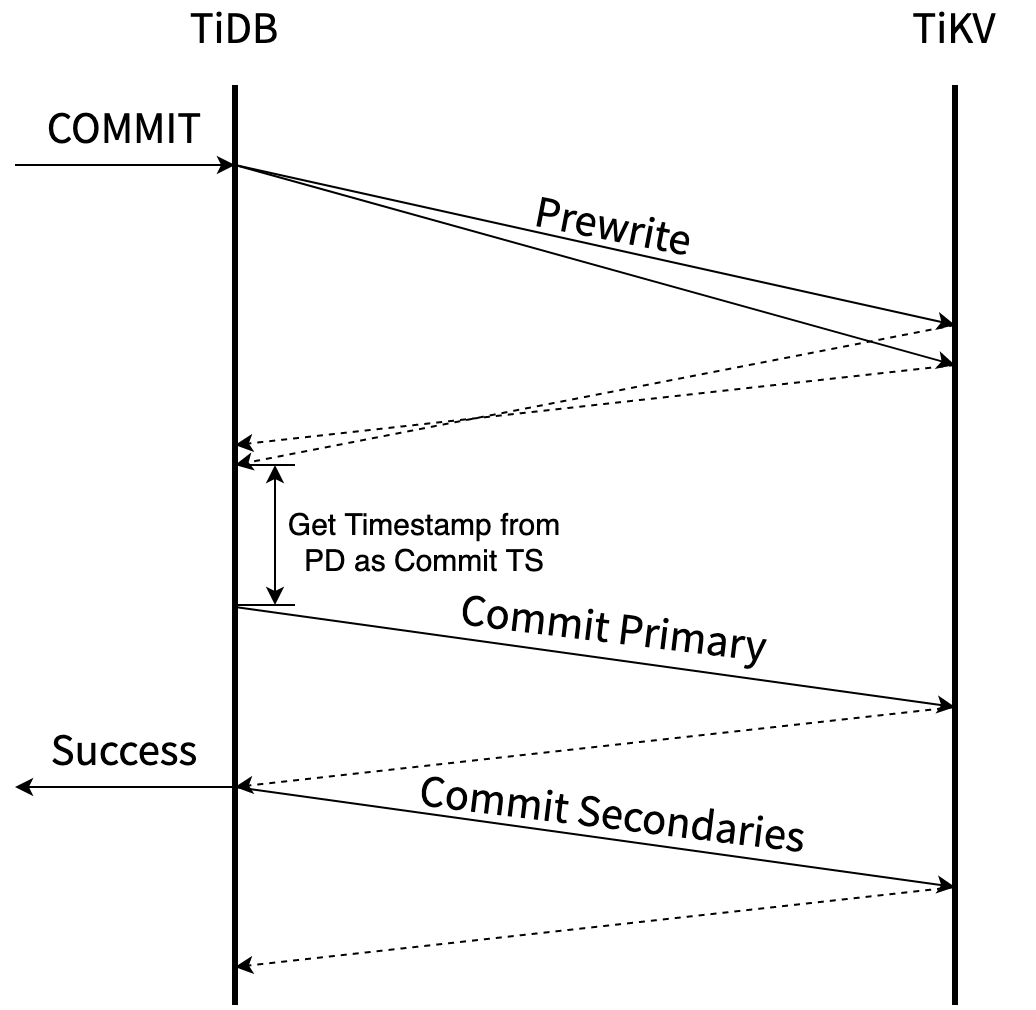
官方文档 [2] 有非常权威的描述,这里我们引用一张表格和流程图 [5],足以让对性能敏感的开发者明确 txn 的关键流程。
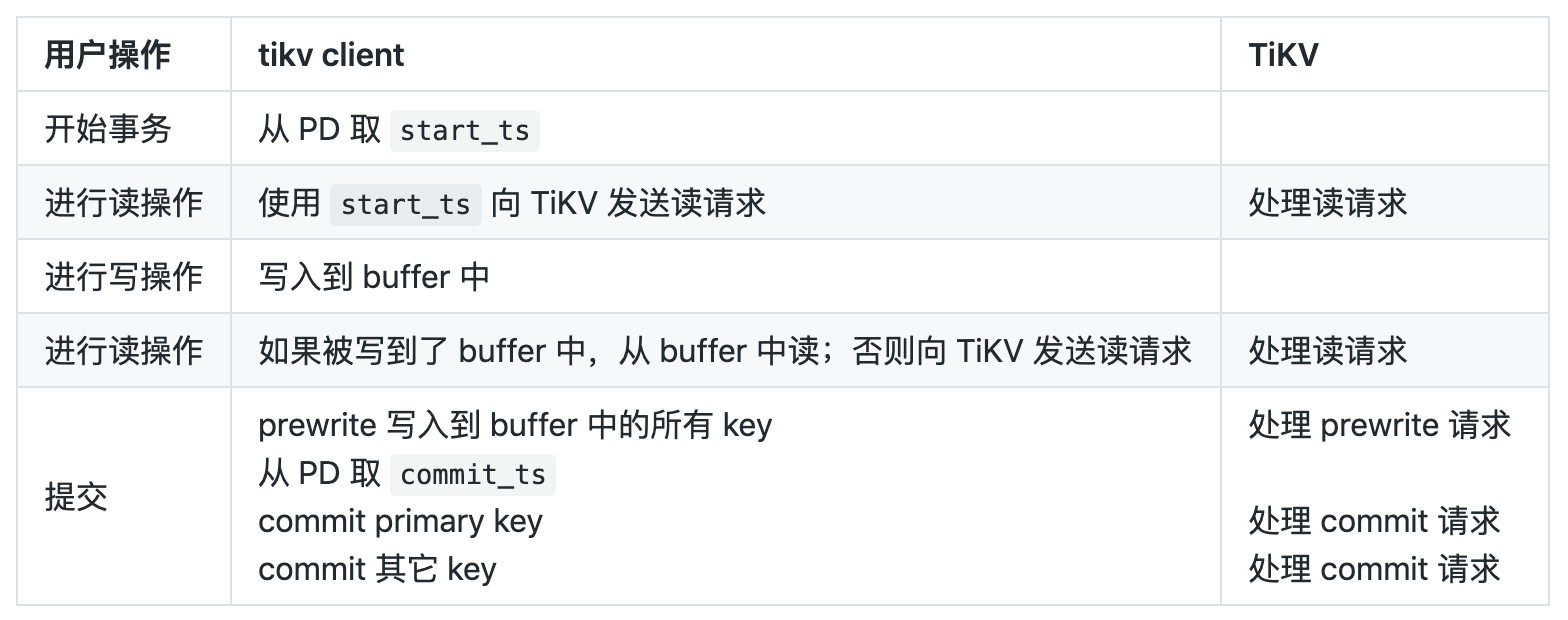
作为上层开发者,我们可能想到以下问题:
- 事务 start 和 commit 阶段会到 PD 取 tso:在 tikv-client 内部有无竞争?
- 读需要经过 1 轮 rpc,请求 tikv store:能否并发/减少这个 rpc 次数?
- 写先写入 mem buffer,提交阶段才会发往对应的 tikv store:mem buffer 的竞争、以及 async commit 是否开启?
2.3 tikv pd 职责
只关注 tikv-client 的话,pd 做了以下的事情
- 给 txn 分 tso
- 告诉 client,某个 key 具体在哪个 tikv region
因此,我们可能要关注大方向
- 一个中心 pd 给几十个 tikv-client 分 tso,有没有瓶颈(网络/逻辑复杂程度/资源竞争)?
- 频繁的 region key-range 查询,有没有瓶颈(client 中 region 的缓存策略,集群总 region 个数)?
3 tikv-client 分析
3.1 client 版本、接口和可配置项
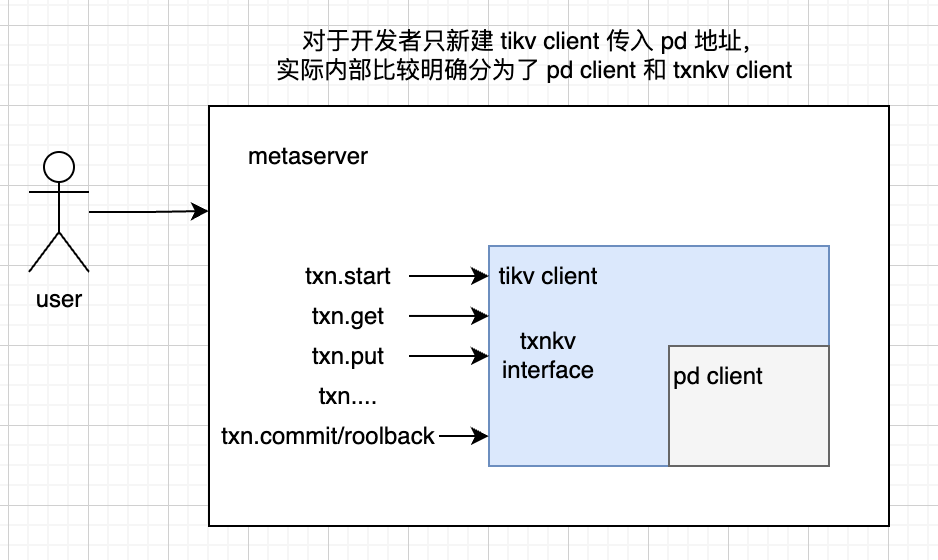
使用 tikv,客户端分别为 tikv-txn-client 和 pd-client。对于开发者只新建 tikv client 传入 pd 地址,实际内部比较明确分为了 pd client 和 txnkv client。
tikv-client / pd-client 仍然处于比较积极的发布中。每次发布都可以看到很多行级别的优化。因此条件允许的时候建议升级。本文的源码分析主要集中于线上使用版本 tikv-client 2.2.0-rc。
tikv-client 可配置选项如下
| 参数 | 值 | 说明 |
|---|---|---|
| CommitterConcurrency | 128 | 一次 txn commit 是最多批量写并发度。我们一般一个 txn 不会写超过 5 条的 key,因此不需要调整 |
| TxnLocalLatches | false | 是否允许本地 txn 排序。本地写同一 key 时,为了避免乐观锁失败,在本地排序发出。由于我们冲突率低,因此不需要调整 |
| GrpcConnectionCount | 4 | grpc 连接数。之前测试发现调到 8 12 效果反而变差 |
| GrpcKeepAliveTime | 10 | |
| GrpcKeepAliveTimeout | 3 | |
| GrpcCompressionType | none | 默认无压缩。其实可以尝试 gzip,以节省带宽。 |
| CommitTimeout | 41s | 我们对每个 txn 设置为了 10s |
| AsyncCommit | false | 是否开启 async commit。不过每个 txn 也能单独设置。 |
| MaxBatchWaitTime | 0 | batch 合并最大等待时间(nanosecond)。默认为 0 为关闭状态。 开启后,如果 tikv 传输层负载高于 OverloadThreshold,则最多等待 MaxBatchWaitTime,尝试合并 |
| MaxBatchSize | 8 | tikv-client 可以将多个 kv 操作合并为一个 batch 操作,是最大的 size |
| OverloadThreshold | 200 | batch 操作时候,根据负载增大等待时间。不过只有在 batch-wait 策略开启时候才会有效 |
| RegionCacheTTL | 600s | tikv-client 缓存 key range ↔ region 信息缓存时间。这期间如果有读则续约 |
| PDServerTimeout | 3s | pd 只能设置 timeout |
其中,pd-client 有较多的设置选项,但是在 tikv-client 中只能设置 PDServerTimeout 一项。
3.2 get set txn 详细流程
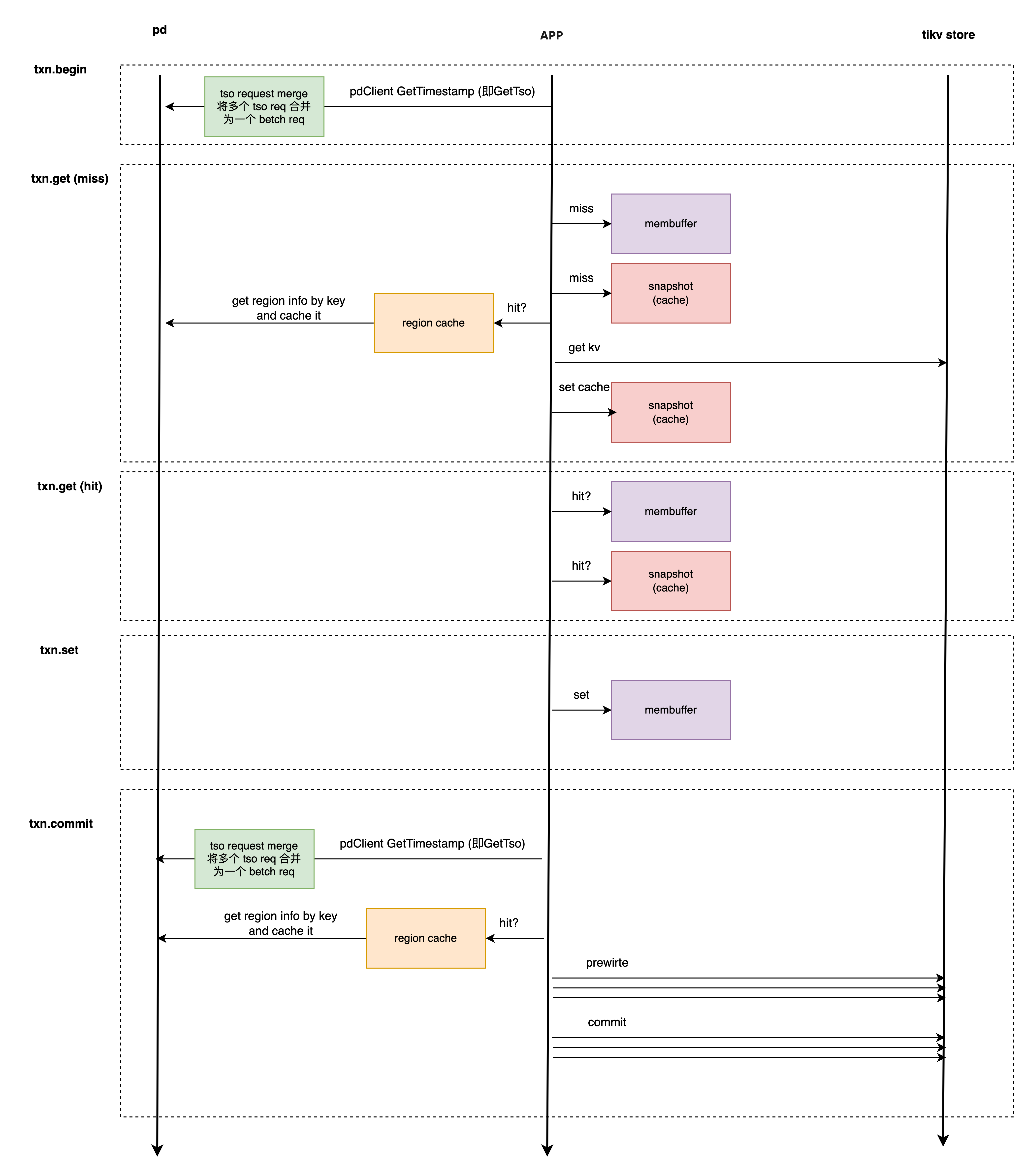
分别查看 tso get、membuffer、region cache、snapshot 可能的全局锁、队列。
由于我们是 txn 单线程串行执行,membuffer snapshot 是每个 txn 独享。因此 membuffer snapshot 的 RW 锁可以忽略。
所以重点考虑 tso get,region cache 流程。
3.3 tso 单点性能问题
我们观察到线上 tso 延迟和用户读写延迟关联度较大。因此重点看了 tso 的单点性能。
PD Client 中存在 tso request dispatcher,对流量进行整形。
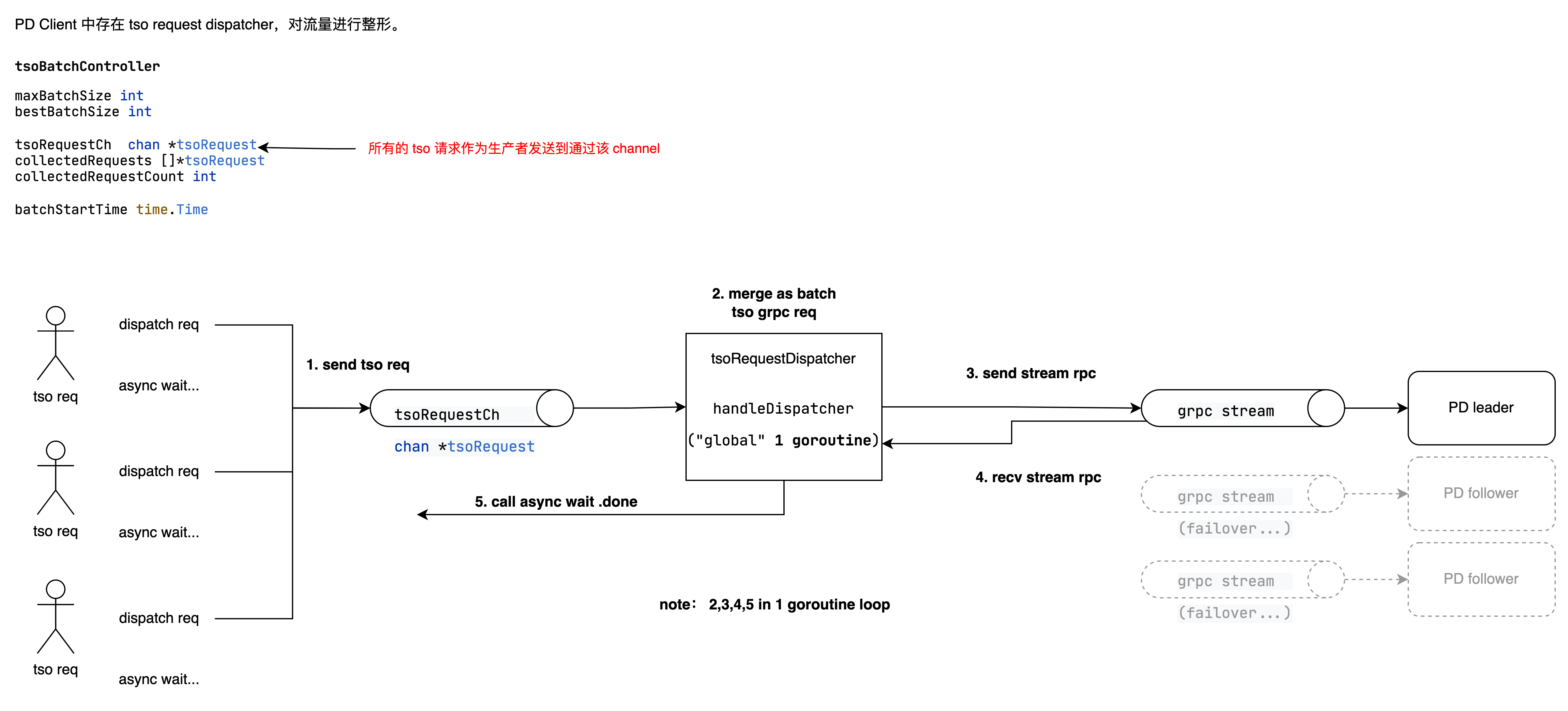
其中,每个 batch tso get 请求最大为 10000 个。tsoRequestCh 大小为 20000。handlerDispatcher 只有 1 个 goroutine 在串行处理所有 2、3、4、5。
当有大量 tso get 时,容易成为性能瓶颈:
- 串行处理上万个 req 的合并
- 同步等待 stream send recv
- 串行回调 req.done
- 注意此部分分别在 resp.logical 上自行处理 addLogical

讨论:
Q: 全局中 tsoBatchController 只存在一个吗?
A:只存在一个 dc location,默认为 global。对于我们,一个 pd client 实例只存在一个 tsoBatchController。
Q: 为啥要用 channel?
A: 我们推测是并发的请求使用 channel 保序。不过对于 txn 模型来说可能不需要在单实例内不保持顺序?(这部分确实有些模糊,望读者指正)
Q: 我们监控的 tso 指标,应该监控什么?
A: pd-client 从外部接口调用 get ts 开始,耗时分为以下部分。我们使用时间图表示
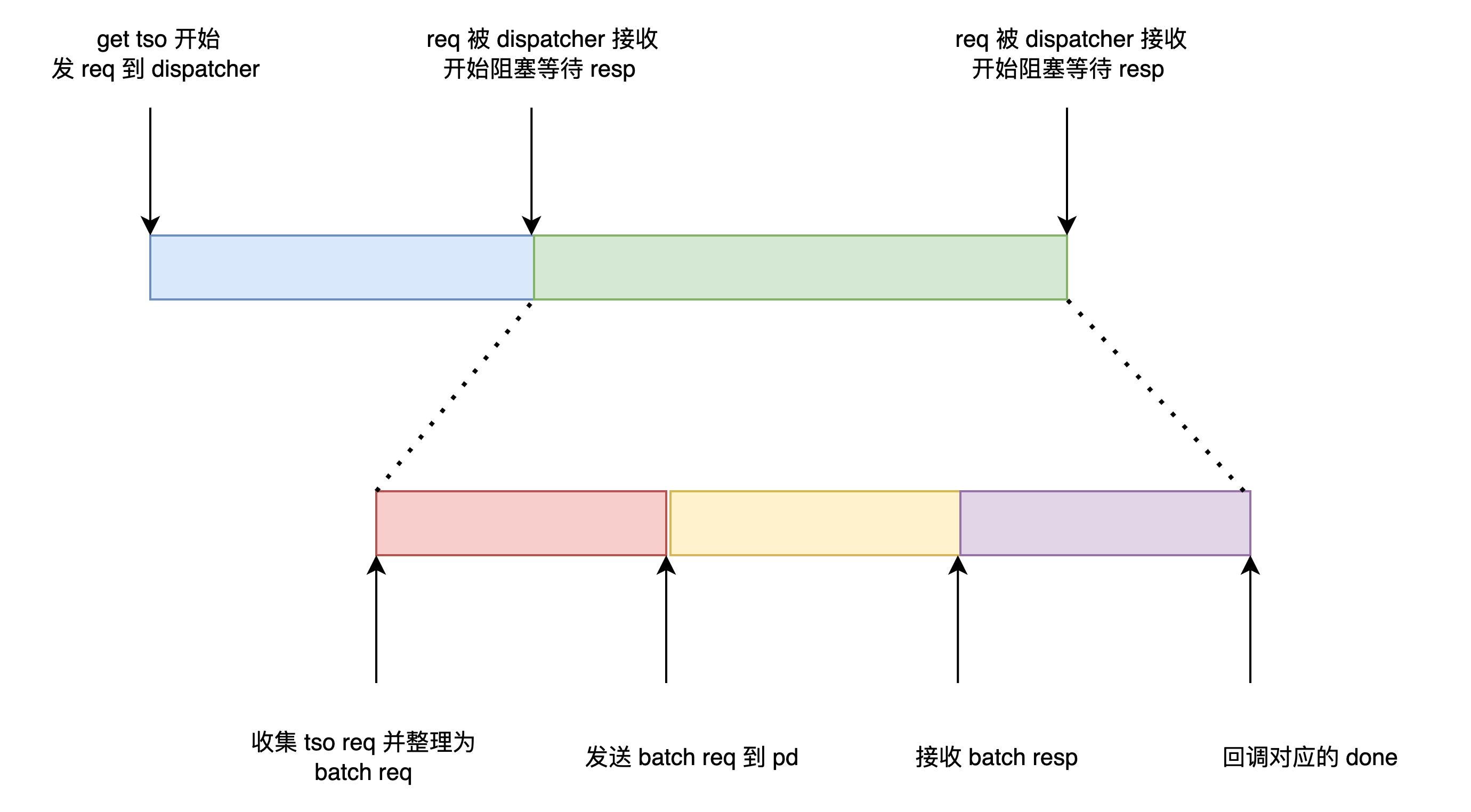
handle_requests_duration
pd_client_request_handle_requests_duration_seconds_bucket{cluster=~"$cluster", type="tso"},是图中的黄色部分。
是纯 tso stream.send stream.recv 的耗时,即 请求 pd tso 的一次 rpc 耗时。该耗时无论是否扩容,常年约 1ms。可以用来判断 client 和 pd 之间网络是否有波动、pd 是否负载高。
handle_cmds_duration
pd_client_cmd_handle_cmds_duration_seconds_bucket{cluster=~"$cluster", type="wait"} (注意和 tso 的 metrics 不一样),是图中的绿色的部分。
req 已经被 dispatcher 接收,开始阻塞等待 req → 得到 resp 的耗时。该耗时波动较大,扩容后降低。说明扩容对红色部分和紫色部分有着较大改善。
我们用同样的颜色染色对应的延迟监控。
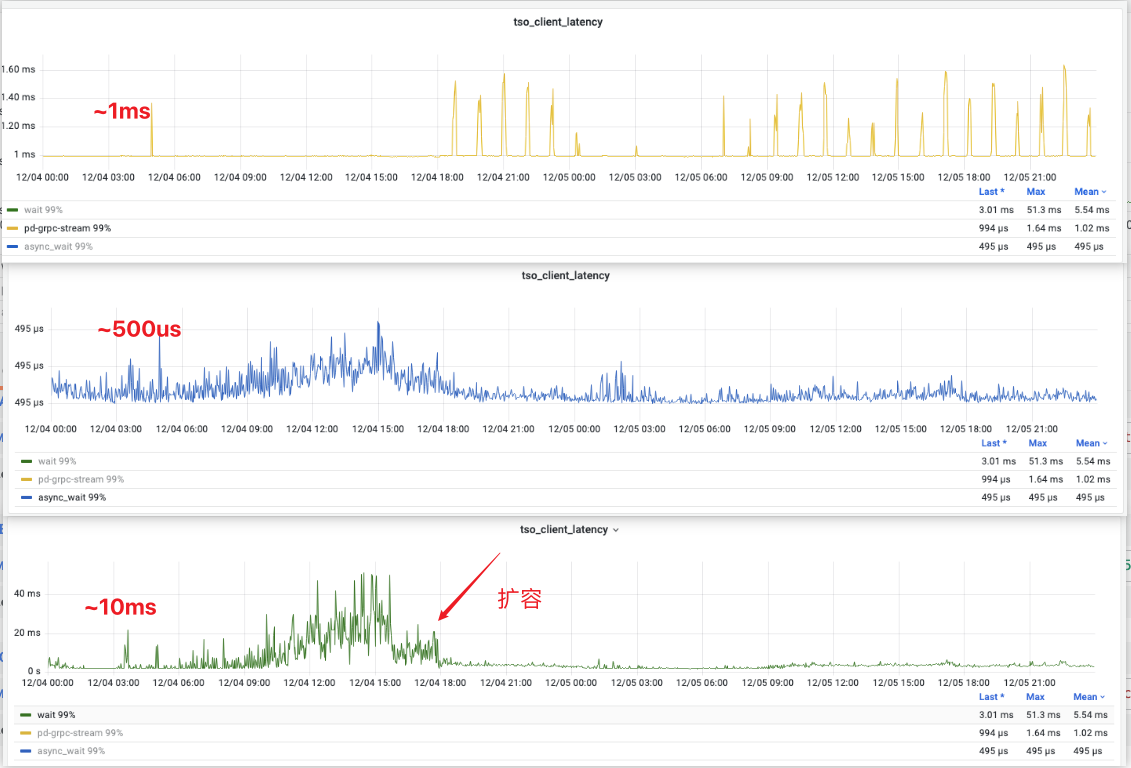
注意:pd rpc 耗时基本不变,async wait 基本不变,tso wait 大大降低。
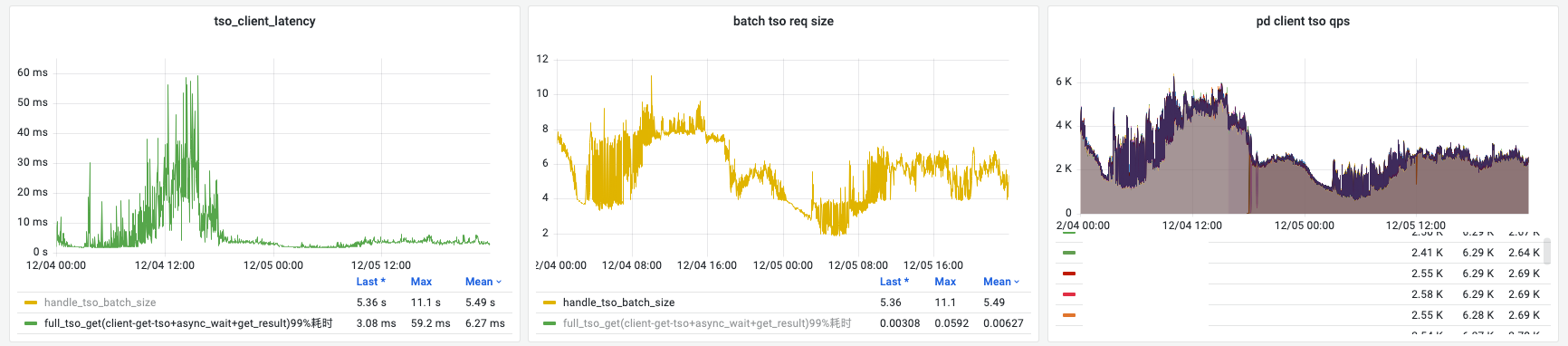
根据现象,我们认为单节点 tso 承载的极限是 qps = 5k,batch size = 8。此时我们认为业务读写压力开始反压,tso 延迟开始暴增,有雪崩势头。可见扩容后 qps 下降到 2k, batch size ~ 6。此时 tso 延迟完全保持在 10 ms 以下。
Q: pd-client 的 grpc 链接数?有无办法调节
A: pd-client 和 pd 使用 grpc 链接,默认参数。使用 grpc stream.send 和 stream.recv。共 1 条链接。目前没有看到调节选项。
Q: PD tso 性能还能顶得住吗?
A: tikv rfc0078 里面提到,如果每个 tikv client 都暴力发 req,会导致 pd 出现严重的性能问题。因此引入 pd-client batch 合并。
还提到一种方式,是使用 PD Follower 作为一层 tso 代理,减少 pd 因巨多 grpc 流数引起的 cpu 飙高。不过 tikv-client 没有提供这部分的配置选项。这部分需要研究评估 tikv 该功能是否稳定。
如果我们横向扩展应用实例,会增大 pd 的连接数并发度。不过具体的影响需要针对 pd 压测才能得到。
Q: tidb 中,是否能使用多个 tikv-client 实例?
A: tidb 中每个进程只使用了 1 个 tikv-client
3.4 小结
由于 tso Dispatcher 每个实例只存在一个。除了 pd 本身的 rpc 之外,还需要 dispatcher loop 逐个收集并回调,产生了较大的 tso 获取延迟。扩容后瓶颈得到缓解。
4 小建议
4.1 小实例、多部署
由于 tso 和 region cache 存在单队列、全局RW锁,可以多部署一些在小实例上。
根据 percolator 的原理,线性增长实例数,tso 请求基本不变(用户总请求数不变时),region 查询请求数上升。
4.2 升级 tikv-client 版本与 tikv 相关
tikv-client、pd-client 最近仍然在积极开发中。应当有很多从整体到行级别的优化可以提升。
若 pd tso cpu 过高,可考虑开启 tikv pd 的 proxy 模式,减少 grpc 流数消耗的 cpu。pd 尽量用高规格机器部署。
4.3 开启 tikv-client metrics
同时开启 pd-client 、tikv-client 两个的 metrics。tikv-client 提供了相当详尽的性能 metrics。
4.4 确认 async_commit 实际运行情况
tikv 提供了一个优化 async_commit[5]。
官方 example 提示只有 session id 开启,才能开启 async_commit。但源码中展示没看到 session ID 的影响。
// async commit would not work if sessionID is 0(default value).
util.SetSessionID(ctx, uint64(10001))
err = txn.Commit(ctx)4.5 使用 txn 的优先级接口
txn 其实提供了优先级接口,初步看源码是实现了读的优先级,req 中填充,由 tikv server 负责调度。
txn.SetPriority(txnkv.PriorityHigh)
txn.SetPriority(txnkv.PriorityLow)
txn.SetPriority(txnkv.PriorityNormal)4.6 精细化调整 batch 设置
无论是 tso batch 还是 txn get put batch,有一些优化可以调整。但 tso batch 可能需要 fork 一份出来,可调节选项较少。
5 总结
- 我们分析了 tikv-client 的 txn 流程,认为单个 tikv-client 实例,由于 tso 合并的串行处理,产生了较大的 tso 获取延迟。
- 需要探查 tikv pd 的极限能力。
- 升级 tikv、tikv-client 版本可能有较大收益。
- 小建议
参考
[1] Tikv延时问题 - TiDB Community
[2] TiKV 源码解析系列文章(十二)分布式事务
[3] TiDB 源码阅读系列文章(十八)tikv-client(上)
[4] TiDB 性能分析&性能调优&优化实践大全
[5] Async Commit 原理介绍丨 TiDB 5.0 新特性
[6] Improve the Scalability of TSO Service




佬的排查过程对萌新很有启发性!<strong>El Psy Congroo!</strong>
@Erika 谢谢!你的认可对我非常重要!