上篇文章中我们探索了同步 IO 的来龙去脉。本篇文章将踏入异步 IO 王国,研究磁盘 IO 的异步编程。

目录计划
- 分布式存储漫游指南 1: 2025年了,存储硬件啥样了?
- 分布式存储漫游指南 2: 单机磁盘 IO 的二三事 (同步 I/O 篇)
- 分布式存储漫游指南 3: 单机磁盘 IO 的二三事 (异步 I/O 篇)
- 分布式存储漫游指南 4: 复制和分区, 我变复杂了、但也可靠了
- 分布式存储漫游指南 5: 控制节点 —— 数据节点的管理、路由与迁移修复
- 分布式存储漫游指南 6: 元数据服务与垃圾回收 (GC)
- 分布式存储漫游指南 7: S3 协议, 对象存储的事实标准
- 分布式存储漫游指南 番外1: CDN, 其实我也是存储节点
- 分布式存储漫游指南 8: 容灾与跨区异步复制
Table of Contents
0 前言
本文依旧聚焦于 Linux 平台。总览异步编程,表格如下:
| 技术 | 核心原理 | 编程接口 | I/O 类型支持 | 性能特点 | 局限性 |
|---|---|---|---|---|---|
| io_uring | 环形队列 + SQ/CQ 无锁队列 | io_uring_setupio_uring_enterliburing 封装库 |
全异步 (read/write, fsync, socket, etc.) |
• 零拷贝设计 • 批处理提交/完成 • 内核旁路优化 |
需 Linux 5.1+ API 较复杂需封装 |
| epoll | 就绪事件通知 (红黑树+链表) | epoll_createepoll_ctlepoll_wait |
网络 I/O 为主 (支持 socket, pipe) |
• O(1) 事件就绪检测 • 水平/边缘触发 |
仅支持文件描述符就绪通知 磁盘 I/O 需配合线程池 |
| libaio | 原生内核 AIO | io_setupio_submitio_getevents |
Direct I/O 磁盘 (O_DIRECT) |
• 真异步磁盘 I/O • 但存在阻塞点 |
仅支持 O_DIRECT 部分操作非异步 (fsync) 存在内存对齐限制 |
| POSIX AIO | 用户态线程模拟 | aio_readaio_writeaio_error |
文件/网络 (假异步) | • 实质是线程池包装 • 上下文切换开销大 |
性能差 不适用于高性能存储 |
其中,POSIX AIO 笔者很少见到使用。epoll 多见于网络 socket 的异步处理,不能处理 disk io。
鉴于本文为写于 2025 年的存储小品文,kernel 早已经推进至 6.15, 故将重点放于 libaio 和 io_uring。
0.1 为什么从未见到 disk io 使用 epoll?
在 Linux 的世界中,一切皆文件的思想贯彻始终。然而文件也是有各种类型的。
| 类型标识符 | 文件类型 | 描述 | 典型示例 |
|---|---|---|---|
| - | Regular File(普通文件) | 存储在磁盘上的标准数据文件(文本、二进制、压缩包等) | /etc/passwd, app.exe, data.zip |
| b | Block Device(块设备) | 按数据块访问的设备(有缓冲,支持随机访问) | /dev/sda, /dev/nvme0n1 |
| s | Socket(套接字) | 进程间通信的端点(网络或本地) | /run/docker.sock |
| ... | ... | ... |
本地文件的 IO 操作的是 Regular File,它永远都是可就绪的。
POSIX 允许:普通文件的 O_NONBLOCK 可能被忽略(多数实现中无效)1。因此,使用对其使用 epoll 没有意义。
普通文件的读写操作在传统内核中总是就绪(从内核视角看,磁盘 I/O 的阻塞发生在底层驱动,而非文件描述符层面)。即使设置 O_NONBLOCK,read()/write() 仍会因等待磁盘操作而阻塞。
继续阅读相关文章2。
注:有些高性能存储系统会实现自己的通信网络栈,涉及到网络通信,自然可能使用 epoll 技术。本节只讨论本地文件 IO。
0.2 我真的有必要使用异步 IO 吗?
工程没有银弹。笔者认为,只有明确需要处理超高负载、延迟要求较低的系统,以及使用同步 I/O 无法榨干硬件性能;或者计算任务混合部署时,才需要引入异步 IO。
同时,开发者需要意识到,异步 I/O ≠ 更高性能。若系统已经达到了硬件能力,更换 IO 模型也几乎不可能令吞吐翻倍,往往是需要考虑更合理的 IO 系统模式设计。
异步 I/O 打破了天然人类思维的 “顺序流程”。整个系统可能需要引入 async,以及回调/状态机/协程;需要引入智能指针在整个异步过程中管理 IO buf 的生命周期等等。这些都增大了调试、理解的难度。(试想一下在 gdb 栈和日志中调查一个充满了回调系统的非预期行为…)。
graph TD
A[存储系统需求]
A --> C[优先使用异步I/O]
A --> D[同步I/O+优化可接受]
C --> E[高并发>10K QPS]
C --> F[延迟要求<1ms]
C --> G[硬件IOPS>100K]
D --> H[吞吐<1GB/s]
D --> I[单线程即可满足]1 Linux AIO
Linux Kernel Asynchronous I/O 于 2003 年进入内核,libaio 是其用户态接口的库封装。
时至今日看,linux aio 存在一系列的批评声音3。笔者很少见到新的项目选择使用 linux aio 了,大部分转而去拥抱 io_uring。但不可否认的是,AIO 切切实实为 Linux 磁盘异步 IO 曾经的生产实践。
1.1 异步 I/O 基础
Linux AIO 的基本使用,体现了异步 IO 的基本范式: 提交-执行-收割。
graph LR
A[提交队列 Submit] --> B[内核执行]
B --> C[完成队列 Completion]一般开发者不会直接调用 syscall,而是使用为用户封装的库 libaio。具体来讲,libaio 的关键调用如下:
| 阶段 | 系统调用 | 功能 |
|---|---|---|
| 上下文初始化 | io_setup() | 创建事件队列(最大深度 128-4096) |
| 准备异步请求 | io_prep_pread/pwrite() | 准备异步 io 请求结构体 |
| I/O 提交 | io_submit() | 批量提交请求(iocb 结构体) |
| 事件获取 | io_getevents() | 阻塞/非阻塞获取完成事件 |
其余关键控制函数还有 prepare、cancel 等操作,可参考 libaio 文档。
1.2 AIO 的缺陷
LWN.net 2017 年的一篇博客3精辟地总结了开发者们对 linux aio 的批评,大致包含以下几点。
1.2.1 某些条件下意料外的阻塞
虽然我们以异步非阻塞的方式提交了 io,但还要验证其在任何文件系统、内核版本都是以异步方式运行的。
Seastar 甚至推出一个专门的工具4,通过测量上下文切换次数判断是否内核进行了阻塞 IO。
这是很多开发者不太能接受的,尤其是用户应用代码在不同的内核、文件系统/块设备、磁盘负载下,表现出不一致的阻塞性。一个纯 async 的进程可能突然在某种条件下 hang 住一段时间,造成性能大幅下降。
1.2.2 只支持 Direct I/O
Linux AIO 被设计时主要聚焦于避免阻塞的磁盘 I/O,且强制要求使用 O_DIRECT 标志。这其实限制了其范围、设计思路、接口定义。
一方面,从应用开发者:只有部分需要使用 AIO 的,比如数据库、存储引擎应用才会去重度使用5。使用 O_DIRECT 需要自己处理一系列的内存对齐、自己构建上层的 buffer 系统5。
另一方面,从内核开发者:网络读写、甚至任何 syscall 是不是都可以有一套异步接口?Linux AIO 一直也被持续改进,但是被认为还是需要有一个通用的、异步调用 syscall 的机制,而不是扩展已有的 AIO 接口6。
1.3 ScyllaDB/Seastar 与 AIO
ScyllaDB/Seastar 重度使用了 linux aio。博客有一系列关于磁盘 io 的文章,非常适合阅读。尤其是 io 调度主题。
- Database Internals: Working with I/O - ScyllaDB Blog
- Top Mistakes with ScyllaDB Storage - ScyllaDB Blog
- On-Demand Webinar: Different I/O Access Methods for Linux - What We Chose for ScyllaDB and Why - ScyllaDB Blog
- What We've Learned After 6 Years of I/O Scheduling - ScyllaDB Blog
- How io_uring and eBPF Will Revolutionize Programming in Linux - ScyllaDB Blog
- Scylla's New I/O Scheduler - ScyllaDB Blog
- I/O Access Methods in Scylla - ScyllaDB Blog
2 io_uring
随着硬件设备性能的发展,Linux 内核一个新的异步 IO 技术逐渐发展起来,io_uring。它总结了对 aio 的抱怨,发展成为一组真正异步、面向任何 IO 类型的异步接口 7。
io_uring 的使用可参考 Lord of the io_uring 系列文章。对于用户库,建议使用更加友好的 liburing。实际上有些 io_uring 的使用细节和文档,liburing 工程反而更加全面。
2.1 基本原理与基本接口
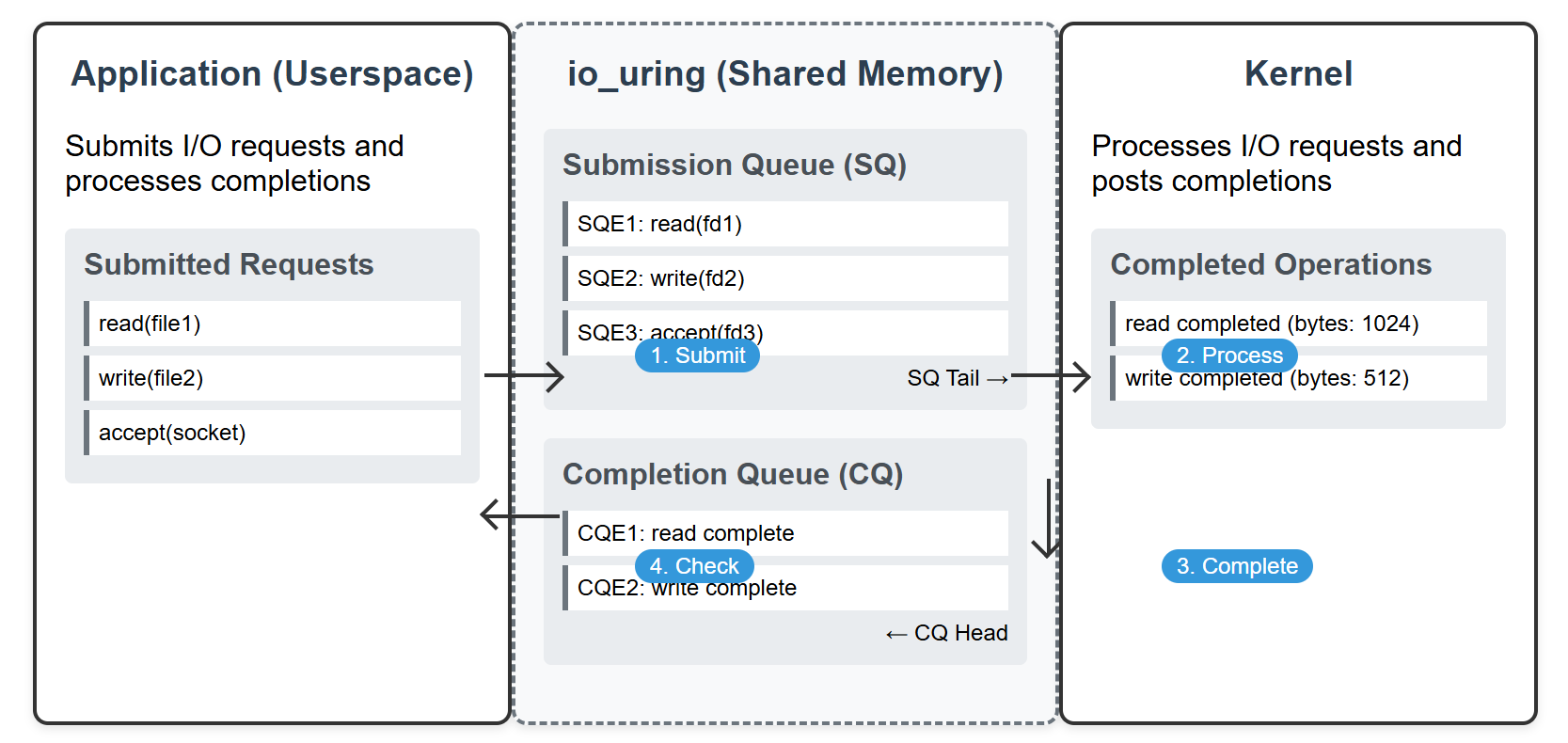
io_uring 使用的心智模型较为简洁,开发者可同样地理解为 “提交-执行-收割”。正如其名,分为两个环形队列
- 提交队列(SQ)用于提交请求,完成队列(CQ)用于通知请求完成情况
- 环形缓冲区在内核和用户空间共享
- 用户应用写入单个或者多个提交事件,包含了操作信息、数据指针等,提交到 SQ 尾部
- 用户应用使用系统调用提交请求
- 内核处理完毕后,将完成事件放到 CQ 尾部
- 用户应用从 CQ 头部读取完成事件
2.2 Ring! Ring! Ring! 环形缓冲区
无锁竞争
在单生产者-单消费者模型中,环形缓冲区是一个常见的高性能设计。在 io_uring 中:
- 提交队列(SQ):应用是生产者(提交IO请求),内核是消费者(消费请求)。
- 完成队列(CQ):内核是生产者(生成完成事件),应用是消费者(处理完成事件)。
使用环形缓冲区来消除锁竞争。通过分离生产者和消费者的指针(如头尾指针),双方无需共享锁,仅需内存屏障(Memory Barrier)保证可见性,大幅降低同步开销。
零拷贝
通过环形缓冲区,移动指针而不是数据复制。
延迟确定性
插入和删除操作在 O1 时间完成。
反压控制
生产者能感知缓冲区深度,在必要时候阻塞/丢弃数据。
2.3 io_depth
进入到异步 I/O 后,有一个重要的概念 io_depth 需要关注。读者可能已在硬盘性能测试套件 fio 中见过这类参数。借用 fio 手册的定义:
iodepth=int
Number of I/O units to keep in flight against the file即发出去正在执行的 io 数量。可以理解为生产-消费模型,我们提交一系列 IO 到异步队列中,这个 “深度” 指的就是我们视角提交出去,还未取得结果的 IO 数量。
为什么异步 I/O 才会关注 io_depth?
一般在同步 IO 中,每个线程同时只能提交一个 IO 请求,取得结果前线程被阻塞。因此同步 IO 的 io_depth 只能为 1。同步 IO 我们一般关注 in-flight 线程数量。
实际系统中,io_depth 可以作为观测系统压力的指标。观测到 io_depth 上升,意味着磁盘消费 IO 小于用户生产 IO 的速度,系统开始反压 (back pressure)。必须考虑引入合理的限流措施,并分析磁盘性能是否符合预期。
io_depth 越高越好吗?
在现代 SSD 硬件中,可以并行执行 IO 请求,因此适当的 io_depth (比如 16,64) 有利于充分利用磁盘性能。另外,OS 层面可以对 IO 进行一定合并,提升性能。
深度过大,效果提升逐渐不明显,一方面 OS 可能限制最大深度;磁盘达到性能极限后,也不会因为请求增大而大幅提升。
2.4 Code Snippet
我们重构上篇文章的线程池 IO 例程,改为使用 io_uring 方式提交 IO 请求、收割 IO 请求。
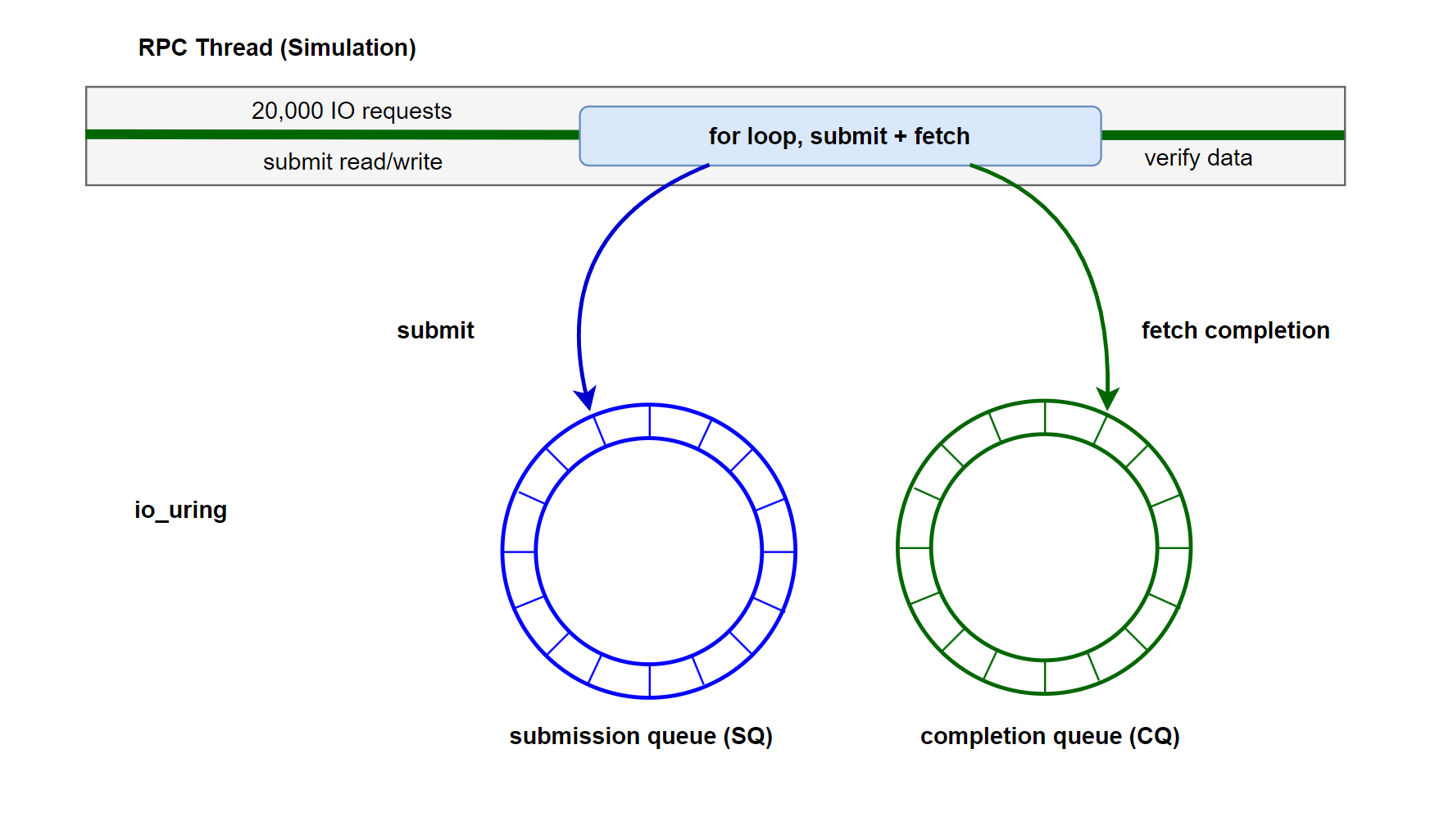
首先封装一些异步 IO 用的 context 结构体。
struct UringData {
void *user_ctx;
OpType op_type;
};
struct UserContext {
enum class Type { WRITE, READ } type;
int fd = -1;
off_t offset = -1;
std::shared_ptr<std::array<char, IO_BLOCK_SIZE>> buffer;
ssize_t write_result = -1;
ssize_t fsync_result = -1;
ssize_t read_result = -1;
bool write_completed = false;
bool fsync_completed = false;
bool read_completed = false;
UringData write_data{this, OpType::WRITE};
UringData fsync_data{this, OpType::FSYNC};
UringData read_data{this, OpType::READ};
};UringIO 类,模拟用户的 io 请求,异步 io 请求提交和收割。其中,我们将 write io 和 fsync link 到一起,保证逻辑顺序。
class UringIO {
public:
explicit UringIO(unsigned int depth) : ring_(), depth_(depth) {
int ret = io_uring_queue_init(depth, &ring_, 0);
if (ret < 0) {
throw std::runtime_error("io_uring_queue_init failed: " + std::string(strerror(-ret)));
}
}
~UringIO() { io_uring_queue_exit(&ring_); }
// simulate user io
void simulate_user_rpc(int fd) {
std::vector<std::unique_ptr<UserContext>> write_ctxs;
std::vector<std::unique_ptr<UserContext>> read_ctxs;
unsigned int inflight = 0;
int write_count = 0;
int read_count = 0;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, IO_COUNT - 1);
auto start_time = std::chrono::high_resolution_clock::now();
// write: seq write + FSYNC
while (write_count < IO_COUNT || inflight > 0) {
// submit write
while (write_count < IO_COUNT && inflight <= depth_ - 2) {
auto ctx = std::make_unique<UserContext>();
ctx->type = UserContext::Type::WRITE;
ctx->fd = fd;
ctx->offset = write_count * IO_BLOCK_SIZE;
ctx->buffer = std::make_shared<std::array<char, IO_BLOCK_SIZE>>();
char content_char = 'A' + (write_count % 26);
memset(ctx->buffer->data(), content_char, IO_BLOCK_SIZE);
// get SQE for write
struct io_uring_sqe *write_sqe = io_uring_get_sqe(&ring_);
if (!write_sqe)
break;
io_uring_prep_write(write_sqe, fd, ctx->buffer->data(), IO_BLOCK_SIZE, ctx->offset);
io_uring_sqe_set_data(write_sqe, &ctx->write_data);
// get SQE for fsync
struct io_uring_sqe *fsync_sqe = io_uring_get_sqe(&ring_);
if (!fsync_sqe)
break;
io_uring_prep_fsync(fsync_sqe, fd, IORING_FSYNC_DATASYNC);
io_uring_sqe_set_data(fsync_sqe, &ctx->fsync_data);
fsync_sqe->flags |= IOSQE_IO_LINK; // link write+fsync
// submit
int ret = io_uring_submit(&ring_);
if (ret < 0) {
std::cerr << "io_uring_submit failed: " << strerror(-ret) << std::endl;
break;
}
inflight += 2;
write_ctxs.push_back(std::move(ctx));
write_count++;
}
// fetch competition
if (inflight > 0) {
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring_, &cqe);
if (ret < 0) {
std::cerr << "io_uring_wait_cqe failed: " << strerror(-ret) << std::endl;
break;
}
UringData *data = static_cast<UringData *>(io_uring_cqe_get_data(cqe));
UserContext *ctx = static_cast<UserContext *>(data->user_ctx);
switch (data->op_type) {
case OpType::WRITE:
ctx->write_result = cqe->res;
ctx->write_completed = true;
break;
case OpType::FSYNC:
ctx->fsync_result = cqe->res;
ctx->fsync_completed = true;
break;
case OpType::READ:
ctx->read_result = cqe->res;
ctx->read_completed = true;
break;
}
io_uring_cqe_seen(&ring_, cqe);
inflight--;
}
}
// read: rand write
while (read_count < IO_COUNT || inflight > 0) {
// submit read
while (read_count < IO_COUNT && inflight < depth_) {
int block_num = dis(gen);
off_t offset = block_num * IO_BLOCK_SIZE;
auto ctx = std::make_unique<UserContext>();
ctx->type = UserContext::Type::READ;
ctx->fd = fd;
ctx->offset = offset;
ctx->buffer = std::make_shared<std::array<char, IO_BLOCK_SIZE>>();
struct io_uring_sqe *read_sqe = io_uring_get_sqe(&ring_);
if (!read_sqe)
break;
io_uring_prep_read(read_sqe, fd, ctx->buffer->data(), IO_BLOCK_SIZE, offset);
io_uring_sqe_set_data(read_sqe, &ctx->read_data);
int ret = io_uring_submit(&ring_);
if (ret < 0) {
std::cerr << "io_uring_submit failed: " << strerror(-ret) << std::endl;
break;
}
inflight++;
read_ctxs.push_back(std::move(ctx));
read_count++;
}
// fetch compelation
if (inflight > 0) {
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring_, &cqe);
if (ret < 0) {
std::cerr << "io_uring_wait_cqe failed: " << strerror(-ret) << std::endl;
break;
}
UringData *data = static_cast<UringData *>(io_uring_cqe_get_data(cqe));
UserContext *ctx = static_cast<UserContext *>(data->user_ctx);
if (data->op_type == OpType::READ) {
ctx->read_result = cqe->res;
ctx->read_completed = true;
}
io_uring_cqe_seen(&ring_, cqe);
inflight--;
}
}
auto end_time = std::chrono::high_resolution_clock::now();
// verify data
bool write_all_success = true;
for (auto &ctx : write_ctxs) {
if (ctx->write_result != static_cast<ssize_t>(IO_BLOCK_SIZE)) {
write_all_success = false;
std::cerr << "Write failed at offset " << ctx->offset << ": expected "
<< IO_BLOCK_SIZE << ", got " << ctx->write_result << std::endl;
}
if (ctx->fsync_result != 0) {
write_all_success = false;
std::cerr << "Fsync failed at offset " << ctx->offset << ": "
<< strerror(-ctx->fsync_result) << std::endl;
}
}
bool read_all_success = true;
for (auto &ctx : read_ctxs) {
if (ctx->read_result != static_cast<ssize_t>(IO_BLOCK_SIZE)) {
read_all_success = false;
std::cerr << "Read failed at offset " << ctx->offset << ": expected "
<< IO_BLOCK_SIZE << ", got " << ctx->read_result << std::endl;
} else {
int block_num = ctx->offset / IO_BLOCK_SIZE;
char expected_char = 'A' + (block_num % 26);
for (size_t i = 0; i < IO_BLOCK_SIZE; ++i) {
if ((*ctx->buffer)[i] != expected_char) {
read_all_success = false;
std::cerr << "Data corruption at offset " << ctx->offset + i
<< ": expected " << expected_char << ", got " << (*ctx->buffer)[i]
<< std::endl;
break;
}
}
}
}
// statics
if (write_all_success && read_all_success) {
std::cout << "All IO operations completed successfully!" << std::endl;
std::cout << "Total IO operations: " << IO_COUNT * 2 << std::endl;
std::chrono::duration<double> elapsed = end_time - start_time;
std::cout << "Elapsed time: " << elapsed.count() << " seconds" << std::endl;
std::cout << "IOPS: " << static_cast<int>(IO_COUNT * 2 / elapsed.count()) << std::endl;
double throughput = (IO_COUNT * 2 * IO_BLOCK_SIZE) / (elapsed.count() * 1024 * 1024);
std::cout << "Throughput: " << throughput << " MB/s" << std::endl;
} else {
std::cout << "IO operations completed with errors" << std::endl;
}
}
private:
struct io_uring ring_;
unsigned int depth_;
};main 入口
int main(int argc, char *argv[]) {
const std::string test_file = "io_uring_test.bin";
unsigned int io_depth = 32;
if (argc > 1) {
try {
io_depth = std::stoul(argv[1]);
if (io_depth < 2) {
std::cerr << "IO depth must be at least 2, using default 32" << std::endl;
io_depth = 32;
}
} catch (const std::exception &e) {
std::cerr << "Invalid IO depth argument, using default 32: " << e.what() << std::endl;
}
}
std::cout << "Using IO depth: " << io_depth << std::endl;
int fd = open(test_file.c_str(), O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
std::cerr << "Failed to open file: " << strerror(errno) << std::endl;
return 1;
}
try {
UringIO uring_io(io_depth);
uring_io.simulate_user_rpc(fd);
} catch (const std::exception &e) {
std::cerr << "Error: " << e.what() << std::endl;
close(fd);
return 1;
}
close(fd);
return 0;
}2.5 运行结果与讨论
在上述程序中,我们故意设计了 4K 的顺序写 IO 模式。设置不同的深度,在一块 SATA SSD 上压测,结果如下。
| 队列深度 | 总操作数 | 耗时(秒) | IOPS | 吞吐量(MB/s) |
|---|---|---|---|---|
| 2 | 1,000,000 | 159.223 | 6,280 | 24.5332 |
| 4 | 1,000,000 | 81.0652 | 12,335 | 48.1865 |
| 8 | 1,000,000 | 71.1472 | 14,055 | 54.9038 |
| 16 | 1,000,000 | 67.4389 | 14,828 | 57.9228 |
| 32 | 1,000,000 | 63.9078 | 15,647 | 61.1233 |
| 64 | 1,000,000 | 53.269 | 18,772 | 73.3307 |
| 128 | 1,000,000 | 41.6389 | 24,016 | 93.8125 |
| 256 | 1,000,000 | 34.4474 | 29,029 | 113.397 |
| 512 | 1,000,000 | 33.1311 | 30,183 | 117.903 |
| 1024 | 1,000,000 | 30.0471 | 33,281 | 130.004 |
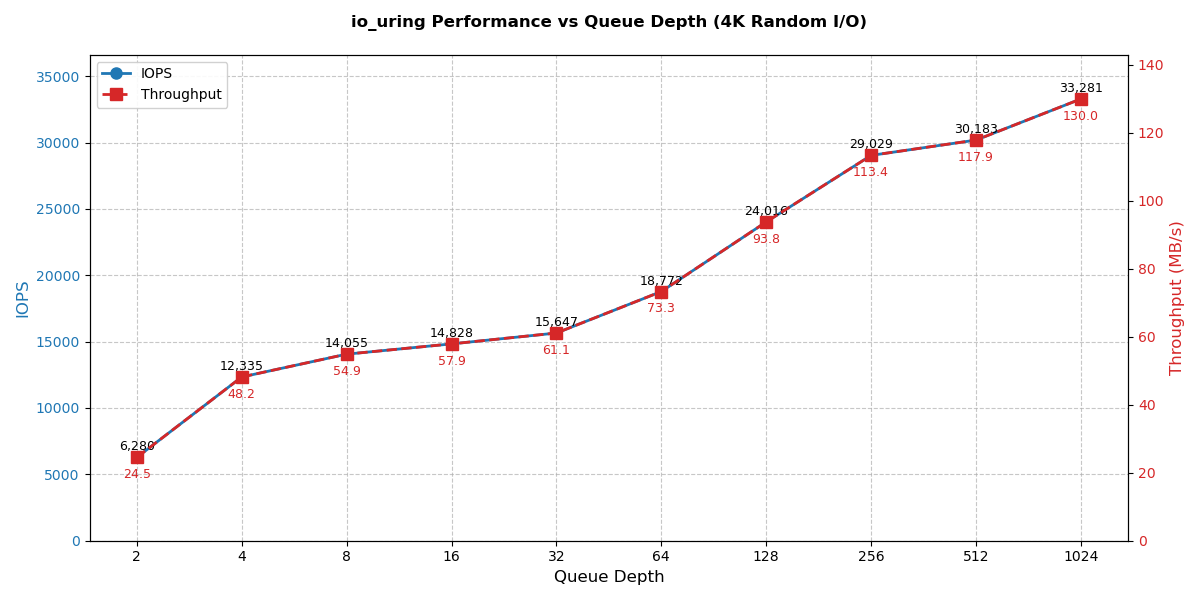
随着队列深度增加,IOPS持续提升(2→1024:6,280→33,281)。在128深度后提升幅度减小,512→1024 仅提升约 7%(图中 x 轴为 log 缩放)。我们的 4K 小 IO 顺序写,队列深度越大,系统的排队整流效应越好。
注意,这个例子只是为了简便,使用单线程操作 io,这不是必须的。设计者需要根据自己的需要合理安排线程模型(比如考虑使用的线程框架、rpc 框架,考虑 rpc+io 的 cpu 本地性等)。
3 Go 的磁盘 IO,同步 or 异步?
Go 的程序员视角看起来,无论收发网络请求,还是读写磁盘,runtime 已经包装成异步形式,自然地使用协程视角去统一处理,不必担心阻塞问题。既然我们已经理解磁盘 I/O 和网络 I/O 在系统调用上的不同,以及应对阻塞、提高效率的方法。那么 Go 语言是如何处理的呢?磁盘 IO 使用了 linux 的异步技术吗?
GMP 模型与磁盘 I/O 的交互:
- G(Goroutine):
表示一个Go程序的用户级线程,它包含了一个程序计数器和栈等信息。 - P(Processor):
代表一个逻辑处理器,负责调度和执行goroutine。每个P关联一个goroutine队列。 - M(Machine):
代表一个操作系统线程,负责实际的执行。一个M可以绑定一个P。
磁盘I/O流程:
-
当某个 goroutine 发起磁盘读写操作时,该 goroutine 会被分配到系统线程(M)上执行。由于同步 I/O 操作具有阻塞特性,会导致当前 M 进入阻塞状态。
-
为避免单个 M 的阻塞影响处理器(P)及其管理的其他 goroutine 的执行效率,Go 运行时系统会智能地进行资源重组:
- 在满足特定条件时(如 I/O 完成或超时触发)
- 运行时会将 P 从阻塞的 M 上解绑
-
同时,运行时系统会创建新的 M 并与解绑的 P 重新关联,确保该 P 能继续调度执行其他就绪的 goroutine,维持程序的并发性能。
-
当原始 M 完成 I/O 操作后:
- 首先尝试重新获取可用的 P 继续执行
- 若无法立即获取 P,则该 M 会转入空闲状态
- 被阻塞的 goroutine 在获得执行资源后会被重新调度
原来如此,其实算是一种我们熟悉的模式:同步 IO 线程池模型。核心思想是既然阻塞,就专门扔到一个线程池去做,IO 完成后原来的协程继续执行。在用户层面这个操作是 “异步” 的。
这种技术选择,往往和项目启动时的技术栈、可移植性等等很多因素有关,有些 issue8 也探讨了 Go io_uring 的可行性和收益。
Tokio 的阻塞处理
在 Rust 异步框架 Tokio 中,也是类似的思路。提供 tokio::task::spawn_blocking 接口,供用户将阻塞操作自行扔进专用线程池,避免阻塞整个 runtime。
use tokio::fs::File;
use tokio::io::AsyncWriteExt;
async fn write_file() -> std::io::Result<()> {
// tokio 框架自带的异步文件 IO
let mut file = File::create("foo.txt").await?;
file.write_all(b"Hello, Tokio!").await?;
// 如果必须用同步库(如std::fs)
tokio::task::spawn_blocking(|| {
std::fs::write("bar.txt", b"Blocking write").unwrap();
}).await?;
Ok(())
}4 小结
本文和读者一起,进入 Linux 异步 IO 的世界。
- 首先讨论了 disk io 为什么无法使用 epoll 技术 - 0.1 节
- 讨论了是否有必要非用异步 IO 不可 - 0.2 节
- 了解了 Linux AIO 的贡献和缺点 - 1 节
- 进入 io_uring 的世界,编写例程探索其 io 模式,分析性能指标 - 2 节
- 回过头来,了解了 Go 和 tokio 对磁盘 io 的处理思路 - 3 节
恭喜!我们终于漫步结束了单机 IO 的世界,这下终于听懂了存储开发者们对于单机 IO 的讨论、思路、关心点和术语。
接下来,稍作休整,我们即将正式进入分布式王国,考察和学习分布式存储的模式、思想、技术!
5 其他
本文没有讨论但值得调研的技术:
- 极致的性能需求,Storage Performance Development Kit (SPDK) 用户态存储技术。
- 线程模型:Reactor、Preactor、Run To Complete (RTC)、有栈协程和无栈协程。
- 磁盘 IO 调度:在不同线程下的磁盘 IO 分配、磁盘性能预测和限流、流量整形。
- 文件系统:ext4 与 xfs 对不同 IO 模型的性能比较。




可以看看这里的对比测试https://github.com/axboe/liburing/issues/536