基于 FAST 2002–2026 论文集,本文梳理了存储系统研究从文件系统、Flash/SSD 到 KV cache、checkpoint 与 model loading 的迁移轨迹,重点讨论 AI 时代哪些老问题被重新推回了舞台中央。
Table of Contents
本文共
14002字,阅读预计31分钟。
0. 前言
过去二十多年里,存储系统几乎经历了计算机系统里最完整的一轮“问题迁移”:从磁盘、RAID、文件系统、缓存,到 Flash、SSD、纠删码、云块存储,再到今天的 PMem、RDMA、CXL、LLM serving、向量检索与超大规模对象存储。整个论文集像一条压缩后的时间轴,社区每一阶段在关心什么,基本都写在了论文题目和摘要里。
这篇文章不做关键词词云,也把各种名词按年份排一遍。我们想回答三个问题:
- FAST 的主问题在 24 届会议里如何迁移?
- 哪些主题是“持续主线”,哪些只是阶段性爆发?
- 2026 的 FAST 呈现出的新信号,哪些是延续,哪些像拐点?
为了避免“先有观点、再找材料”,这篇文章的判断都尽量从论文集本身出发。我们先拉取并整理了本地可用的 FAST 2002–2005、2007–2026 论文集,去掉每年固定的 Proceedings/Editorship 条目,只保留正式论文;再基于标题、摘要和少量人工校对,把论文归到若干稳定的主题簇里,并补一层更细的语义标签,用来标记它主要改动的是哪一层存储机制、面向什么介质、什么场景。最后统一按年度占比而不是绝对篇数做趋势统计。
TL;DR 的一图流,笔者会保留下面这一张。它把这 24 届论文里最主要的问题迁移压到了一起:文件系统和 I/O path 始终都在,真正变化的是每个阶段把不同问题推到了舞台中央。
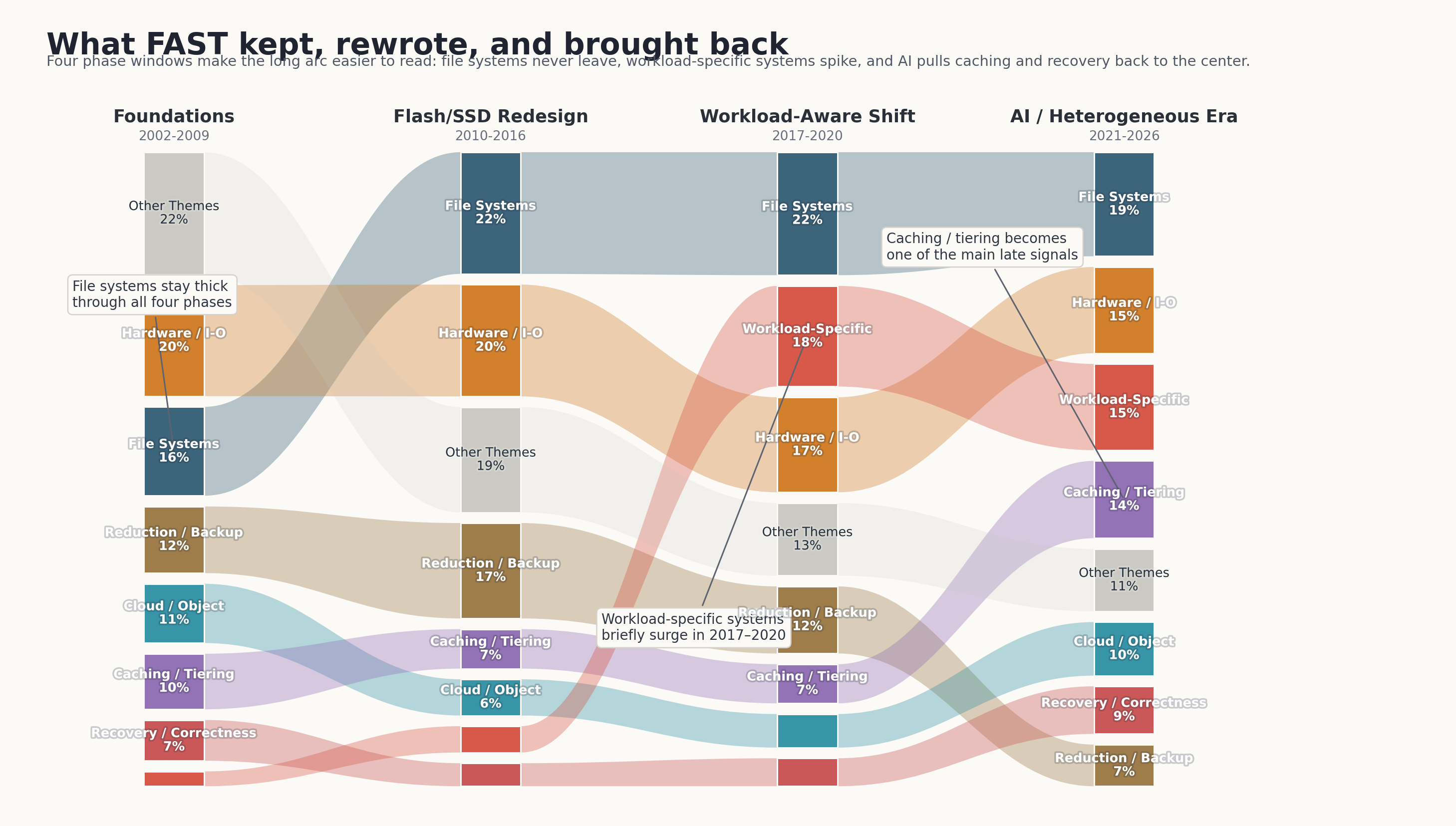
1. 我们是怎么分析这 609 篇论文的
为了让趋势图可读,我们没有直接做关键词词频,先把论文按“主要在改什么存储问题”归到若干大类里。当前使用的一级主题包括:
- 文件系统与命名空间(
File Systems/Namespace) - 存储硬件与 I/O 路径(
Storage Hardware/I-O Path) - 缓存、分层、放置与迁移(
Caching/Tiering/Placement) - 数据缩减、编码、备份与归档(
Data Reduction/Coding/Backup) - 分布式、云与对象存储(
Distributed/Cloud/Object Storage) - 可靠性、恢复、一致性与正确性(
Reliability/Recovery/Consistency/Correctness) - 安全、隐私与信任(
Security/Privacy/Trust) - 测量、诊断、benchmarking 与运维(
Measurement/Diagnosis/Operations) - 面向特定负载的存储系统(
Workload-Specific Storage) - 经验、回顾与反思(
Experience/Retrospective/Reflection)
除此之外,我们还给每篇论文补了一层更细的语义标签,用来描述它涉及的介质、系统层次和应用场景。这样做是因为 FAST 的很多变化,往往不是某个主题突然没了,更常见的是同一个主题里的问题换了。比如同样是缓存或 I/O path,早期讨论的可能是 RAID、磁盘阵列和块层路径;到了最近几年,讨论对象已经变成了 KV cache、checkpoint、model loading、RDMA、CXL、vector search 和面向 AI 数据路径的分层存储。这样看到的,不只是“AI 论文变多了”,也能看到“AI 在改写哪些老问题”。
从全体 609 篇论文的一级类分布看,最稳定的三大类是:
File Systems/Namespace:118篇Storage Hardware/I-O Path:110篇Data Reduction/Coding/Backup:73篇
紧随其后的,是:
Measurement/Diagnosis/Operations:64篇Caching/Tiering/Placement:60篇Workload-Specific Storage:59篇
这个总体分布标明:FAST 不只是“设备会议”或者“文件系统会议”。它覆盖抽象层、底层介质、工程实践和新型工作负载。 最近几年冒出来的 AI 信号,也没有把“AI 存储”抬成一个压倒性的独立大类;它们更多是散在缓存、恢复、文件系统和 I/O path 这些老类别里。这样看,比一句“AI 论文变多了”更接近 FAST 自己的结构。
2. 四个阶段:FAST 的问题意识是怎么迁移的
2.1. 2002–2009:基础存储系统问题占主导
在这 151 篇论文里,占比最高的几个主题是:
Storage Hardware/I-O Path:30篇,占19.9%File Systems/Namespace:24篇,占15.9%Data Reduction/Coding/Backup:18篇,占11.9%Measurement/Diagnosis/Operations:17篇,占11.3%Distributed/Cloud/Object Storage:16篇,占10.6%
这一阶段的 FAST 更像是在处理“存储基础设施本体”问题。社区关心的是 RAID、磁盘阵列、SAN fabric、文件系统、缓存、版本管理、benchmarking、安全共享、trace、故障与管理。
代表性的早期经典包括:
GPFS: A Shared-Disk File System for Large Computing Clusters.Venti: A New Approach to Archival Storage.ARC: A Self-Tuning, Low Overhead Replacement Cache.Plutus: Scalable Secure File Sharing on Untrusted Storage.Failure Trends in a Large Disk Drive Population.Write Off-Loading: Practical Power Management for Enterprise Storage.
今天回头看,这一时期有两个特征。
第一,文件系统从未是一个“已经解决了”的问题。无论是 The Direct Access File System,还是后来的目录扩展、metadata、日志、共享磁盘文件系统,FAST 从一开始就没有把文件系统当成成熟基础件。它一直被当成与硬件和应用共同演化的层。
第二,测量和运维很早就是 FAST 的显性主题。像 Hippodrome、Buttress、NFS trace、customer troubleshooting 这一类论文说明,存储研究并不是后来才变得“工业化”的;它从一开始就很强调 trace、部署、管理、问题定位,只是早期对象还不是今天意义上的云服务。
2.2. 2010–2016:Flash/SSD 把设计空间重写了一遍
这是整份语料里最容易被看成一个独立阶段的时期。在这 170 篇论文里,前三类分别是:
File Systems/Namespace:37篇,占21.8%Storage Hardware/I-O Path:34篇,占20.0%Data Reduction/Coding/Backup:29篇,占17.1%
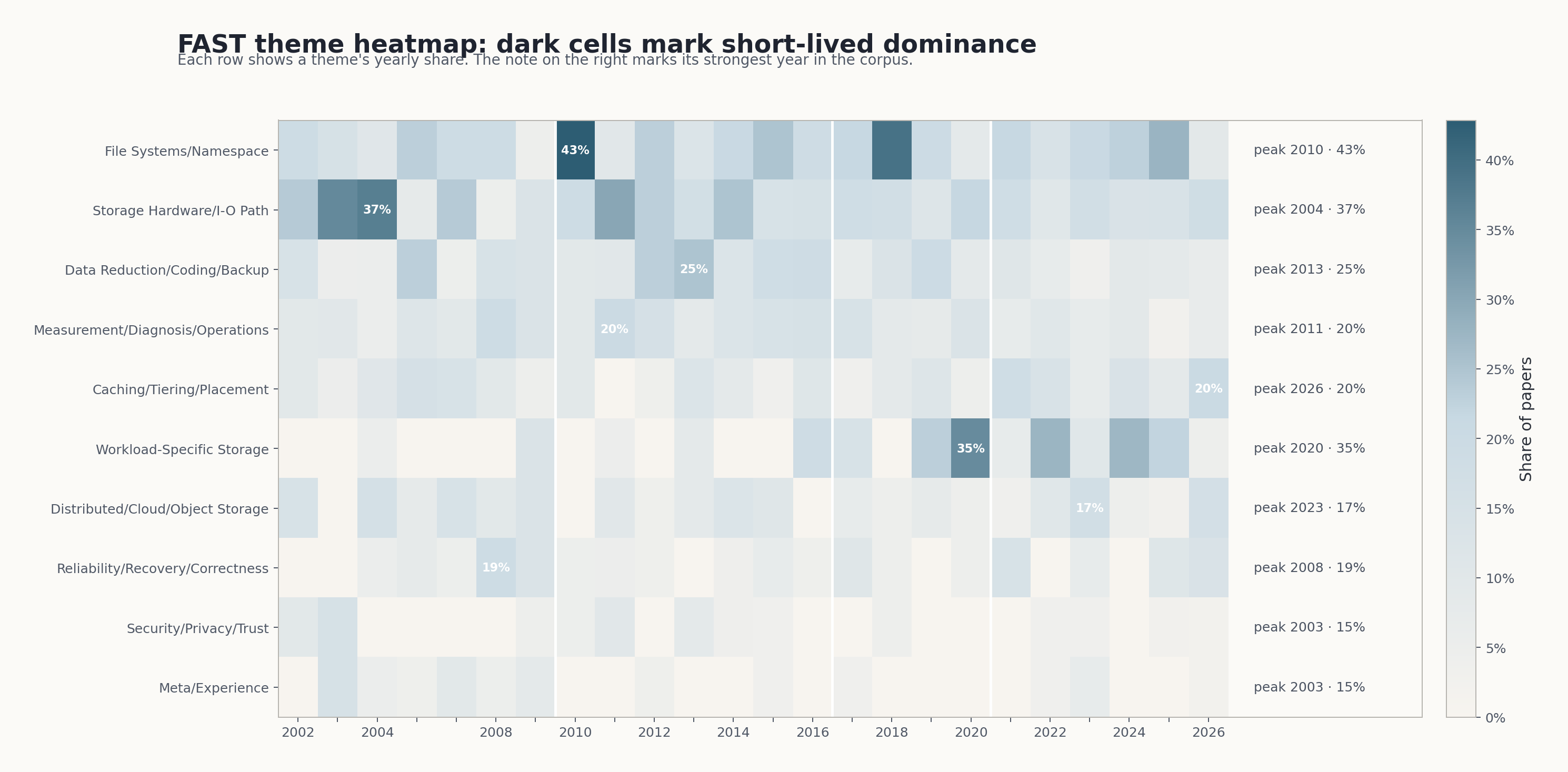
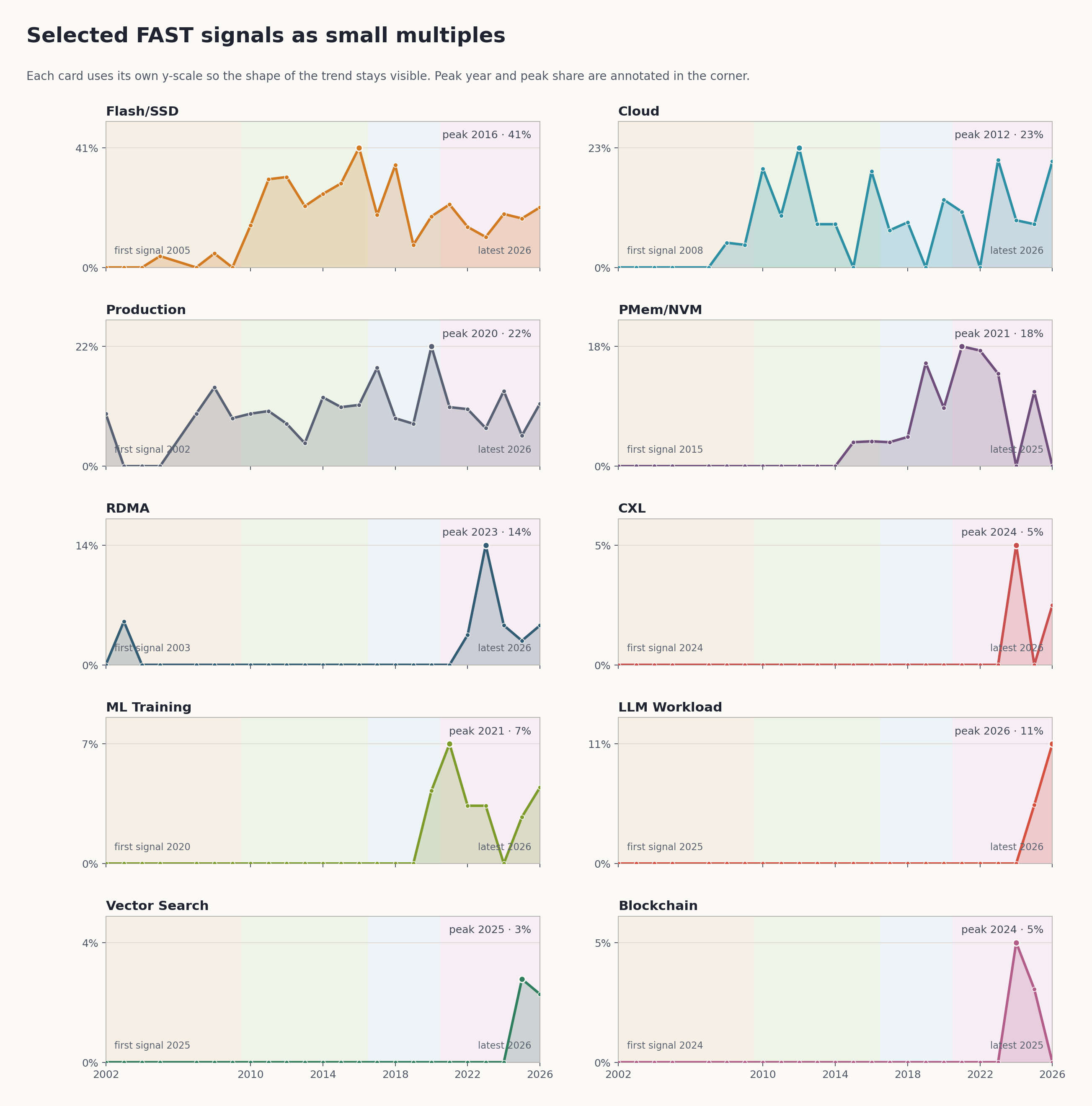
如果只看 secondary tags,flash_ssd 的年度占比在 2016 年达到峰值:11/27,约 41%。这几乎可以直接把 2010–2016 看成 FAST 的 Flash/SSD redesign era。
这一阶段的重点不在于“SSD 论文变多了”,而在于 SSD/Flash 迫使系统研究者重写了一批原本建立在磁盘假设上的设计原则。这体现在几个层面:
- 设备层:写放大、wear、GC、FTL、retention、lifetime management 成为显性问题
- 文件系统层:
NOVA、F2FS一类工作开始把介质属性直接写进文件系统设计 - 编码与容错层:云文件系统上的 erasure code 恢复代价被重新审视
- 运维与实证层:越来越多论文开始研究真实部署中的尾部行为、寿命、工作负载与故障模式
这一阶段值得单独点名的代表作包括:
The bleak future of NAND flash memory.CAFTL: A Content-Aware Flash Translation Layer Enhancing the Lifespan of Flash Memory based Solid State Drives.Avoiding the Disk Bottleneck in the Data Domain Deduplication File System.Rethinking erasure codes for cloud file systems: minimizing I/O for recovery and degraded reads.NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories.F2FS: A New File System for Flash Storage.The Tail at Store: A Revelation from Millions of Hours of Disk and SSD Deployments.
2002–2009 的 FAST 像一本“基础存储问题百科全书”;到了 2010–2016,讨论明显收束到一个问题上:介质彻底变化以后,原有软件栈哪些地方必须重写?
2.3. 2017–2020:从通用底座转向 workload-aware 与 service-aware
这 100 篇论文的主题分布开始出现明显变化:
File Systems/Namespace:22篇,占22.0%Workload-Specific Storage:18篇,占18.0%Storage Hardware/I-O Path:17篇,占17.0%Data Reduction/Coding/Backup:12篇,占12.0%
这个阶段最显眼的变化,是 面向特定负载的存储设计第一次成为 FAST 的前排主题。
例如:
BTrDB: Optimizing Storage System Design for Timeseries Processing.Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook.POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database.Quiver: An Informed Storage Cache for Deep Learning.
FAST 的重心也开始往前挪了一步。社区不再只问“一个通用存储结构怎样更快”,而开始更频繁地问:
- 面向某类 workload 的最佳数据路径是什么?
- 在云原生、分布式、多租户与计算存储环境里,存储应该如何协同上层系统?
- 性能之外,热点、隔离、公平性与调优复杂度要怎么处理?
同样在这段时期,pmem_nvm 在 secondary tags 里第一次明显出现,最早出现在 2015,并在 2021/2022 达到阶段高点。persistent memory 不是 2020 年后才突然进入 FAST,它在 2010 年代后半段就已经开始为新的系统抽象铺路。像 Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory. 这类工作也说明,PMem/NVM 进入 FAST 时带进来的不只是硬件信号,还有一致性语义、数据结构和恢复模型。
2.4. 2021–2026:AI 没有长成一个孤立新桶,它在重写缓存、恢复与数据路径
在最近的 188 篇论文里,主题结构已经和早期 FAST 有了非常明显的差异:
File Systems/Namespace:35篇,占18.6%Storage Hardware/I-O Path:29篇,占15.4%Workload-Specific Storage:29篇,占15.4%Caching/Tiering/Placement:26篇,占13.8%Distributed/Cloud/Object Storage:18篇,占9.6%
如果只看一级类,这一阶段当然已经比早期 FAST 更“服务化”和“应用化”。但从更细的标签往下看,AI/LLM 并没有简单地形成一个全新的大桶,它更多是在把 cache/tiering、checkpoint/recovery、page cache、GPU-adjacent file access 和 disaggregated data path 这些老问题重新拉回舞台中央。
从 AI 相关 secondary tags 上看,这个趋势更清楚:
llm_workload在2024还是0,到2025变成2/36,2026进一步升到5/44- 泛化的
kv_cache语义在更早年份就已经出现过,但如果只看 LLM-oriented 的这组论文,相关信号在2025开始明显成形,并在2026增长到2/44 checkpoint_snapshot在2026达到2/44model loading / startup path在2025已经能看到相邻信号,到2026才出现更明确、直接的论文对象data_pipeline_preprocessing在2026首次出现vector_search从2025开始出现,并在2026延续
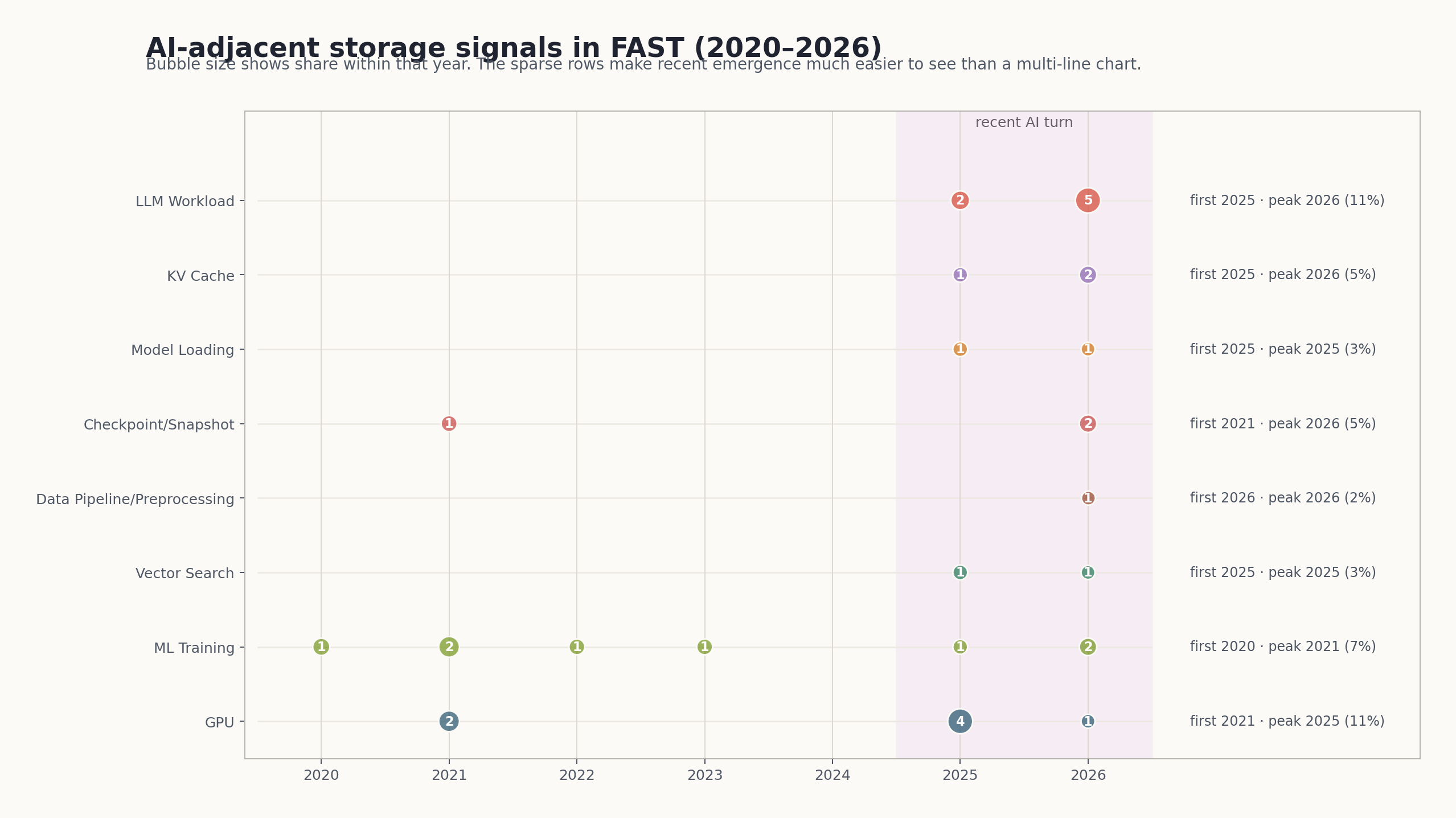
如果把这些标签和具体论文对起来看,最近两年的 AI 线索大致可以拆成几条比较清楚的存储路径。
先看 KV cache 这个新“存储对象”。
IMPRESS、Mooncake、Bidaw、CacheSlide、SolidAttention 这些论文讨论得都很具体:prefix KV、historical KV、host memory + SSD 两级存储、disaggregated KVCache、spill-aware KV reuse,以及在 memory-constrained 环境下如何减少 KV loading 代价。LLM 推理也因此把“缓存”和“分层”重新推回了 FAST 的中心。
按时间顺序看,这条线内部也已经开始分化。2025 的 IMPRESS 和 Mooncake 更偏向回答 prefix KV / global KVCache 怎么落盘、怎么分层、怎么服务化;到了 2026,Bidaw、CacheSlide、SolidAttention 已经进一步转向 interaction pattern、reuse policy、latency stability 和 memory-constrained deployment 这些更细粒度的问题。
再看 model loading 和 serving startup。
Accelerating Model Loading in LLM Inference by Programmable Page Cache 这一类工作说明,TTFT、冷启动、模型权重加载、SSD 带宽利用、page cache policy,已经开始成为推理系统里的核心性能对象。过去这类问题常被看成实现细节,现在它们更接近产品级 SLO 的决定因素。这条线在 FAST 里也不是突然冒出来的;像 FAST: Quick Application Launch on Solid-State Drives. 这样的更早工作,已经把“应用启动 / 数据就绪 / 介质速度”这条脉络提前写出来了。
训练侧的变化也很明显。“存储问题”已经从数据读写扩展到状态管理。
AdaCheck 和 GPU Checkpoint/Restore Made Fast and Lightweight 说明 checkpoint 已经不只是一个离线容灾动作,它在大规模训练里会直接影响可用性、恢复时间和资源利用率。与此同时,Seneca 这类工作又把训练数据预处理、cache partitioning、sampling 和 ingestion pipeline 拉成了新的性能瓶颈。
还有一点也很重要:AI 没有让传统层次退场,反而让它们重新变得重要。
最近几年同时还能看到 RDMA、CXL、Zoned UFS、disaggregated NVMe、GPU-aware file systems 这些方向继续增长。说白了,FAST 的主线并不是“AI 取代了存储”。更贴切的说法是,AI 让存储系统把老问题用新规模、新层次和新对象再做一遍。
归纳成一句话,FAST 最近几年的变化,不能只概括成“开始研究 AI 了”。AI 把缓存、恢复、文件系统和 I/O 路径重新推回了端到端数据通路的问题里。
3. “主题热度”之外的洞察
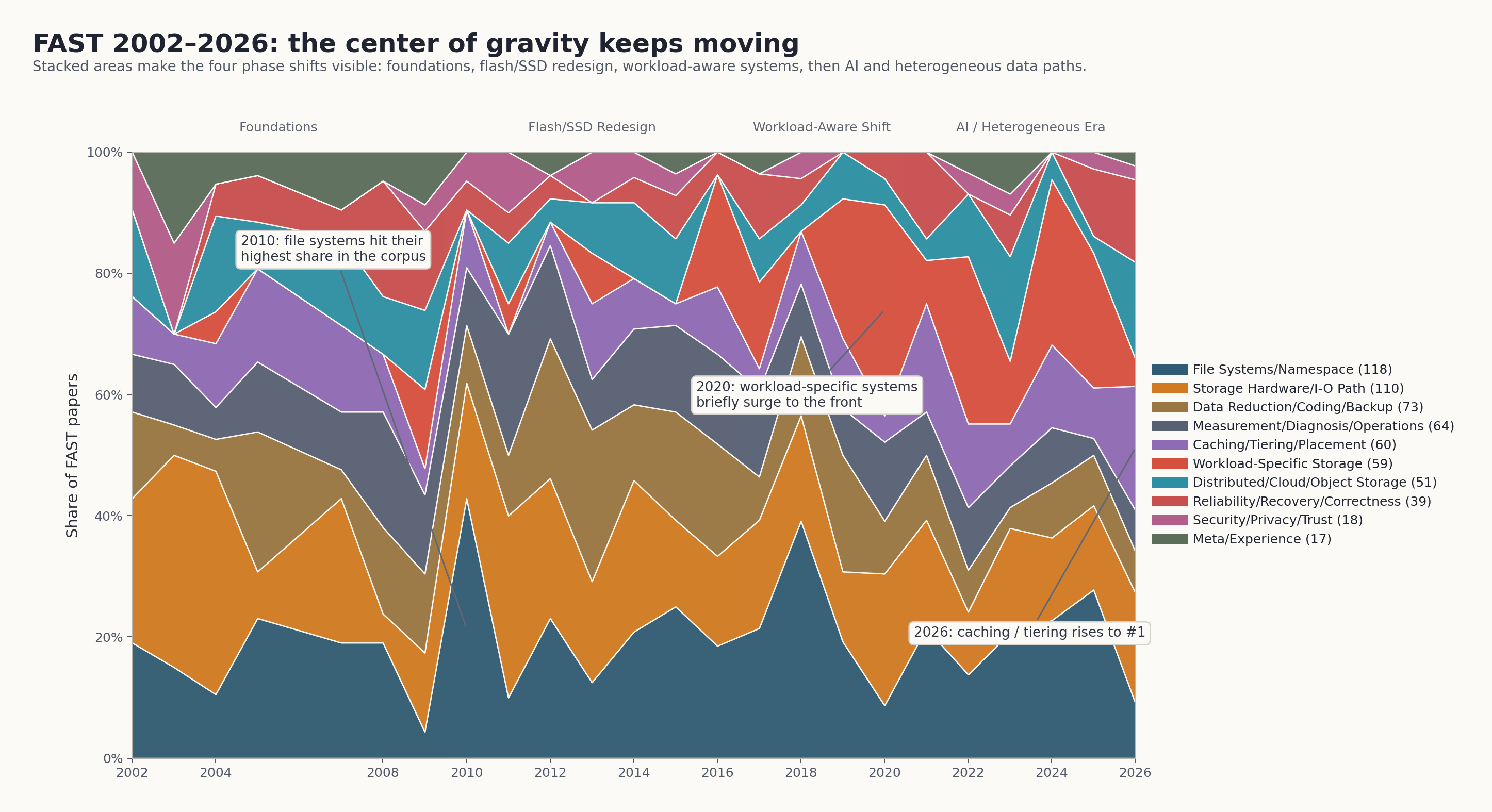
下面这张图换了一个角度:不看每年的占比,而看各主题在不同阶段的大致排名。哪些主题一直在前排,哪些只在某个阶段突然抬头,会比折线图更直观。
![]()
3.1. 文件系统并没有退场,它只是不断换了问题
如果只盯着 buzzword,很容易以为 FAST 后来被 Flash、PMem、CXL、LLM 抢走了舞台。但从分类结果看,File Systems/Namespace 依然是全体语料里最多的一级类:118 篇。
它还贯穿了所有阶段:
- 在 2002–2009,它是基础存储抽象的核心战场
- 在 2010–2016,它吸收了 Flash/PMem 带来的新约束
- 在 2017–2020,它和分布式、工作负载、云环境的边界不断重画
- 在 2021–2026,它依然是占比最高的一级类
FAST 有一条很深的主线:文件系统一直在吸收介质变化与服务化需求,并把它们重新表达为抽象层问题。
3.2. “存储硬件与 I/O path” 是另一条从未消失的底层主线
这类论文总数 110 篇,仅次于文件系统。它在早期主要意味着:
- RAID
- disk arrays
- SAN / Storage over IP
- firmware
- 低层 I/O stack
但到今天,这一类里面更多是:
- NVMe / io_uring
- PMem / hybrid memory
- RDMA / disaggregated access
- CXL
- Zoned UFS
- DPU / SmartSSD / offload path
可以说,“底层路径”始终是 FAST 的核心,只是研究对象已经从磁盘路径迁移到了异构数据通路。
3.3. 比“AI 形成新桶”更值得注意,它正在改写多个旧桶
如果只看 2017–2020,Workload-Specific Storage 的确是一个非常强的新信号:它在这一阶段有 18/100 篇,占 18%,说明 FAST 开始明显地从“通用底座优化”转向“为某类 workload 直接塑形”。
但如果把最近两年的论文再往下细看,会发现一个更有意思的现象:到了 2025–2026,很多最受关注的 AI 论文没有继续堆进 Workload-Specific Storage,更多分散到了:
Caching/Tiering/PlacementReliability/Recovery/CorrectnessFile Systems/NamespaceStorage Hardware/I-O Path
把 2020–2026 的 AI 相关论文单独拎出来,再看它们最后落在哪些一级类里,这件事会更直观。
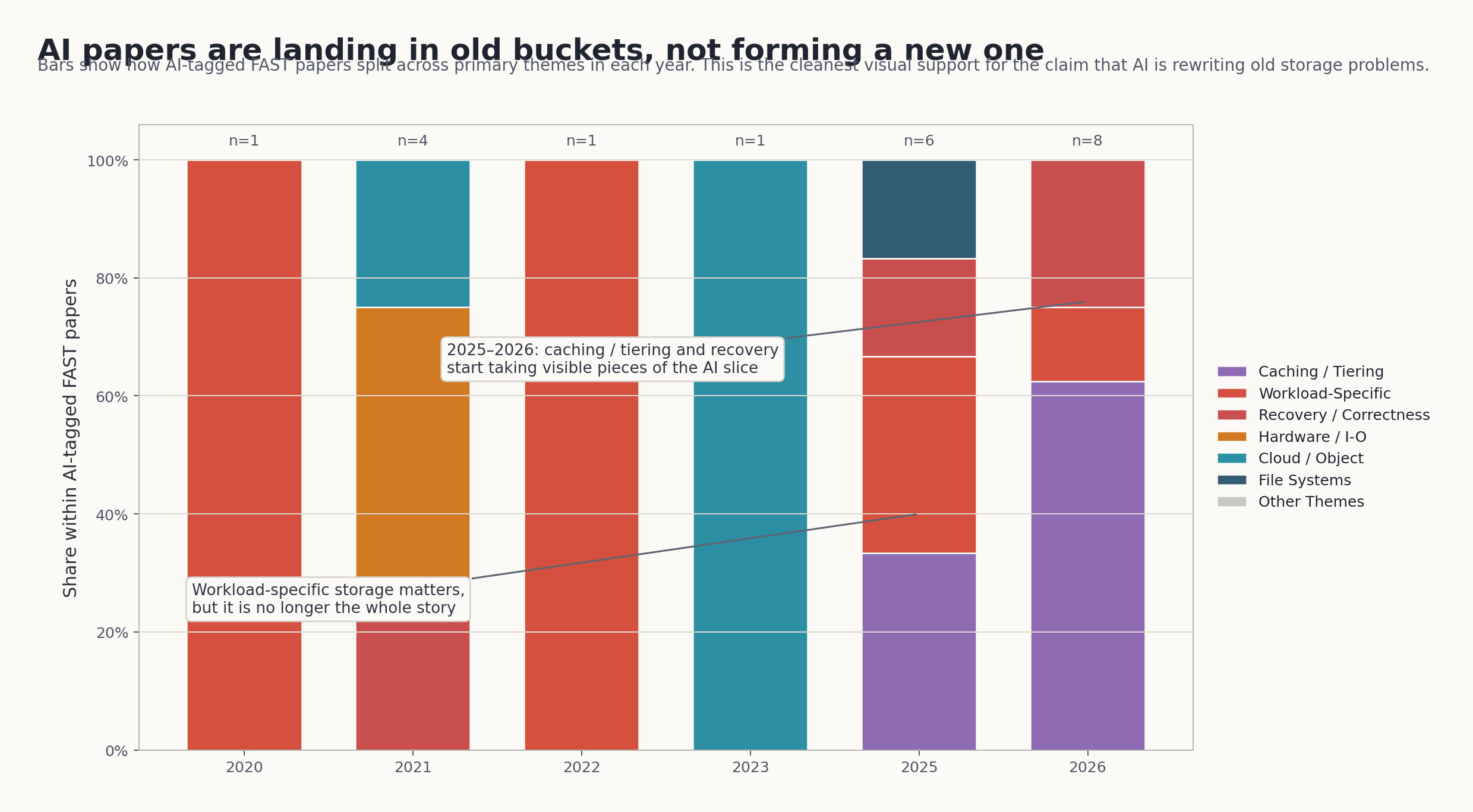
例如:
IMPRESS、Bidaw、CacheSlide、SolidAttention更像 cache/tiering 论文AdaCheck和GPU Checkpoint/Restore Made Fast and Lightweight更像 recovery/checkpointing 论文Accelerating Model Loading in LLM Inference by Programmable Page Cache本质上是在把推理启动问题翻译成 page cache 和 I/O 模板问题- 还留在
Workload-Specific Storage里的,更像OdinANN这种 workload data model 本身就决定存储结构的工作
FAST 最近几年最值得重视的变化,不只是“AI 论文越来越多”:AI 正在让缓存、分层、恢复、启动路径、文件系统接口这些经典存储问题长出新的语义。
3.4. 云与对象存储经历了两轮抬头,不是一条线性上升曲线
Distributed/Cloud/Object Storage 并不是一条平滑增长曲线。它在早期就已经存在,例如 wide-area file system、shared-disk cluster、SAN 和 secondary storage。然后在云时代,它再次获得新语义:从一般意义上的分布式存储,转向了对象存储、云块存储、超大规模服务化存储。
在今天的 FAST 里,云存储已经不是一个“外部背景”了,它就是论文自身的主要对象。像:
Pond: The OceanStore Prototype.What's the Story in EBS Glory: Evolutions and Lessons in Building Cloud Block Store.More Than Capacity: Performance-oriented Evolution of Pangu in Alibaba.ACOS: Apple's Geo-Distributed Object Store at Exabyte Scale.
这些论文说明,FAST 讨论的已经不只是“一个存储系统怎么设计”,也包括“一个全球级服务怎么演化、权衡和运营”。
3.5. 可靠性与安全仍然重要,但从舞台中央退到长期底线
在 FAST 早期,安全与信任相关论文的存在感非常强,Plutus、block-level security、secure provenance 等都具有很强代表性。
但从分类结果看:
Security/Privacy/Trust总计18篇Reliability/Recovery/Correctness总计39篇
它们并没有消失,现在更像 FAST 的“长期底线议题”:不会每年都成为主导浪潮,但每当新的介质、新的接口、新的服务形态出现,它们都会回来提醒社区哪些东西不能靠“性能提升”掩盖过去。
4. 2026:FAST 最新一届给了我们什么信号?
从 2026 主题快照 看,2026 年最突出的一级类是:
Caching/Tiering/Placement:9篇Storage Hardware/I-O Path:8篇Distributed/Cloud/Object Storage:7篇Reliability/Recovery/Correctness:6篇File Systems/Namespace:4篇Measurement/Diagnosis/Operations:3篇Data Reduction/Coding/Backup:3篇
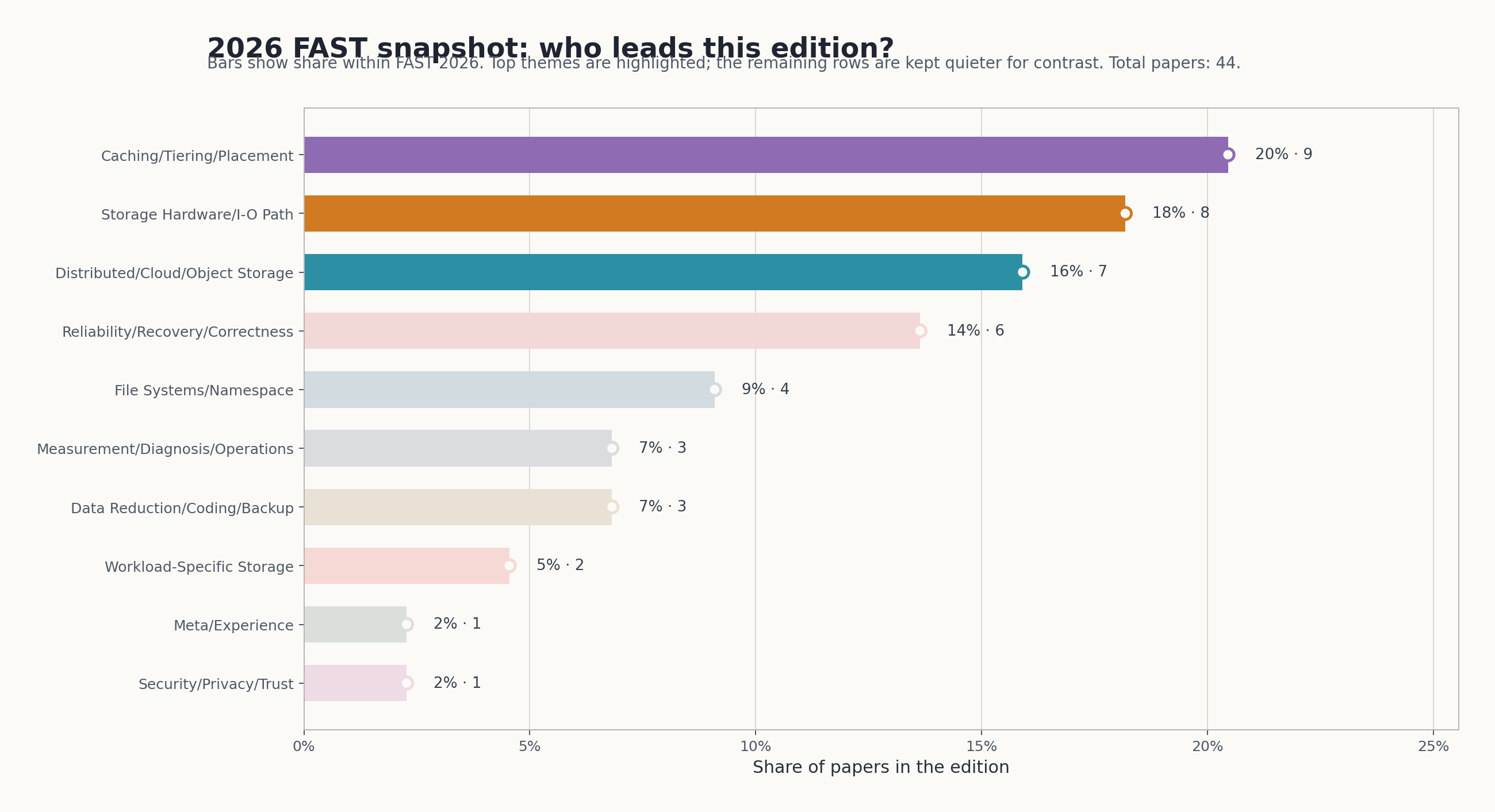
如果只用一句话概括 2026,大概会是:
FAST 2026 看起来不像一届“单独的 AI 存储专场”,而更像一届“AI 正在把缓存、恢复和数据路径问题重新推到舞台中央”的 FAST。
这个判断背后有几组非常具体的信号。
第一,LLM 的热点正在落到很具体的存储对象上。当前 2026 语料里:
llm_workload有5/44kv_cache有2/44checkpoint_snapshot有2/44model_loading有1/44data_pipeline_preprocessing有1/44
读者今天关心的那些问题,已经能在 FAST 里对应到明确的研究对象,而不只是一个泛化的 “AI” 标签。
第二,KV cache 已经成为 2026 值得重看的存储热点之一。
Bidaw、CacheSlide、SolidAttention 这几类工作都在讨论 host memory、SSD、spill、prefetch、reuse、latency/throughput tradeoff。过去 FAST 研究的是 ARC、flash cache、tiering;到了 2026,研究对象换成了 prefix KV、historical KV 和 interactive serving 的缓存路径,但问题语言仍然是典型的存储语言。
第三,推理加速开始显式地包含 model loading 和 startup path。
Accelerating Model Loading in LLM Inference by Programmable Page Cache 很有代表性:它不改模型本身,改的是 page cache policy、I/O template、SSD 带宽利用和兼容性。TTFT、cold start、权重加载延迟,已经从系统边角问题走到了 FAST 可以正面讨论的存储问题上。
第四,checkpoint / snapshot 正在从“后台保险丝”变成训练主路径的一部分。
AdaCheck 和 GPU Checkpoint/Restore Made Fast and Lightweight 都说明,训练时代的 checkpoint 不再只是离线保存一个副本,而是牵动在线恢复时间、冗余利用、资源占用和故障域的核心机制。也正因为如此,Reliability/Recovery/Correctness 在 2026 抬到了 6/44。
第五,云服务化存储和硬件路径并没有被 AI 挤掉。
ACOS 代表超大规模对象存储仍然是 FAST 的主战场;而 CXL、disaggregated NVMe、Zoned UFS、更激进的 I/O completion / userspace-kernel 协同,又提醒我们:AI 负载真正能跑起来,底下仍然需要一整套硬件与路径工程来托住。
4.1. 这可能预示着 FAST 接下来
如果把 2025–2026 的信号继续外推,我觉得未来几年最可能继续强化的是下面几条线:
KV cache / model state hierarchy会越来越像一个正式的存储层次问题,而不只是推理框架内部优化。checkpoint / snapshot会越来越在线化、选择性和 workload-aware,不会一直停留在统一的离线批处理动作上。model loading / startup latency / TTFT会继续进入存储论文的核心指标体系,因为它们已经直接影响可部署性和弹性扩缩容。AI不会让文件系统、对象存储和 I/O path 退场,反而会迫使这些基础层重新回答兼容性、隔离性、成本和多租户公平性的问题。
这也是 FAST 的一个长期特点:新问题不会替代旧问题,它会把旧问题重新拉回到新的规模、新的介质和新的负载上。
5. 放到更大的系统语境里看:FAST 与 OSDI / SOSP / EuroSys
如果只看 FAST,最近几年最强的变化来自 AI、异构硬件和服务化存储。把视野再放大一点,会发现这不是 FAST 单独发生的事。近几年的 OSDI、SOSP、EuroSys 也在朝相近的方向移动,只是切入问题的角度不一样。
这里不做跨会场的全量主题统计。我们把近几年的官方论文列表和 technical sessions 当作参照,做一个简要对比。对照范围包括 OSDI 2024–2025、SOSP 2023/2025、EuroSys 2024–2026。
5.1. AI 在主系统会场里出现得更早,也更偏向端到端服务系统
如果从主系统会场回看这波 AI 浪潮,一个比较清楚的起点是 SOSP 2023 的 PagedAttention / vLLM。那篇论文已经把 KV cache 写成了一个带分页语义的系统问题。到了 OSDI 2024,讨论又往上走了一层,像 Llumnix、DistServe、Parrot、ServerlessLLM,关注点已经不止是某一层缓存怎么放,还包括 prefill / decode 拆分、request migration、应用级数据流和启动时调度。
到了 2025 和 2026,这股信号就更直接了。OSDI 2025 的 NanoFlow,SOSP 2025 的 Pie、DiffKV、Aegaeon,以及 EuroSys 2025–2026 的 HCache 等工作,关心的已经是 speculative decoding、KV compaction、adaptive caching、cluster scheduling、memory overloading、multi-SLO serving 这些更接近在线服务的问题。
这和 FAST 形成了互补。FAST 把 AI 写成了存储对象和数据路径问题,主系统会场则把它写成了运行时、调度器和集群控制面问题。 前者更关心 KV cache、checkpoint、model loading 到底落在哪层存储机制里,后者更关心怎样把这些状态对象放进一个能跑在生产环境里的服务系统。
5.2. 内存分层、远端内存、CXL、资源池化,是 AI 之外另一条更底层的主线
如果把 AI 论文暂时放在一边,近几年的主系统会场还有另一条很稳定的线索:memory hierarchy 正在被重新画一遍。SOSP 2023 的 MEMTIS、CXL-SHM、Ditto,OSDI 2024 的 Atlas,OSDI 2025 的 FineMem、Tigon、EMT,再到 SOSP 2025 的 Demeter、Spirit,都围绕着 tiered memory、far memory、disaggregated memory 和资源池化展开。
主系统社区显然没有把“内存分层”看成一个已经定型的老题目。随着 CXL、far memory、disaggregated memory、device pooling 这些硬件和部署形态逐渐变成现实,内存、远端内存、存储之间的边界正在重新被系统软件定义。
这也解释了为什么 FAST 最近几年的 KV cache spill、model loading、checkpoint tiering 会突然显得这么关键。它们并不是凭空冒出来的“AI 存储小题目”,正好落在了整个系统领域都在重画的那条边界线上。
5.3. checkpoint / snapshot / recovery 正在从后台机制变成在线控制机制
如果只看 FAST,我们已经看到 checkpoint / snapshot 开始从训练容灾动作走向在线主路径。放到更大的系统语境里,这股变化还要再往前一步。OSDI 2024 的 Sabre 和 Beaver,EuroSys 2024 的 Pronghorn、SplitFT、Puddles,以及 SOSP 2025 的 PhoenixOS,都说明 snapshot、恢复和持久状态管理正在直接进入启动、迁移、热启动和训练连续性这些在线路径。
把这些和 FAST 里的 AdaCheck、GPU Checkpoint/Restore Made Fast and Lightweight 放在一起看,可以看得更清楚:checkpoint 不再只是“故障后留个备份”的后台机制,它正在启动、迁移、恢复、训练连续性和服务弹性之间来回流动,变成在线控制机制。
FAST 更擅长看到它在状态落盘、恢复路径和存储层次里的变化;OSDI、SOSP、EuroSys 更擅长看到它在服务连续性和系统编排里的变化。两边拼起来,才更接近这类问题今天的真实形态。
5.4. serverless 和云控制面,正在把存储问题继续上推
另一个值得注意的现象是,serverless 和云控制面正在变成 AI 与存储之间的重要连接层。OSDI 2024 的 ServerlessLLM 已经把低延迟 LLM inference 写成了 local checkpoint storage、multi-tier loading 和 startup-time scheduling 的联动问题,OSDI 2025 的 AFaaS 继续讨论 cold start 的端到端延迟来源。EuroSys 2025–2026 里也能看到 serverless cold start、resource pools 和 object storage replication 相关工作继续往前走。
这条线和 FAST 的关联非常直接。FAST 里最近变热的 model loading / startup path,并不只是在讲“权重怎么读更快”,它正在和云侧的弹性部署、serverless 启动、资源回收、多区域路由拼到一起。 在 FAST 里,model loading 还是一个数据路径问题;到了主系统会场,它已经越来越像控制面和服务编排问题的一部分。
5.5. 放在一起看,这几个会场的共同变化
把 FAST 和 OSDI / SOSP / EuroSys 放在一起看,最近几年的系统趋势不只是“AI 论文变多了”。
model state hierarchy正在成形。KV cache、checkpoint、model loading、retrieval cache、parameter/offloading state 正在变成明确的系统对象。memory / storage / network的边界正在变薄。CXL、far memory、disaggregation、GPU pooling、device pooling 让“数据放在哪一层”重新成为主问题。- 在线服务系统正在吞掉越来越多过去被看成后台机制的东西。恢复、启动、迁移、资源回收、SLO 管理,都开始直接决定 AI 系统的可用性和成本。
从这个角度看,FAST 并没有偏离系统主会场的大趋势;它只是站在更靠近状态对象和数据路径的位置,把这些变化翻译成了存储系统语言。OSDI、SOSP、EuroSys 则站在更靠近 runtime、cluster 和 cloud control plane 的位置,把同一波变化翻译成了服务系统语言。两边放在一起看,会比单看任一会场更完整。
6. FAST 这 24 届到底讲了什么故事?
如果把这 24 届 FAST 压缩成一句总判断,我更倾向于:
FAST 的主线,不能只概括成“存储越来越快”。更准确地说,存储研究的主语正在从设备与抽象层,逐步走向服务、数据路径和 workload-aware 的系统协同。
这条主线具体体现为:
- 早期,FAST 更关注存储基础设施本体:磁盘、RAID、文件系统、缓存、管理、benchmarks
- 中期,Flash/SSD 迫使社区重写一批设计原则
- 再往后,云服务、分布式系统和 KV/analytics 让存储从“机制优化”转向“部署与工作负载适配”
- 最近几年,AI 负载、异构硬件与超大规模服务化存储,又把 cache、checkpoint、model loading、disaggregated path 这些老问题重新推回中心
文件系统和低层 I/O path 从未离开主舞台。新问题一层层叠上去,但社区没有真正放弃基础层。AI 在 FAST 里最重要的作用,也不是发明一门全新学科。它更像是在逼着社区重新回答“缓存该怎么分层、checkpoint 该怎么做、page cache 该怎么配、数据路径该怎么铺”这些老问题。
7. 小结
AI 时代确实带来了新对象,但 FAST 擅长的,仍然是把这些新对象翻译成存储系统熟悉的语言:布局、缓存、索引、隔离、一致性、恢复、成本与路径。KV cache、checkpoint、model loading、训练数据预处理,进入 FAST,它们会被表达成存储系统几十年来反复处理的问题形式。




谢谢团子老师!这一篇真的很有启发性,刚开始接触ai infra存储相关问题的时候就感觉到很多问题与传统的工程问题有着共通之处,另外不知道老师对于论文的梳理和分类(比如图上的图表)是否有具体的指路?谢谢!
@millie 是的,在梳理过程中我也发现,本质的工程问题没有太大变化,是根据用户场景的变化选择合适的手段去满足用户的需求~
论文的梳理分类我是使用 codex 对原始的论文 pdf 和摘要做的过滤,中间的一些清洗和汇总 python 代码非常细碎,我感觉分享出来还需要读者费时间理解脚本内容,帮助不大。
推荐可以借助最新的 codex 或者 claude code 完成近年来顶会摘要的收集分类(很方便,提一个需求就可以去喝咖啡了)。
然后和高参数模型(claude opus 4.7/gpt 5.5)一起完成筛选、翻译、阅读。
阅读过程中列出自己的问题和不清晰的背景,和模型讨论论文中某些工程取舍。如同有了一个私人领域教练,这种模式效率非常高,很适合时间紧张时候快速完成领域知识的调研和学习~