本文面向中重度使用 LLM coding 并思考未来开发范式的工程师,以及构建大型商业项目的一人公司开发者。本文描述 BMAD v6 的工作机制、与传统敏捷开发的关系,以及人类在流程中的位置。以及笔者实际体验的一些感受。

一些澄清,本文:
- 不是商业广告和概念神化吹嘘制造焦虑的营销号
- 是一个一线工程师的完整体验 BMad 的主观报告
- 由笔者的见解思考为核心主导编写,AI 只是辅助格式和润色
- 会同时指出其可取之处与明显的局限
- 写于 BMad 版本 v6,该流程仍然在持续迭代中
Table of Contents
0. TL;DR
BMAD 是什么? 一套基于 Prompt Engineering 的 LLM 工作流编排框架,通过 Markdown/XML/YAML 定义 Agent 角色(PM、架构师、开发者等),在 AI IDE(如 Cursor)中按脚本执行敏捷开发全流程。它不是自主运行的多 Agent 系统,本质是一套 Prompt 模板库 + 文件协议,Agent 间靠人类手动切换和共享磁盘文件协作。
核心价值: 将"和 LLM 聊天写代码"从即兴对话升级为可重复的流程化工程——结构化的工作流脚本、跨会话的状态管理(sprint-status.yaml)、文档驱动开发、强制 TDD 反馈闭环,切实缓解了 LLM 生成代码不可控的问题。
实战体感: 笔者用 BMAD 从零开发了一个前端计算器项目。头脑风暴阶段表现出色,规划文档详尽专业;流程开销显著,token 消耗也大幅上升。
主要局限: (1) 机械模仿人类敏捷仪式——Scrum Master、Retrospective 等概念在 AI 场景下过于突兀;(2) 重量级流程只有在项目规模足够大时才划算;(3) LLM 同时充当开发者和测试者存在自我验证可信度问题,反而需要人类更强而非更弱的介入。
建议: BMAD 的工作流脚本和状态管理机制值得借鉴,但应根据项目规模裁剪流程、剥离纯仪式性组件,并在关键节点引入独立于生成 Agent 的验证手段。
1. BMAD 到底是什么
BMAD(Breakthrough Method of Agile AI Driven Development)是一套 基于 Prompt Engineering 的 LLM 工作流编排框架。其更多是 2024-2025 年间,随着生成式 AI 进入爆发期,由技术团队总结出的一套结合 Agile(敏捷开发) 的灵活性与 GenAI(生成式人工智能) 开发范式。
项目地址在: https://github.com/bmad-code-org/BMAD-METHOD
它的核心做法是:
- 用 Markdown + XML 定义一组"角色"(称为 Agent),每个角色配有 Persona(人设)、Menu(菜单)、Workflow(工作流)。
- 人类在 IDE(如 Cursor)中加载某个 Agent 的定义文件,LLM 会按照文件中的指令"扮演"该角色。
- 通过 YAML/XML 编写的工作流脚本,将 LLM 的行为约束为一系列有序步骤,每步有输入、输出和检查点。
截止当前 v6 版本(2026年2月末),BMAD 不是一个运行中的多 Agent 系统,而是一套 Prompt 模板库 + 文件协议。 所谓"多 Agent 协作",是人类在不同对话中加载不同的 Prompt 文件,由同一个 LLM 分别扮演不同角色。Agent 之间没有真正的进程间通信,它们通过人类手动切换上下文和共享磁盘上的 Markdown 文件来传递信息。
必须指出的是,BMad 本质上指一组编排文件,必须依赖于 AI Coding CLI/IDE(比如 Claude Code / Cursor)等。
1.1 核心组件
当使用 npm 在你的工程初始化后,会建立以下文件。
| 组件 | 路径 | 实际内容 |
|---|---|---|
| Core | _bmad/core/ |
配置加载、bmad-master 入口 Agent、Party Mode(多角色模拟对话) |
| BMM | _bmad/bmm/ |
模拟研发团队的 Agent 集合:PM、Dev、Architect、QA、SM、Analyst |
| TEA | _bmad/tea/ |
测试工程相关的工作流(ATDD、NFR 评估、测试审查) |
| CIS | _bmad/cis/ |
创意/头脑风暴引导工作流 |
| BMB | _bmad/bmb/ |
用于构建新 Agent / Workflow 的元工具 |
1.2 BMM 角色划分
BMM 模块中定义了以下 Agent,每个对应传统研发团队中的一个角色:
| Agent | 文件 | 对应角色 | 实际职责 |
|---|---|---|---|
| Analyst (Mary) | bmm/agents/analyst.md |
业务分析师 | 市场/领域/技术调研,产品 Brief 撰写 |
| PM (John) | bmm/agents/pm.md |
产品经理 | PRD 撰写与验证,Epic/Story 拆解,实现就绪检查 |
| Architect (Winston) | bmm/agents/architect.md |
系统架构师 | 架构文档,技术选型,实现就绪检查 |
| SM (Bob) | bmm/agents/sm.md |
Scrum Master | Sprint 规划,Story 文件创建,回顾 |
| Dev (Amelia) | bmm/agents/dev.md |
开发工程师 | 按 Story 执行 TDD,产出代码和测试 |
| QA (Quinn) | bmm/agents/qa.md |
测试工程师 | API/E2E 测试生成(轻量版,完整版见 TEA 模块) |
| Quick Flow (Barry) | bmm/agents/quick-flow-solo-dev.md |
全栈快速开发 | 跳过完整仪式,从 Spec 直接到实现 |
1.3 BMAD 流程
初始化好后,你的 AI IDE 就可以以 command 形式直接使用其中的流程了。
BMAD 全流程如下
| 阶段 | 角色 (Agent) | 用途与说明 |
|---|---|---|
| 1. 初始分析 | Analyst (Mary) |
市场与技术调研 分析用户痛点、竞品情况及技术可行性。将模糊的想法转化为结构化的产品简报。 |
| 2. 产品规划 | PM (John) |
定义产品规格 编写详细的需求文档(PRD),定义用户旅程和界面交互(UX)。这是后续所有工作的基石。 |
| 3. 技术架构 | Architect (Winston) |
系统设计 根据 PRD 设计技术架构,选择技术栈,设计数据结构和 API 规范。 |
| 4. 需求拆解 | PM (John) |
任务颗粒化 将大需求拆解为 Epic(史诗)和 Story(故事)。 实现就绪检查:确保所有文档一致且无冲突,准备进入开发。 |
| 5. 迭代规划 | SM (Bob) |
Sprint 启动 规划哪些 Story 进入当前迭代,并生成具体的 Story 文件(即开发工单)。 |
| 6. 开发实现 | Dev (Amelia) |
核心开发循环 (TDD) 读取 Story -> 编写失败测试 -> 编写代码 -> 测试通过 -> 提交。这是最核心的编码环节。 |
| 7. 代码审查 | Dev (Amelia) |
自我/交叉审查 检查代码质量、逻辑漏洞及是否符合 AC(验收标准)。(建议使用更高级模型进行此步) |
| 8. 测试验收 | QA (Quinn) TEA |
质量保证 生成 E2E 测试、集成测试,验证功能是否符合 PRD 和 Story 的要求。 |
| 9. 迭代回顾 | SM (Bob) |
流程改进 更新 Sprint 状态,回顾本轮迭代的问题(在 AI 流程中通常用于更新状态文件)。 |
1.4 极速模式
适用于独立开发者或简单任务,跳过繁琐仪式。
| 角色 (Agent) | 用途 |
|---|---|
| Quick Flow (Barry) |
全栈快速开发 跳过 PRD、Epic 拆解等步骤,直接从一句话需求开始,在一个会话中完成分析、设计、编码和测试。 |
2. 一个 Agent 是怎么工作的
以 Dev Agent(_bmad/bmm/agents/dev.md)为例,其文件内容是一段 XML,定义了:
- Persona: "Senior Software Engineer, Amelia",沟通风格是"Ultra-succinct, speaks in file paths and AC IDs"。
- Activation Steps: 加载配置 -> 读取 Story 文件 -> 按顺序执行 Task -> TDD 循环 -> 更新 Story 状态。
- Menu:
[DS] Dev Story(执行开发)、[CR] Code Review(执行审查)等。
当人类在 Cursor 中激活这个 Agent 时,LLM 会:
- 读取
config.yaml获取项目名、语言等配置。 - 展示菜单,等待人类选择。
- 人类选择
[DS]后,LLM 加载dev-story/workflow.yaml,进而加载instructions.xml——一个 400 行的 XML 脚本,定义了 10 个步骤的完整开发流程。
这些步骤包括:查找 sprint-status.yaml 中 ready-for-dev 的 Story -> 读取 Story 文件 -> 写测试 -> 写代码 -> 跑测试 -> 标记完成 -> 更新状态为 review。
其余的角色,以此类推。其实 BMad 的存在形式不是自主运行的 Agent,而是一份极其详细的 SOP(标准操作流程),AI IDE 才是 agent,按照脚本逐步执行。 其"智能"程度取决于 LLM 对这份 XML 脚本的理解和遵循能力。
3. 新项目实战体验
笔者假想了一个项目需求,烧了不少 token,和大家一起从头到尾完整体验 BMad 开发流程。
项目源码放在:github.com/sptuan/erasure-lab
本次涉及的流程如下:
人类输入 (docs/init_idea_by_human_instruct.md)
↓ 16 行的产品想法
Analyst Agent → 市场/领域调研 (workflows/1-analysis/)
↓
PM Agent → PRD 文档 (_bmad-output/planning-artifacts/prd.md)
↓ 人类审核
Architect Agent → 架构文档 (planning-artifacts/architecture.md)
↓ 人类审核
PM Agent → Epic + Story 拆解 (planning-artifacts/epics.md)
↓ 人类审核
PM Agent → 实现就绪检查 (implementation-readiness-report.md)
↓
SM Agent → Sprint 规划 (sprint-status.yaml)
↓
SM Agent → 逐个创建 Story 文件 (implementation-artifacts/1-1-xxx.md)
↓
Dev Agent → 执行 TDD → 产出代码 + 测试 (src/ + tests/)
↓ 状态变为 review
Dev Agent → Code Review
↓
SM Agent → 回顾 (可选)3.1 原始需求
笔者基于分布式存储开发人员背景,假想一个需求如下。将需求描述文件放入 docs 文件夹。
### 背景
在分布式存储系统中,有多种编码方式。比如 多副本 编码, EC 编码,LRC 编码。
运营人员和开发人员常常为了选择编码类型烦恼,缺少直观认知。
比如 EC(4,2) 和 EC(6, 3) 相比,虽然副本率同为 1.5x,但是EC 6 3 能容忍更多节点失效,缺点是写文件多个 io。
根据副本数、编码数、校验码数、local码数的不同,表现不同的副本率、容忍度,IO 能力
### 一句话需求
现在,需要创建一个可视化的 web 程序。辅助人员直观认识各个编码的长处和短处。
这个 web 程序可以单体即可,富交互,结果直观,符合专家级分布式存储开发人员的认知。且能够迁入到其他网页中。3.2 初始阶段
提供了如下功能,我重点使用了其头脑风暴功能。
| 功能模块 | 具体功能 | 命令 | 作用与价值 |
|---|---|---|---|
| 头脑风暴 | 头脑风暴 (Brainstorming) | /bmad-brainstorming /bmad-cis-brainstorming |
项目分析向:由业务分析师引导,针对项目背景进行结构化发散。 创意激发向:由头脑风暴教练引导,使用 SCAMPER 等技巧突破思维定势。 |
| 深入调研 | 市场调研 (Market Research) | /bmad-bmm-market-research |
分析竞品与现状,洞察运维/开发人员的痛点与趋势。 |
| 领域调研 (Domain Research) | /bmad-bmm-domain-research |
深挖分布式存储编码(EC, LRC)专业术语与算法细节。 | |
| 技术调研 (Technical Research) | /bmad-bmm-technical-research |
评估可视化库、单体架构及嵌入式兼容性等技术方案。 | |
| 策略创新 | 创新策略 (Innovation Strategy) | /bmad-cis-innovation-strategy |
寻找产品差异化切入点,探索独特的价值主张。 |
| 设计思维 (Design Thinking) | /bmad-cis-design-thinking |
利用同理心图谱等工具,精准捕捉专家级用户的交互体验需求。 | |
| 问题解决 (Problem Solving) | /bmad-cis-problem-solving |
针对复杂逻辑(如IO与容错的权衡展示)提供系统化解决框架。 | |
| 定义规划 | 创建简报 (Create Brief) | /bmad-bmm-create-product-brief |
将“一句话需求”转化为结构化的产品定义文档。 |
| 多智能体研讨 (Party Mode) | /bmad-party-mode |
召集产品、架构、设计等多角色智能体进行全方位思维碰撞。 |
3.2.1 头脑风暴
头脑风暴阶段,Agent 严格根据 BMAD 提供的流程文件,采用一问一答的渐进对话形式,由人类重点参与,发散思维收集所有好玩的想法。
- 初始化与配置 (Initialization & Config Loading): 系统首先加载项目配置文件,明确项目名称、输出路径及参与者信息,并自动生成当前时间戳,为后续的文档记录和环境设定打下基础。
- 会话设置与问题定义 (Session Setup & Elicitation): 通过执行 step-01-session-setup.md 和高级启发任务,界定具体的头脑风暴目标,并加载特定的创意技术(如从 CSV 文件中读取方法),确保在进入生成模式前达成共识。
- 生成式探索与发散 (Generative Exploration & Divergence): 严格执行“反偏见协议”,通过每 10 个想法强制切换一次创意维度(如从技术转向商业或边缘案例),保持思维的异质性,以冲破前 20 个平庸想法,冲击 100 个以上的高质量创意目标。
- 动态记录与迭代 (Append-only Document Building): 采用微文件架构进行增量式记录,通过对话不断追加想法到 Markdown 模板中,在保持发散模式的同时实现过程的数字化追踪,直到满足数量目标或触发结束检测。
最终笔者完成对话得到一份头脑风暴报告。说实话,整个的效果比预期的好,迸发出好多好玩的想法。
实际报告很长,总结如下
该方案旨在构建一个**“可探索式技术文章(Explorable Explanations)”**形态的专业工具,将复杂的存储编码理论转化为直观的交互体验。
#### 1. 核心设计哲学
* **第一性原理建模:** 深入挖掘空间代价、修复读放大、尾延迟(P99)及 Markov 链持久性概率等 20 个本质维度,突破表层参数。
* **“公式透明”原则(Show Your Math):** 所有计算结果均附带动态公式面板,数值随参数滑动实时联动,确保逻辑对专家级用户透明。
* **跨界视觉隐喻:** 借鉴游戏 RPG 属性面板对比方案优劣,利用医学断层扫描式透视数据层级,引入金融帕累托前沿识别最优编码。
#### 2. 核心功能矩阵 (P0 级)
* **交互式计算器:** 通过滑块调节参数,实时生成容量条、IO 扇出图与六维雷达图。
* **故障模拟器:** 支持手动“杀死”节点,视觉化演示数据安全状态(绿/黄/红)及修复流量走向。
* **持久性推导:** 基于 AFR/MTTR 自动计算“几个 9”,并提供完整的数学推导路径。
#### 3. 产品形态与工程建议
采用 **PWA(离线可用)** 技术,支持 iframe 嵌入,界面采用符合工程师审美的等宽字体与暗色主题,实现“阅读中操作,操作中理解”的沉浸式决策支持。笔者个人觉得这个头脑风暴很好用。在此阶段很值得使用高参数的 LLM 比如 Claude Opus。因为 LLM 的领域知识实在太广了,很容易给出好玩的想法。
3.3 产品规划阶段
根据头脑风暴和需求,生成 PRD 文档。
3.3.1 PRD 生成
该过程的 BMAD 描述文件基于严苛的步骤文件架构 (Step-file Architecture),强调纪律性与顺序性:
- 配置与角色对齐: 读取主配置文件,AI 切换为“产品经理促进者”身份,与专家用户协作进入“从零创建”模式。
- 即时指令加载 (JIT): 严格禁止预载后续步骤,每次仅将当前步骤文件载入内存,确保指令执行不发生偏移。
- 顺序强制执行: 必须完整阅读并按编号顺序完成任务,严禁跳步、合并或自行优化流程。
- 状态追踪与追加: 在文档 Frontmatter 中实时更新
stepsCompleted进度,通过“仅追加”模式逐步构建完整的 PRD 文档,且在每个决策菜单处必须停顿等待用户指令。
最终,笔者得到一份非常长和详尽的 PRD。有兴趣的话可参考工程中的 bmad_output。
3.3.2 UI/UX 生成
如果产品前端比较重要,可以进行此步骤,会生成一个非常详细的 UX 风格设计文档和规范。
根据笔者观察,此阶段也会产生一些前端技术选型的建议和参考。供后续架构设计使用。
3.4 技术设计阶段
3.4.1 技术架构生成
下面是流程文件总结。
该过程严格遵循协作式探索与微文件架构,旨在确保 AI Agent 在实现过程中的技术一致性:
- 角色对齐与伙伴关系: AI 定位为“架构促进者”,与用户(领域专家)以平等合伙人身份协作。通过结构化思维与产品愿景的结合,共同制定决策以防止开发冲突。
- 微文件执行架构: 采用极其自律的执行模式。每个步骤均为包含嵌入式规则的独立文件,严格禁止在当前步骤未获得用户明确批准或“继续”指令的情况下跨越到后续文件。
- 环境初始化与配置: 从核心配置文件加载项目元数据(如项目名称、规划产出物、用户等级等),并锁定输出路径与架构决策模板(Architecture Decision Template),确保输出符合预设的语言风格。
- 循序渐进的增量构建: 采用“仅追加(Append-only)”模式构建文档,通过对话实时追踪并记录在 Frontmatter 中的文档状态,确保从
step-01-init.md开始的每一步发现都得到精确执行。
笔者得到的详细技术方案精髓如下:
本架构文档(ADD)定义了一个高性能、纯前端的分布式存储计算器(**ec-calc**),旨在通过“可探索解释”模式科普纠删码(EC)原理。
### 核心技术栈
* **基础框架**: Vite 6 + React 19 + TypeScript (追求极致 HMR 与运行时性能)。
* **状态管理**: **Zustand** (采用原子化 Selector 模式,确保渲染响应 < 16ms)。
* **UI/视觉**: Tailwind CSS v4 + Shadcn UI + Recharts (SVG 渲染 + 响应式布局)。
* **数学引擎**: KaTeX (同步公式渲染) + 纯函数计算逻辑 (100% 单元测试覆盖)。
### 关键架构决策
1. **严格分层 (Boundary)**:
* `src/engine/`: 纯数学逻辑,严禁依赖 React 或 UI。
* `src/store/`: 唯一处理业务逻辑与计算触发的场所。
* `src/components/`: 仅负责数据展示与 Action 触发。
2. **数据流与持久化**:
* **配置共享**: 关键参数同步至 **URL Hash**,实现无后端状态分享。
* **离线优先**: 通过 `vite-plugin-pwa` 实现 PWA 支持与 Service Worker 缓存。
3. **性能保障**:
* 禁止在组件内使用 `useEffect` 处理派生状态。
* 通过 Zod 进行输入校验,防止无效参数导致计算引擎崩溃。
### 目录结构
采用**分层优先**策略,将 `engine/`、`store/`、`components/` 与 `content/` (MDX 文档) 彻底解耦,确保逻辑的可测试性与 UI 的可替换性。完整定义了技术栈和关键的技术决策。后续的开发都会严格遵循这个架构设计。
3.4.2 epic 和 story 生成
类似于人类开发的流程,根据 prd 和技术文档,生成对应的 epic 和 story。
该过程严格遵循步骤文件架构 (Step-file Architecture),旨在将 PRD 与架构决策转化为可落地的开发规格说明:
- 角色定位与合伙制: AI 扮演“产品战略家与技术规范撰写者”,与作为“产品负责人”的用户平等协作。核心任务是将产品愿景拆解为具备完整验收标准(AC)的可执行故事。
- 微文件纪律执行: 采用极其严格的单文件加载机制。严禁预载未来步骤,必须在完成当前步骤的编号序列、处理完所有菜单停顿并获得用户明确的“继续”指令后,方可推进。
- 状态与增量构建: 坚持“仅追加”原则生成文档,通过在 Frontmatter 中实时更新
stepsCompleted数组来精准追踪进度,确保每一阶段的产出都具备可追溯性。
3.5 实施阶段
在 PRD、Architecture 和 Epics 都完成之后,项目将从 Solutioning 进入 Implementation。
这个阶段的核心是"Sprint Planning"以及随后的"Story Development Loop"(故事开发循环)。
3.5.1 准备阶段
在正式写代码之前,需要确保所有规划文档已经对齐且准备就绪。
Check Implementation Readiness (IR)
- Command:
/bmad-bmm-check-implementation-readiness - 目的: 这是一个“闸门”步骤。它会验证 PRD、UX、Architecture 和 Epics 是否一致且完整。
- 产出:
readiness-report.md。只有通过此检查,才能确保开发过程中不会因为需求不清而返工。
Sprint Planning (SP)
- Command:
/bmad-bmm-sprint-planning - 目的: 初始化开发计划。它会读取所有的 Epics 和 Stories,生成一个用于追踪进度的状态文件。
- 产出:
_bmad-output/implementation-artifacts/sprint-status.yaml。- 这个文件是实施阶段的“仪表盘”,记录了每个 Story 的状态(Pending, In Progress, Done)。
3.5.2 开发迭代循环
这是开发阶段的核心。人类需要按照 Story 为单位,重复执行以下步骤,直到所有功能开发完成。
Create Story -> Validate Story -> Dev Story -> QA -> Code Review -> Done
笔者是一个前端项目,需要也必须人类在环去参与 review 和 test。体验产品有问题,需要反馈给 Dev Story 修正并测试。
Create Story (CS) - 故事细化
- Command:
/bmad-bmm-create-story - 操作:
- 系统会自动从
sprint-status.yaml中选取下一个待办的 Story。 - 它会结合 PRD、Architecture 和 Epics 中的相关信息,生成一个详细的 Story 规格说明书。
- 系统会自动从
- 目的: 将高层级的需求转化为开发者(Agent)可以直接执行的详细指令,包含具体的 Acceptance Criteria (AC) 和技术上下文。
- 产出:
_bmad-output/implementation-artifacts/story-[id].md(例如story-1.md)。
Validate Story (VS) - 规格验证
- Command:
/bmad-bmm-create-story(通常在 Create Story 后自动询问是否验证,或再次运行以验证) - 目的: 确保生成的 Story 规格说明书没有遗漏,且逻辑自洽。
- 产出: 验证报告。如果验证不通过,需要修正 Story 文件。
Dev Story (DS) - 代码实现
- Command:
/bmad-bmm-dev-story - 操作:
- Agent 读取
story-[id].md规格书。 - Agent 编写代码、创建文件、修改配置。
- Agent 运行初步的测试以确保代码能跑通。
- Agent 读取
- 目的: 完成 Story 的实际编码工作。
- 注意: 这是一个高强度的编码环节,Agent 可能会多次修改代码。
QA Automation (QA) - 自动化测试 (可选但推荐)
- Command:
/bmad-bmm-qa-automate - 目的: 为刚刚实现的功能生成自动化测试(如 E2E 测试或 API 测试)。
- 产出: 测试代码文件。
Code Review (CR) - 代码审查
- Command:
/bmad-bmm-code-review - 操作:
- Agent 会扮演“审查者”角色,对比代码实现与
story-[id].md的要求。 - 检查代码风格、潜在 Bug 和架构一致性。
- Agent 会扮演“审查者”角色,对比代码实现与
- 分支路径:
- 未通过: 返回 Dev Story (DS) 步骤修复问题。
- 通过: 更新
sprint-status.yaml,将该 Story 标记为Done。
Retrospective (ER)
- Command:
/bmad-bmm-retrospective - 目的: 在一个 Epic 完成或 Sprint 结束时运行。总结经验教训,更新项目记忆(Project Context),以便在后续开发中避免犯同样的错误。
3.5.3 操作流概览
- 运行
/bmad-bmm-sprint-status确认下一个任务。 - 运行
/bmad-bmm-create-story生成任务详情。 - 运行
/bmad-bmm-dev-story让 Agent 写代码。 - 运行
/bmad-bmm-code-review检查代码。 - 如果通过,回到第 1 步;如果不通过,回到第 3 步。
3.6 产出物总结和效果概览
本项目中,BMAD 实际生成了以下文件结构:
_bmad-output/planning-artifacts/: PRD、架构文档、UX 设计、Epic 列表、实现就绪报告——共 6 个文件。_bmad-output/implementation-artifacts/: 23 个 Story 文件 + 1 个sprint-status.yaml。src/和tests/: Dev Agent 产出的实际代码。
前端项目的预览如下
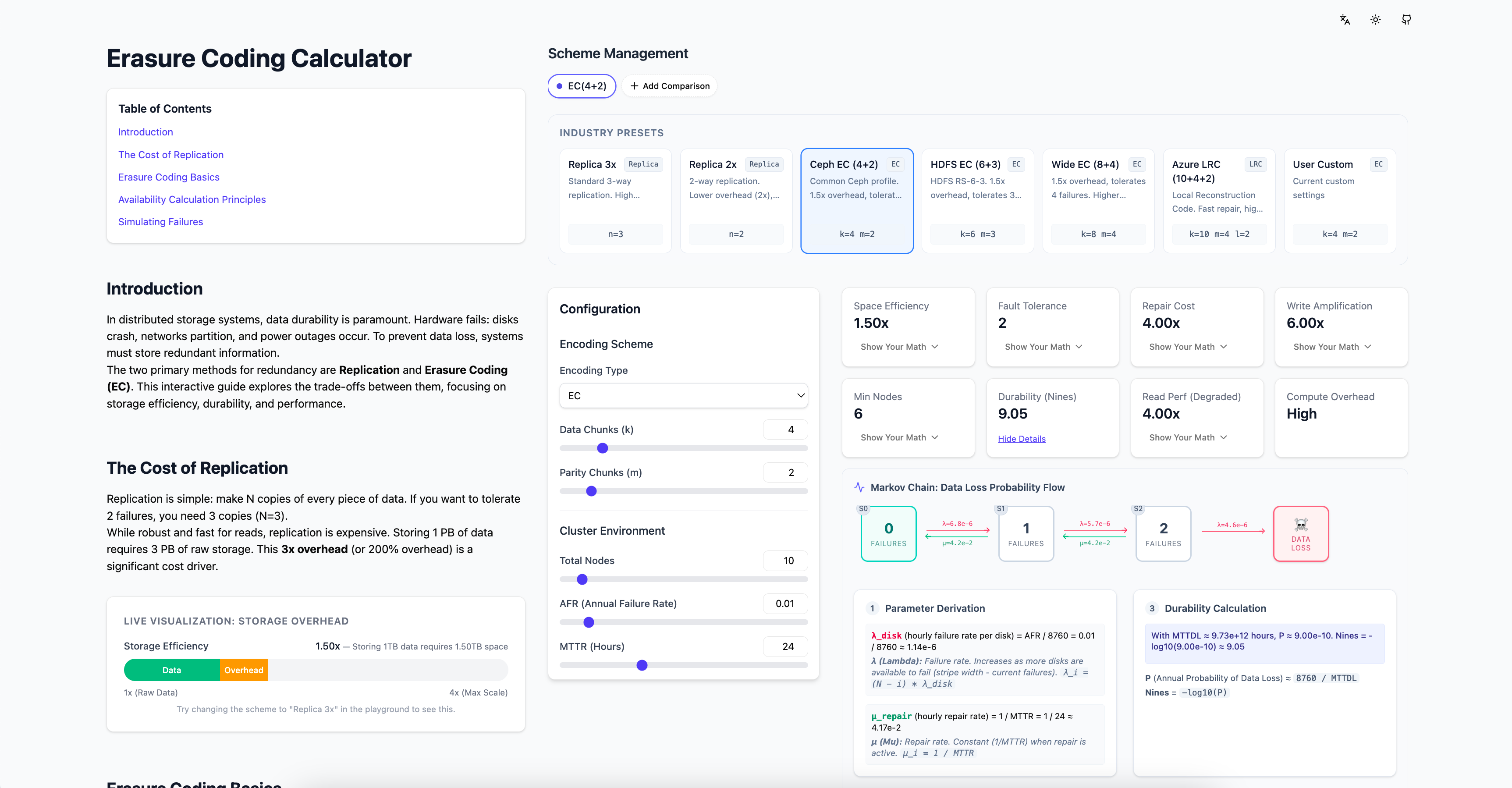
4 思考:与传统敏捷开发的对比
BMAD 大量借用了 Scrum/敏捷的术语和仪式:Epic、Story、Sprint、Retrospective、Scrum Master、Acceptance Criteria。
| 概念 | 在传统敏捷中的作用 | 在 BMAD 中的作用 | 评价 |
|---|---|---|---|
| Story + AC | 描述需求,定义验收标准 | 作为 Dev Agent 的输入规格书 | 合理。LLM 需要结构化的输入才能产出可控的代码。Story 文件在此起到了"函数签名"的作用。 |
| Epic | 组织相关 Story 的容器 | 按功能域分组 Story | 合理。是一种自然的需求分层方式。 |
| TDD | 保证代码质量的工程实践 | 约束 LLM 先写测试再写代码 | 有价值。通过运行测试提供了一个客观的反馈信号,部分缓解了 LLM 生成代码不可靠的问题。 |
| sprint-status.yaml | 跟踪迭代进度 | 记录每个 Story 的状态流转 | 合理。提供了跨会话的状态持久化,解决了 LLM 没有长期记忆的问题。 |
但是,直接套用 Scrum 也有一些问题。虽然能 work,但对于 LLM 可能并不是最佳做法。
| 概念 | 在传统敏捷中存在的原因 | 在 BMAD 中的生硬之处 |
|---|---|---|
| Scrum Master (SM Agent) | 协调人类团队的沟通、消除阻碍、推动流程 | LLM 不需要"协调"。SM Agent 本质上只是一个 Story 文件生成器和 Sprint 规划工具。给它冠以"Scrum Master"的头衔增加了理解成本,不如直接叫"Story Generator"。 |
| Retrospective | 团队反思协作问题、改进流程 | LLM 没有情绪、没有协作摩擦、不会疲劳。对 LLM 做"回顾"只能评估产出物质量,但这和 Code Review 重叠了。 |
5. BMAD 的优缺点和适用场景
5.1 结构化的 LLM 交互协议
BMAD 最大的贡献在于将"和 LLM 聊天写代码"从随意对话升级为可重复的流程。instructions.xml 中的 10 步开发流程(查找 Story -> 加载上下文 -> TDD -> 验证 -> 更新状态)比"帮我写个计算器"的 Prompt 可靠得多。
5.2 文档驱动的开发
传统项目中,文档常常滞后于代码。BMAD 反转了这一关系:代码是从文档中派生的。Story 文件不仅是需求描述,还是 Dev Agent 的执行上下文和结果记录。例如 1-3-core-calculation-engine.md 中,既包含 AC(验收标准),也包含数学公式参考、库选型决策、架构约束,最终还记录了 Agent 实际修改的文件列表。
这种做法的实际好处:当人类需要理解"这段代码为什么这样写"时,可以回溯到对应的 Story 文件。
5.3 跨会话的状态管理
LLM 没有持久记忆。BMAD 通过 sprint-status.yaml 和 Story 文件中的状态字段(ready-for-dev -> in-progress -> review -> done)实现了跨会话的进度追踪。新的对话可以通过读取这些文件,从上次中断的地方继续。
5.4 强制 TDD
instructions.xml 明确要求 "Write FAILING tests first"、"NEVER proceed with failing tests"、"NEVER lie about tests being written or passing"。虽然这些约束仅靠 Prompt 执行(LLM 可能不遵守),但结合实际运行测试套件的能力(在 Cursor 中 Agent 可以执行 shell 命令),形成了一个可验证的反馈闭环。
5.6 不是想象中的 "Agent"
BMAD 使用 "Multi-Agent" 这个术语,但这些 Agent:
- 没有并发执行能力:只能一次激活一个 Agent,由人类手动切换。
- 没有持久状态:每次对话开始时 Agent 从零加载,靠读取磁盘文件恢复上下文。
- 没有 Agent 间通信:PM Agent 和 Dev Agent 之间的"协作",是人类在两个不同的聊天窗口中分别加载不同的 Prompt 文件,中间靠共享文件传递信息。
- 本质是 Prompt 切换:换一个 Agent,就是换一份 System Prompt。
和真正的多 Agent 系统(如 AutoGen、CrewAI)相比,BMAD 的"Agent"更接近于"Prompt 模板"。
5.7 流程开销与项目规模
项目自身超过一定规模,使用 BMAD 才有意义。
本项目 ec-calc 是一个单页前端计算器应用,核心逻辑不超过 500 行。但 BMAD 为它生成了:
- 6 个 Epic,23 个 Story 文件
- PRD、架构文档、UX 设计文档、实现就绪报告
- 一套完整的 Sprint 管理流程
这些仪式性产出物的总量远超实际代码量。对于一个小型项目,这种重量级流程引入了不必要的间接层——为了理解"如何用 BMAD 开发"本身就需要花费大量时间。
也就是说,至少项目规模或者稳定性、可持续迭代性要求得远远大于 bmad 产物,才能有意义。
5.8 大量的 token 使用
由于 bmad 自身需要大量在对话中保存状态,以及每个对话重复读取、思考和写入状态与规则。相比一句话的心流式,token 使用量暴增。
这意味着开发者需要决定是否为稳定的、可管理的流程付出这些花销。
笔者认为多花 token 不一定是坏事。人类的软件开发其实也会消耗大量的心智在方案设计、规范和文档编写上。这些 token 本质上让工程质量可预测,能够保持在后续持续地迭代新功能,而不是一次性的 vibe coding 产物。避免后续维护变成恐怖的屎山。
6 人类在环 (Human-in-the-Loop)
BMAD 流程中人类介入的位置如下:
必须介入
| 环节 | 人类动作 | 原因 |
|---|---|---|
| 初始输入 | 提供产品想法或需求描述 | LLM 无法自发产生业务需求 |
| Agent/Workflow 选择 | 从菜单中选择要执行的操作(如 [CP] 创建 PRD、[DS] 开发 Story) |
Agent 不会自动判断"下一步该做什么",需要人类发号施令 |
| 规划文档审核 | 审核 PRD、架构文档、Epic 拆解 | 如 6.5 节所述,这是阻断错误传播的关键节点 |
| 最终验收 | 实际运行产品,验证功能是否符合预期 | LLM 的测试可能和代码犯同样的错 |
应当介入但容易被跳过
| 环节 | 应做什么 | 被跳过的风险 |
|---|---|---|
| Story 文件审核 | 逐条检查 AC 和 Task 是否合理 | Story 数量多(本项目 23 个),容易变成"走过场" |
| Code Review | 用不同 LLM 或人工审核代码 | 框架建议但不强制使用不同 LLM,人类可能直接让同一个 Agent 自审 |
| 纠偏 (Course Correction) | 当发现 Agent 实现偏离预期时,启动 [CC] 工作流 |
需要人类有足够的技术判断力来发现偏差 |
实质上不需要人类介入
| 环节 | 说明 |
|---|---|
| Sprint Planning | SM Agent 从 Epic 文件机械地生成 sprint-status.yaml,人类通常直接接受 |
| Story 创建 | SM Agent 从 Epic 列表提取信息填充 Story 模板,人类通常直接接受 |
| Retrospective | 对 LLM 做"回顾"的实际价值有限 |
笔者认为,BMAD 非常依赖于人类的及时介入和纠偏,这是非常合理的。因为使用 BMAD,质量和可维护性往往被放在第一位,速度自然无法追赶一键放手的开发流程。
7 总结
BMAD 的核心价值在于将 LLM 辅助开发从"即兴聊天"升级为"流程化工程"。它提供的工作流脚本、状态管理和文档协议,确实解决了"LLM 写代码不可控"这一真实痛点。
但它也背负着以下包袱:
- 对人类敏捷仪式的机械模仿——Scrum Master、Retrospective 等概念在 AI 上下文中丧失了原有意义,增加了认知负担却不一定带来对等价值。
- 流程重量级——对小项目而言,仪式成本可能超过收益。
- 自我验证的可信度问题——LLM 同时充当开发者和测试者的模式,需要人类更强的介入(而非更弱)才能保证质量。
对资深工程师的建议:BMAD 的工作流脚本(特别是 dev-story/instructions.xml)和状态管理机制值得学习和借鉴。但在采用时,应当根据项目规模裁剪流程,剥离纯粹的仪式性组件,并在关键节点(PRD 审核、Code Review)强制引入独立于生成 Agent 的验证手段。
对敏捷流程熟悉的读者:受限于笔者自身对敏捷流程的认识,部分描述可能有误。欢迎在评论区补充、指正!读者若对这个流程有自己的看法,也欢迎评论区留言讨论!




搞一个太大的项目,从零开始也是难搞。这套方法看着合理,实则还是很难用。需求文档对齐,越对文档越大,后期开发也是刚开始加载时llm知道怎么回事不用一会,上下文大起来,注意力机制变弱,工具的agent又开始飘了。换个新窗口吧各种文档有得加载一遍,整体用起来真的还是有得考验!
@游客爱好者 是的,你说的场景,我觉得 https://github.com/gsd-build/get-shit-done 比较适合。没那么臃肿!我最近也在重度实践,主观感觉比 bmad 好得多,可以尝试下