5202 年,我们能享受到怎样的存储硬件性能?

本漫游指南从数据中心硬件、单机性能出发,到构建分布式的对象存储产品的见闻和思考。
系列文章是笔者从事对象存储研发经历的小结。从自己曾有的疑惑出发,收集资料和思考形成,希望能和读者多多交流学习。
目录计划
- 分布式存储漫游指南 1: 2025年了,存储硬件啥样了?
- 分布式存储漫游指南 2: 单机磁盘 IO 的二三事 (同步 I/O 篇)
- 分布式存储漫游指南 3: 单机磁盘 IO 的二三事 (异步 I/O 篇)
- 分布式存储漫游指南 4: 复制和分区, 我变复杂了、但也可靠了
- 分布式存储漫游指南 5: 控制节点 —— 数据节点的管理、路由与迁移修复
- 分布式存储漫游指南 6: 元数据服务与垃圾回收 (GC)
- 分布式存储漫游指南 7: S3 协议, 对象存储的事实标准
- 分布式存储漫游指南 番外1: CDN, 其实我也是存储节点
- 分布式存储漫游指南 8: 容灾与跨区异步复制
Table of Contents
1 前言
我是一名 2050 年的开发者,莫名其妙穿越回了 2025 年。发现团队正准备从零开始构建自研对象存储产品,承载万亿对象和百PiB级别的数据。
我挠了挠头: 2050 年代这些事情都是 AI 自动搞定的,人类早都成最底层奴隶了。2025 年,存储服务器和数据中心硬件的性能究竟是啥水平?
哈哈,笔者只是开篇开了个玩笑。在构建分布式存储之前,我们不妨先来看看当下的硬件能力。实际硬件的选择,一定是成本和性能平衡的。
主要是明确需求:延迟 (us 级别 / ms 级别 / 秒级)、数据规模 (TiB / PiB / EiB) 和吞吐 (io型 iops / 带宽型 GBps or TBps)。
让我们先参考云服务提供商的一份性能基准,对目标产品的性能数量级大概有个印象。
| 特性 | SSD 块存储(高性能) 1 | SSD 块存储(性价比) 1 | 对象存储 23 |
|---|---|---|---|
| 容量范围 | 1,261~65,536 GiB (单盘) | 1~65,536 GiB (单盘) | >PiB 级别 |
| IOPS性能 | min{1,800+50*容量, 1,000,000} | min{1,800+8*容量, 6,000} | 单账户 30K qps |
| 吞吐 | min{120+0.5*容量, 4,000} MB/s | min{100+0.15*容量, 150} MB/s | 单账户下载 100Gbps, 上传 20 Gbps (典型) |
| 4K随机读写延迟 | 0.2ms | 1~3ms | 100ms~2000ms |
当然了,这里只是典型业务需求的参考值。如果扩大集群磁盘数量、使用更好的 SSD,都会提高集群的性能上限。
遗憾的是,地球人在 2025 年广泛使用的计算机架构仍然是冯诺依曼机,离不开 CPU、内存、磁盘、网络等几大件。
无论是服务器、消费级 PC 和智能手机,差别在于性能的高低(以及有多少预算)。
2 超高性能: 高速 SSD 与 RDMA 网络
LLM 训练和推理的存储、虚拟机集群的块存储等需求,对存储系统的性能要求很高。这些应用舍得花费成本,追求极低延迟和巨大吞吐。
考虑我们平时能够买到的云虚拟机产品。其中的硬盘由块存储服务提供,直接通过网络挂载到位于计算节点上的虚拟机上。任何微小的丢包和延迟波动都会在客户端成倍放大,甚至 Hang 住虚拟机中的应用,严重影响用户吞吐。因此这些应用是不能接受性能波动的。
另外对于 AI 训练场景,相较于 GPU 的成本和获取难度,追求存储系统的极限吞吐是很有性价比的。

图: Dell PowerEdge R960 机架式服务器, 可选配 24 x NVMe SSD 和 2 x 100Gbps 网卡 4
2025 年开源的 3FS 存储系统就是原生基于现代 NVMe SSD 和 RDMA 网络构建。其使用的集群为 180 台机器,单机规格为 2×200Gbps InfiniBand 网卡 + 16×14TiB NVMe SSD。压测环境吞吐达到了 6.6 TiB/s。 5
2.1 PCIe 5.0 与 NVMe SSD
既然是旗舰性能,自然少不了 PCIe 5.0 SSD 的加持。自己组装过主机的玩家可能知道,PCIe 每一代的前进基本都代表着总线带宽翻倍提升。
那么问题来了,什么是 PCIe,什么又是 NVMe?
我们的漫游指南不会去具体深究总线和接口的定义,不过可以这么试着理解
- PCIe 是高速公路,决定车道数量(x1/x2/x4)和车速(Gen3/4/5)。
- NVMe 是交通规则,优化车辆(数据包)的调度效率,避免拥堵(如并行队列、多核优化)。
- NVMe 是协议,PCIe 是通道,二者协同工作(NVMe over PCIe)
下表展示了现代企业级高性能 SSD 的性能水平。
| Peak Throughput and Bandwidth | Solidigm PS1010 7.68TB | KIOXIA CM7-R 7.68TB | Samsung PM1743 7.68TB |
|---|---|---|---|
| 256K sequential read (1T/64Q) | 14,848MB/s | 12,092MB/s | 14,495MB/s |
| 256K sequential write (1T/64Q) | 7,117MB/s | 5,796MB/s | 6,052MB/s |
| 4K random read (8T/32Q) | 2,084,960 IOPS | 1,963,066 IOPS | 1,900,838 IOPS |
| 4K random write (8T/32Q) | 408,721 IOPS | 301,061 IOPS | 319,758 IOPS |
表: 企业级 PCIe 5.0 NVMe SSD 性能级别 6
可以看到,4K 随机读来到了恐怖的 200万 iops,连续读也到达了 14GB/s。这个速度完全可以打满单网卡 100Gbps 的带宽。

图: U.2 接口的企业级 SSD,不会使用消费级常见的 m.2 规格,为了保证散热和可靠性,一般是 E3.S 7.5mm / U.2 15mm。
2.2 NVMe 也代表着存储软件栈的革新
NVMe 不仅是概念上的变化,kernel 中的驱动也是原生面向 SSD 设备设计的。下表是 与 AHCI (SATA) 的特性对比。
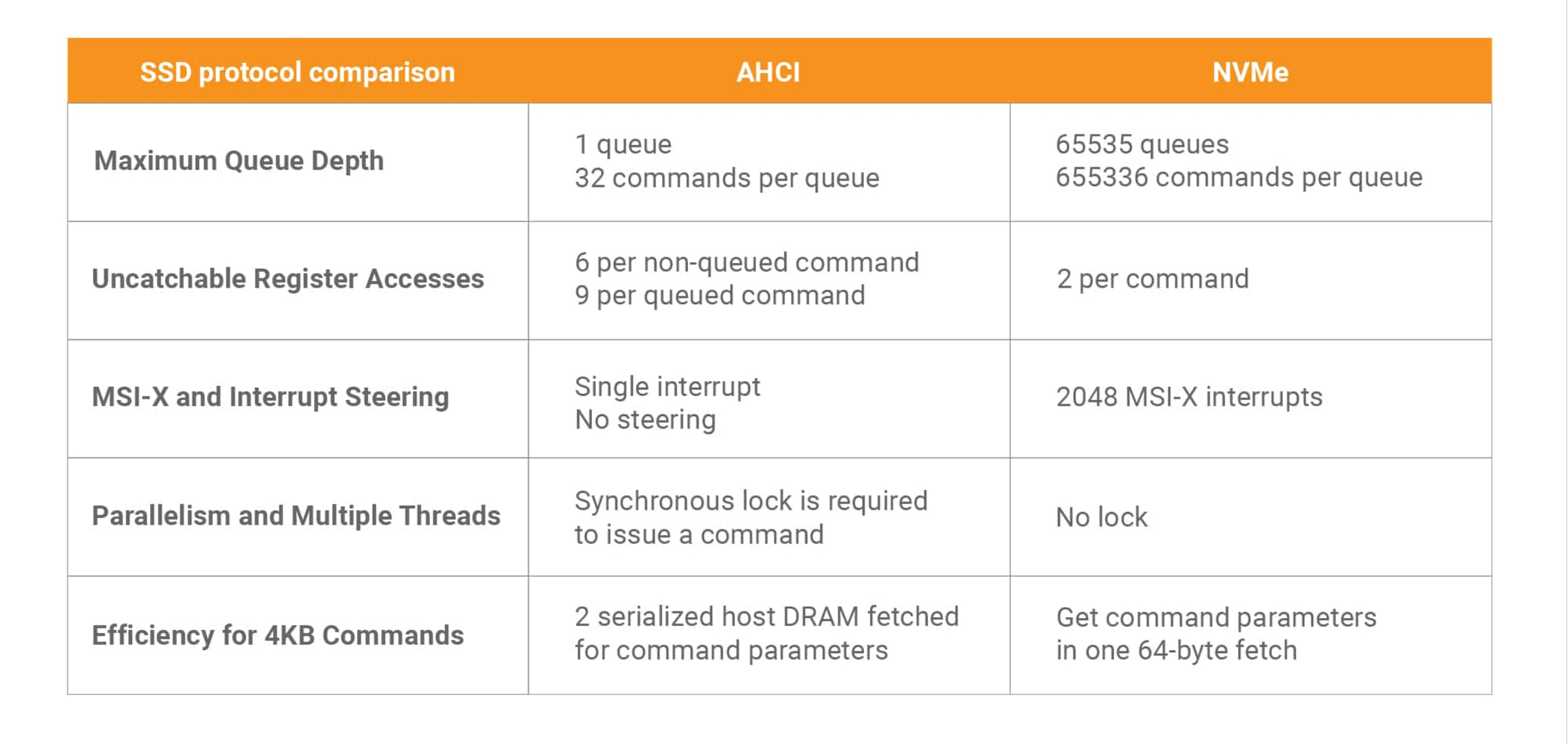 表: AHCI 和 NVMe 对比 7
表: AHCI 和 NVMe 对比 7
AHCI 面向旋转的机械硬盘设计,单队列、深度 32 对于 15000 RPM 的机械硬盘是足够的。物理层面随机读取最多约为 500 IOPS。
而进化到高速 SSD,4K 随机读甚至来到了恐怖的百万 IOPS。因此,必须大幅度提升带宽上线、大幅提高队列和深度、支持多核中断、无锁设计,才能在软件驱动层面最大限度地发挥 SSD 的硬件能力。
有趣的是,2010 年 kernel 块设备/文件系统正准备迎接存储设备从机械硬盘到 SSD 的巨变,其实也仅仅是 15 年前的事情 8。
因此,高性能存储基础设施的发展,包含了硬件的软件的共同发展,为上层构建超高性能分布式存储提供了舞台。
2.3 高速网络与 RDMA
网卡规格达到 100 Gbps 后,为了追求极限性能,需要配合 RDMA 技术使用。RDMA(Remote Direct Memory Access,远程直接内存访问)
如果你问颇有经验的开发者,为啥非要使用 RDMA 不可?他们多半的回答是为了绕过操作系统内核和CPU,直接在应用程序内存之间进行数据传输。这个系统内核态的消耗究竟有多大呢?
我们使用一个没那么恰当的例子,观察用户态函数切换和内核态系统调用的消耗。
#include <iostream>
#include <chrono>
#include <unistd.h>
const int ITERATIONS = 1000000;
// 阻止编译器优化用户态函数
__attribute__((noinline)) void user_space_call() {
// 模拟与 getpid 相当的轻量级操作
static volatile int counter = 0; // volatile 防止优化
counter += 1; // 简单算术运算
asm volatile("" : "+r" (counter) : : "memory"); // 确保内存屏障
}
void kernel_mode_test() {
volatile pid_t dummy; // 防止编译器优化系统调用
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < ITERATIONS; ++i) {
dummy = getpid(); // 系统调用
}
auto end = std::chrono::steady_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
std::cout << "内核态调用总耗时: " << duration << " μs | 单次开销: "
<< static_cast<double>(duration)/ITERATIONS << " μs\n";
}
void user_mode_test() {
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < ITERATIONS; ++i) {
user_space_call(); // 用户态调用
}
auto end = std::chrono::steady_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
std::cout << "用户态调用总耗时: " << duration << " μs | 单次开销: "
<< static_cast<double>(duration)/ITERATIONS << " μs\n";
}
int main() {
std::cout << "--- 用户态/内核态切换开销测试 ---\n";
user_mode_test();
kernel_mode_test();
return 0;
}g++ -O0 -o sys_call_bench sys_call_bench.cc得到的耗时对比如下:
--- 用户态/内核态切换开销测试 ---
用户态调用总耗时: 7139 μs | 单次开销: 0.007139 μs
内核态调用总耗时: 199932 μs | 单次开销: 0.199932 μs这非常直观地说明了如果完全通过内核去收发网络包、多了几次内存拷贝和中断,可能还真会 hang 死用户的虚拟机磁盘。所以还真是不得不使用 RDMA 技术了。
常见的网络技术有:
- InfiniBand:原生支持RDMA,提供低延迟和高吞吐。
- RoCE(RDMA over Converged Ethernet):在以太网上实现RDMA,兼容现有网络设施。
- iWARP:通过TCP实现RDMA,适合广域网场景。
除了时延和性能的提升,RDMA 技术还有一个很大的好处是节省了 CPU。对于大型集群,节省的 CPU 可以直接用来跑一些离线计算任务,提高整个集群的利用率。
那么挑战是什么呢?
需要专有的硬件网卡和交换机。比如 RoCE,需要无损网络和流量控制算法。这就意味着开发者不能像基于 kernel tcp/ip 编程那么畅快。网络性能观测、甚至基础设施交换机硬件的兼容性都要开发者面面俱到。
Azure Storage 大范围使用 RDMA 流量的论文 9 中,除了描述其带来的收益外,也花了大幅篇幅描述了他们遇到的挑战:
- 需要编写基于 RDMA 的通信框架,支持失败时候回退到 tcp
- 紧密观测基础设施 RDMA 流量网络交换的性能指标,防御暂停帧风暴等事件
- 推动网络硬件供应商更新固件解决现有的兼容和性能问题
3 一般性能: 成本、性能和规模的权衡
对象存储一般用于存储媒体资源,在这个看中成本的年代,首要追求低成本,高容量、追求性能和成本的平衡。
比如多媒体资源、用户 KYC 归档。单集群数据量应当是 PiB 起步。大公司的多租户集群甚至能到 EiB 级别 10。
3.1 HDD 容量为王: 你现在知道谁是老大了吼

注重成本的存储,短期看来机械硬盘还无法被取代。近些年,机械硬盘的单机的存储密度逐渐上升。我们以单存储服务器挂载 18x 22TiB HDD,单机架 10 台服务器,这个机架的容量将来到 3.9PiB。
应该配备什么规格的网卡?我们仍然以单机 18 块 HDD 推算,其满载读写为 18 * 100MB/s ~ 14.4Gbps。即使给后台的修复流量和均衡容量预留一定冗余,25Gbps 的网卡即绰绰有余。
3.2 适当的 SSD
在大规模对象存储中,可以在机器上配比一些 SSD 作为读写缓存,对集群的峰值吞吐和小文件 iops 都有比较大的帮助。
对于写,常见的一种做法可以将所有写转为 journal log 顺序写,同时落盘到机械硬盘上。如果用户倾向于读刚刚写入的文件,这种做法收益也很大。
对于读,媒体资源一般和 CDN 配合使用,因此一般不会对少量文件进行高 IOPS 热点读写。可以构建一层 LRU cache,加速用户的热点读请求。
3.3 线性扩展能力
集群的容量可以随着磁盘数量的扩增,容易理解。但是集群的读写性能的提高是有条件的。
分布式存储的根本原理,其实也是所有分布式系统最最根本的两种手段 11:
复制 (replicate)
将用户数据复制多份。最简单的例子是将数据成两副本,分别存在不同的单机上。如此我们就可以容忍其中一台机器的故障,并抓紧时间修复。
值得注意的是,复制的份数越多,可容忍同时损坏的数量越多,数据的安全性就越有保障。当丢失数据的概率小于一定程度的 0.00(...)1% 后,我们在工程上就认为数据几乎不可能丢失,可靠性达到了 99.99(...)9%。
分区 (partition)
分区在不同的分布式系统中含义不同。对于存储系统,可以是将用户数据的不同端分散到不同的机器上。
如果我们使用 EC 冗余算法,针对 k 个原始数据算出 m 个冗余数据,将 k+m 个数据一起存储。则其中k+m 可以容忍丢失任意 m 个。
因此,存储系统的 热点读写最大性能不会超过数据复制和分区所在硬盘的极限性能。
举个例子,假设你使用对象存储集群,使用两副本存储。虽然集群高达 PiB 级别,若未经缓存优化,你疯狂读取单文件的最大速度不会超过两个磁盘极限性能之和。这也是所有云厂商的对象存储都会提醒你,热点读性能有限的原因。
读热点问题的解决可以通过增加 内存 / SSD 读缓存,或暴力增大副本数量环节,但终归和集群规模不是线性增长的。
写热点经过合理设计,是可以做到随集群规模线性上升的。比如一个 append-only 的存储系统,用户写操作可以在任意一组复制组上,完成写后提交元数据系统。
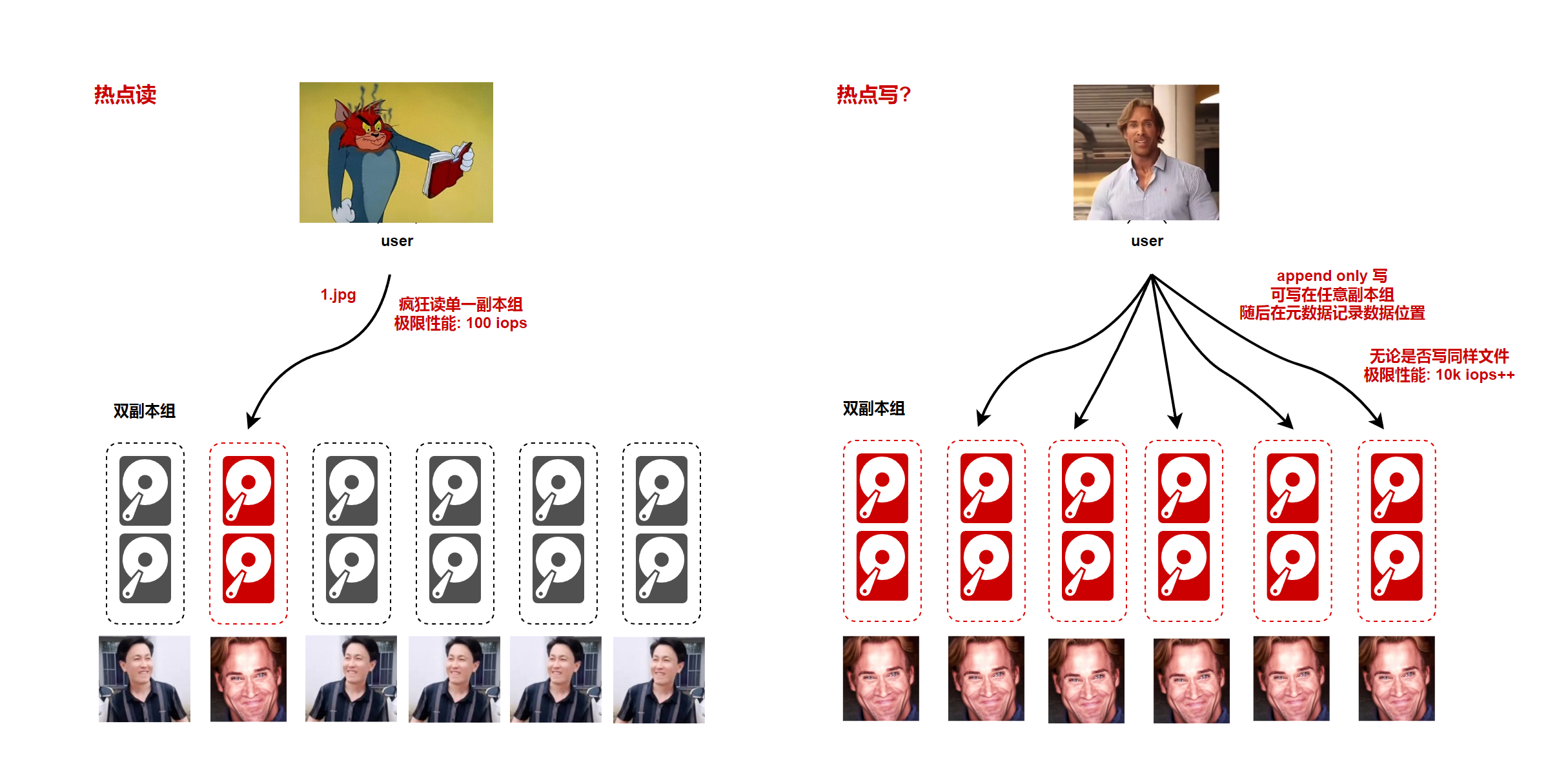
图:集群单一读取点和大量写入点性能
因此,注重成本性能均衡的集群,随机读写能力是随着集群规模几乎线性上升的。另外,读热点问题需要用一定手段去优化。期待在后续文章中和读者讨论相关的话题。
知道了基本原理,我们可以尝试回答 3.4 中的问题。
3.4 磁盘容量密度
单块硬盘,存储容量越大越好吗?
大磁盘不好吗?这就牵扯到机械硬盘的一个尴尬特性:单盘性能没有随着容量提升而提升,而是基本在 百 IOPS 和 百 MBps 的原地踏步。
我们上节已经了解了整个集群的性能是随着磁盘数增多的,因此从吞吐的角度,磁盘数肯定是越多越好的。由 1000 块 8TiB 磁盘组成的集群理论上是 500 块 16TiB 集群的两倍。
另外,在单块磁盘故障时,需要迁移的数据量也会随着单盘容量增大而增加。根据上文,系统通过复制保证数据安全。因此单盘故障时,磁盘越小,数据修复得越快,可靠性越高。
单台机器,存储密度越大越好吗?
同理,在单机器、单 Rack 故障场景下,密度越大,迁移量也会越高。
所以在注重性能的集群中,一般尽量增加盘数和机器数,减少单节点容量密度。大密度的机器适合容量大但读写少的冷集群(因为我们可以火力全开去修复任何损坏的数据)。
3.4 Raid 卡不只能做 Raid
我们自己在不同机器之间做了复制和分区,为了追求容量,单机一般不使用 Raid 阵列。除非使用 Raid 提高单机读写性能。
硬件 Raid 卡除了做 Raid 阵列外,还有一个实用功能:一小块带电缓存的 cache。这样我们的 fsync 操作可以很快,同时对小型 io 有一定的整形作用,提高性能。
当然也是有代价的: Raid 卡可能透明地做一些全盘 check 的后台操作。笔者就曾经遇到每周固定时间段读写延迟的诡异上升,最后查明是 Raid 卡在做定时后台整理导致。应用工程师也应该意识到在磁盘和系统之间,还有一层 Raid 卡的存在。
3.5 成本优先: 机器老了点,又不是不能存
可以使用置换下来的过保旧存储机器作为冷数据集群。
此类机器故障率偏高,我们的应对策略还是经典手段:复制与分区。
复制:提高数据的副本数,尽量加快数据的修复速度。
分区:大幅度提高 EC 冗余算法的校验片。比如从 EC4+2 提高到 EC16+8,数据冗余度仍然是 1.5,但集群可以容忍的同时失效节点从 2 台提高到了 8 台。
3.6 和我们消费级硬件究竟啥区别:可靠性
可靠性
企业级设备专为严苛的环境设计,使用寿命远远大于消费级硬件。稳定可预测的可靠性非常重要,支持和维保是昂贵的。我们能够容忍少数节点的失效,但服务的 SLA 保证,仍然建立在硬件的可靠性概率上。
分布式存储系统的可靠性主要受以下指标影响 12:
- MTTF (Mean Time To Failure): 平均无故障时间。系统从正常运行的开始时间到发生故障时间之间的平均值。
- MTTR (Mean Time To Repair): 平均修复时间,系统从发生故障到维修结束之间的平均值。
- MTBF (Mean Time Between Failure): 平均失效间隔,系统两次故障发生时间之间的平均值。
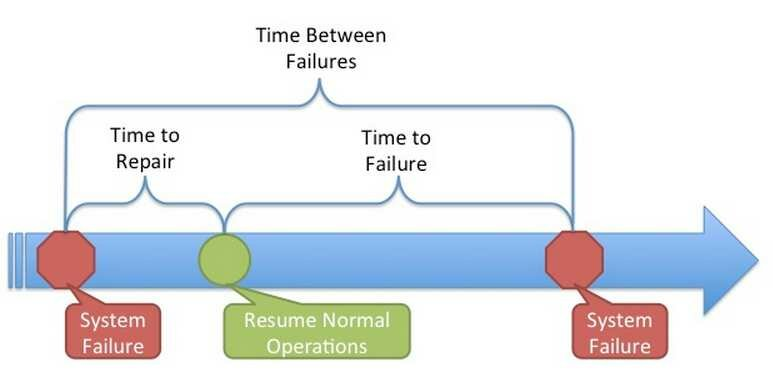
图: 系统数据丢失过程 12
其实完全不用描述得这么高深,数据丢失其实就是
- 探测到磁盘/节点坏了
- 开始从其他副本/分片修复数据
- 还没修复完,很不幸,剩余的副本所在磁盘/节点也坏了 😭
- 悲剧: 用户的数据丢了
所有的分布式系统容灾都是有能力范围的。因此,当修复的速度一定时候,硬件的失效概率必须足够低,才能保证不会发生 2,3 同时发生的悲剧。
fsync 性能
还有一个重要的点:企业级硬盘的 fsync 性能差异。文章 13 指出,消费级和企业级磁盘的 fsync 性能差异巨大。一般我们构建分布式存储软件时候,首要是要保证用户的数据安全性(除非用户能接受牺牲一点数据安全性换性能)。
fsync 性能不佳,直接影响了数据安全关键性应用的性能。对于需要串行写入的应用(比如 raft组 日志),fsync 性能低代表着灾难性的性能下降。
4 大规模冷存储: 磁带
高性能、高成本的另一个极端:基本不读取、极低成本。企业留存的审计用资料、深度的全量备份,可能永远不会读取,但是在需要的时候必须能够提供。这类应用能够接受事先解冻数据,然后在数个小时、甚至数天后再读取。
这种场景就轮到磁带库的登场了。磁带容量大、成本不高。而且有个很独特的优势:不用的时候不费电。
4.1 磁带库硬件
典型磁带的性能对比如下表。
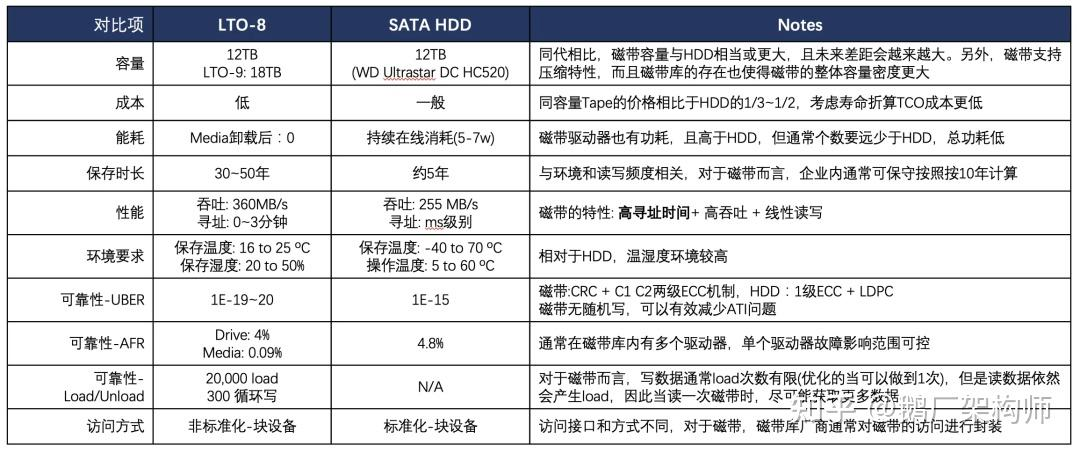
表: 磁带和机械硬盘的对比 14
磁带的读取和写入速度还可以,寻址和循环写的代价相当高。
而企业级磁带库往往是一个大型的 “硬盘”,只不过 “磁头” 在整个房间里去寻址。

图: 你醒啦? 磁带库的机械臂正在寻址到你归档数据的磁带、抓取、放到驱动器准备读取 15
4.2 用户接口: S3 冷数据存储
S3 的 Glacier 就是为深度归档使用的对象存储接口。
用户的一般的写入流程:
- 用户写入文件到一般的 S3 对象存储
- 后台对象存储聚合、下沉到磁带冷存储层中
- 删除上层的数据
用户一般的读取流程:
- 用户提前请求需要读取的数据
- 调度任务从下层冷存储中解冻数据,复制出来存在一般的 S3 对象存储中
- 用户取数据
- 删除复制的临时数据
4.3 构建深度冷存储
感兴趣的同学可以参考腾讯云对象存储分享的实践文章14。
因此其中的 GC 和碎片整理、任务调度很有趣。无论何种系统,其中的 GC 策略也可以参考 14。
5 小结
存储系统的设计始终围绕着性能、成本和规模三大核心要素展开。不同层级的存储硬件各有千秋,而分布式存储系统正是基于这些硬件特性进行垂直整合与水平扩展的产物。
让我们通过一张表格总结今天的内容。
| 特性维度 | 高性能存储 | 成本性能平衡型存储 | 冷存储 |
|---|---|---|---|
| 核心硬件 | PCIe 5.0 NVMe SSD + RDMA网络 | 大容量HDD/SSD + 25Gbps以太网 | 磁带库 |
| 延迟特征 | μs级随机读写 | ms级随机访问 | 小时级数据解冻 |
| 吞吐能力 | TiB/s级集群吞吐 | 百GB/s级集群吞吐 | - |
| 适用场景 | AI训练/高频交易 | 对象存储/热数据备份 | 合规归档/灾难恢复 |
| 成本模型 | 超高 | 平衡 | 极低 |
| 可靠性机制 | 多副本 | 多副本/纠删码 | 多副本/纠删码 |
| 典型代表 | 3FS | Ceph/MinIO | Glacier/磁带库 |




2050年的实际情况是,虽然 SSD 读写变成了 1PB/s, 但是大家还是在按100MB/s给s3送钱。
@madalpaca 哈哈哈哈哈 没绷住