SRE 小王凌晨两点将节点设为 DRAINING,这是他控制面系统发生的变化。
Table of Contents
0 前言
分布式系统的控制面(ControlPlane)有一项看上去不太起眼的工作:管理节点的生命周期状态。节点是活的还是死的?能不能接受写入?正在下线迁移数据?已经彻底退役了?
控制面的开发维护就是这样 —— 功能看起来不起眼,实际上需要悉心的模式设计才能满足健壮和可迭代性。
笔者有个玩笑:什么是一个成功的控制面?如果交付上线后和隐身了一样,大家都不来找你,就是设计和功能上最成功的控制面!反之,有人总找过来,要么是人体工学设计不太好,要么就是发生服务不可用的大事故了。
单单一个节点管理,线上环境就很可能有如下 case 的组合:
- 节点可能和磁盘资源是关联的,引发整个状态组合的膨胀
- 人工运维操作和集群自动健康检查操作有可能是并发的
- 在混沌的分布式环境,从编码时期就有必要覆盖所有的可能性,令状态预期最终收敛
这需要方案设计阶段便仔细列出所有的状态转换 + 合理的编码模式。本文描述一种模式,推荐使用有限状态机抽象并管理所有的状态转移。
本文以一个架空虚构的分布式对象存储系统 TinyBlob 为背景,记录在节点状态管理上可能发生的 “意大利面条反模式” 和 “坏代码”,以及最终如何用一张声明式状态机转换表把这些逻辑优雅重构。
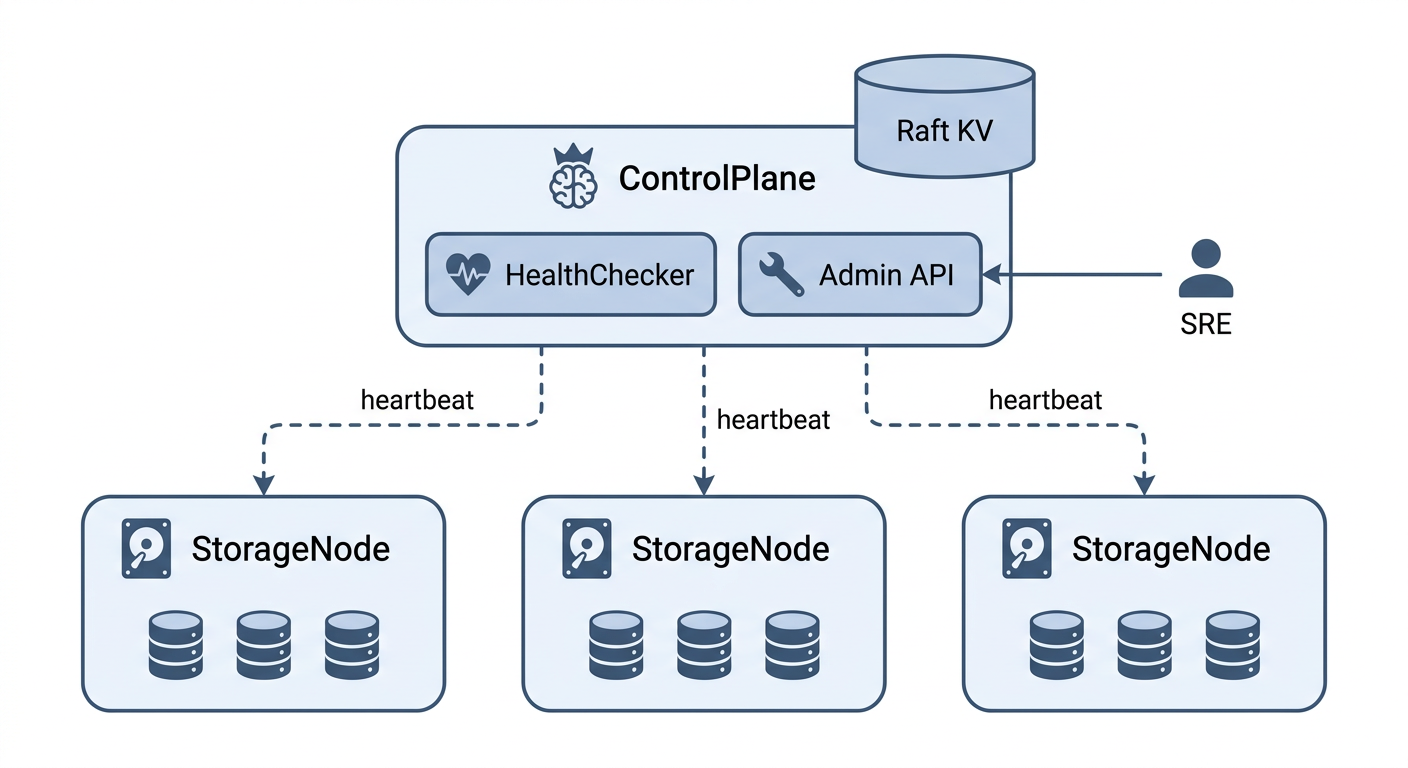
TinyBlob 的架构很典型:
- ControlPlane:控制面,管理集群元数据和路由表,通过 Raft KV 持久化
- StorageNode:存储节点,实际存数据,每个节点上有多块磁盘
- HealthChecker:ControlPlane 里的健康检查模块,定期探活
- Admin API:给 SRE 用的运维接口,做节点上下线等操作
1 虚构的 on call 小故事
SRE 小王发现 StorageNode-17 上有一块磁盘的 SMART 指标异常,随时可能挂。他决定在磁盘彻底死掉之前把这台节点优雅下线——通过 Admin API 把节点设为 DRAINING,触发数据迁移任务。
迁移任务跑了大概二十分钟,大约迁完了 60%。这时候,HealthChecker 的定时任务醒了。它看了一眼 StorageNode-17:心跳正常(坏盘不影响心跳),网络通畅。HealthChecker 的代码里有这么一段逻辑:
if node.IsAlive {
// 节点还活着,不用动
} else {
node.IsAlive = true // 恢复上线
node.IsDraining = false
saveToRaftKV(node)
}等等,有个小问题——这段代码是一个月前另一个同事写的,当时还没有 draining 功能。加 draining 的人改了 Admin API 的代码,但忘了改 HealthChecker 的代码。HealthChecker 的判断很朴素:心跳在就是活的,活的就该把那些乱七八糟的 flag 清掉。
于是 StorageNode-17 的状态被静默地从 DRAINING 改回了 UP。
节点重新开始接收写入流量。新数据又往那块快要死的磁盘上写了。
更要命的是——小王看了一眼监控面板,发现 StorageNode-17 状态已经是 UP 了。他以为是隔壁组的同事取消了他的 drain 操作(这种事以前发生过),就没深究,去忙别的了。
四个小时后,那块磁盘彻底挂了。磁盘上的数据加上迁移中断后新写入的数据,一部分副本丢失。
这个事故的根源不能完全归咎某个人写了 bug,而是这种 flag 驱动的意大利面反模式已经不能在大型分布式系统中健壮工作了。
HealthChecker 的逻辑在它被写出来的时候是对的。Admin API 的 drain 逻辑也是对的。问题在于:两段各自正确的代码,合在一起就是灾难。SRE 说 "我要 drain 这个节点",HealthChecker 说 "节点活着,应该 UP"——两边都有道理,但没有一个统一的地方来裁定:DRAINING 状态下收到健康心跳,到底该怎么办?
事后复盘时,大家在代码里翻了半天,也没找到一张完整的状态转换图。
2 反模式是怎么长出来的
上面那种烂代码可能是由于维护者更换、需求迭代中慢慢生长的。笔者虚构了一些场景,还原一下这个演化过程。
本文只是虚构了场景举例说明这种反模式,实际上大型分布式系统的初期方案就要打好坚实的基础。后续一旦上了生产环境,重构的代价是繁重的。
2.1 V1:一个 bool 很简洁
TinyBlob 最初上线时,需求很简单:StorageNode 要么在线服务,要么挂了。一个 bool 搞定:
type StorageNode struct {
ID string
IsAlive bool
}
func HandleHeartbeat(node *StorageNode) {
node.IsAlive = true
}
func HandleTimeout(node *StorageNode) {
node.IsAlive = false
}2.2 V2:优化版本,加 flag
过了几个月,运维需求多了起来:
- 要支持 优雅下线(先迁移完数据再下线,不能直接拔线)→ 加一个
IsDrainingflag - 磁盘故障需要上报 → 加一个
HasDiskErrorflag
type StorageNode struct {
ID string
IsAlive bool
IsDraining bool
HasDiskError bool
}3 个 bool,理论上有 8 种组合。但合法的状态其实只有 4 种:在线服务、下线迁移中、离线、离线且有坏盘。剩下的 4 种组合是什么?是 bug。
代码开始出现这样的判断:
func CanAcceptWrite(node *StorageNode) bool {
return node.IsAlive && !node.IsDraining && !node.HasDiskError
}看着还行,但已经开始觉得哪里不对劲了。比如:IsAlive == false && IsDraining == true 是什么意思?节点挂了但正在下线?这种组合有人处理吗?flag 已经开始爆炸了。
2.3 V3:if-else 意大利面
随着功能继续迭代,问题开始爆发。 HealthChecker 里有一套判断逻辑:
func (hc *HealthChecker) Check(node *StorageNode) {
if isReachable(node) {
node.IsAlive = true
// TODO: 这里要不要清 IsDraining?
// 张三说不用,李四说要清
} else if isPermDown(node) {
node.IsAlive = false
node.IsDraining = false // 永久下线,清 draining
} else {
node.IsAlive = false
// IsDraining 保持不变?还是也清掉?
}
}Admin API 里又是另一套:
func (api *AdminAPI) SetDraining(node *StorageNode) error {
if !node.IsAlive {
return errors.New("node is down, cannot drain")
}
if node.HasDiskError {
// 有坏盘的节点能不能 drain?代码里没写,
// 线上出过一次问题之后加了这个判断
return errors.New("fix disk error first")
}
node.IsDraining = true
return nil
}心跳处理里又有一套:
func HandleHeartbeat(node *StorageNode, hb Heartbeat) {
node.IsAlive = true
if hb.HasDiskError {
node.HasDiskError = true
if node.IsDraining {
// 正在下线的节点磁盘又报错了,怎么办?
// 王五加了这行注释但是没写处理逻辑
}
}
}三个模块,三套 if-else,各自对 "某个 flag 组合该怎么处理" 有不同理解。每次加一个新状态,三个地方都要改。每次改,都有概率漏掉某个分支、或者和另一个模块的逻辑冲突。
3 问题出在哪?
回过头来看,V3 代码的问题不是某个人写得差。问题是这种基于 if-else-flag 的架构方式本身就在制造混乱。
状态空间爆炸。N 个 bool flag 意味着 2^N 种组合。3 个 flag 就是 8 种,4 个就是 16 种,其中大部分组合是非法的。但编译器不会告诉你哪些是非法的——只有线上出了事故,你才知道某个组合没处理。
转换逻辑分散在多个模块。HealthChecker 写了一套 if-else,Admin API 写了另一套,心跳处理又写了一套。做 code review 的时候,没有人能从散落在三个文件里的 if-else 中还原出一张完整的状态转换图。老维护者能画出来,说明他脑子里的 cache 足够大。但换个新人来,画不出来。
缺少 Action 语义。看日志只能看到 "StorageNode-17 status changed from DRAINING to UP"。为什么改的?是 SRE 手动操作的,还是 HealthChecker 自动改的?翻日志翻半天。同样是变成 UP,"SRE 手动恢复上线" 和 "HealthChecker 判断心跳恢复" 完全是两件事,但在 flag 模式下它们长得一模一样。
并发竞态。HealthChecker 是一个定时循环,Admin API 是 RPC 请求,心跳是另一个 RPC 请求。三个操作来源并发修改同一个节点的 flag,谁先谁后取决于时序。第 1 节的事故,本质上就是 HealthChecker 和 Admin API 的竞态。
子资源联动遗漏。StorageNode 下面有多块磁盘。节点被标为下线,磁盘的状态要不要也跟着改?V3 代码里,有的地方改了,有的地方忘了。
4 有限状态机:State 和 Action
在动手重构之前,我们不妨先退一步,想清楚 "状态管理" 这件事的本质是什么。
4.1 从 flag 到有限状态机
前面用 bool flag 来描述节点状况,本质上是在用 属性组合 建模。但仔细想想,一个 StorageNode 在任意时刻只会处于一种合法状态——它要么在服务,要么在下线,要么已经退役,不存在 "既在服务又在下线" 这种薛定谔的状态。
那为什么不直接把合法状态枚举出来?
type NodeState int
const (
StateUP NodeState = iota // 在线服务
StateDOWN // 临时离线(心跳超时)
StateDRAINING // 优雅下线中(正在迁移数据)
StateREMOVED // 已退役
)4 个枚举值,不多不少,每一个都是合法的。不存在 "非法组合" 的概念了——因为不可能构造出一个 NodeState 同时等于 UP 和 DRAINING。
状态之间怎么跳转?不是随便跳的。从 UP 可以跳到 DOWN(心跳超时了),可以跳到 DRAINING(SRE 发起下线),但不能直接跳到 REMOVED(还没迁移数据呢,不能直接退役)。
这就是有限状态机(FSM)1的思路:枚举所有合法状态,定义合法的转换路径,每条路径由一个 Action 触发。
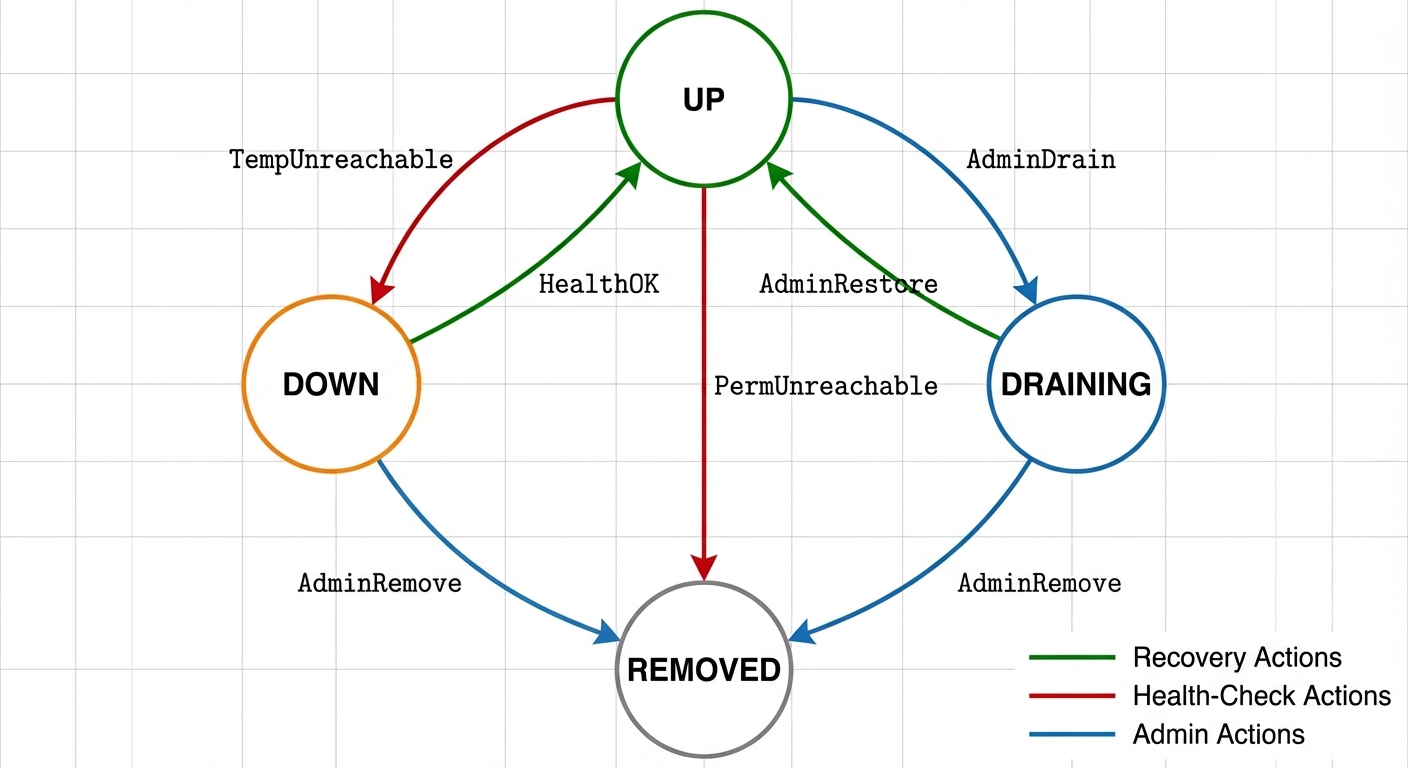
画出来之后,所有合法的跳转一目了然。
4.2 为什么是 Action 驱动,而不是直接设目标状态
你可能会想:直接提供一个 SetStatus(node, targetState) 接口如何?让调用方指定想要的目标状态。但实际做下来会发现这其实没有彻底消灭 “反模式”。
对比两种 API 设计:
// 方案 A:直接设目标状态
SetStatus(node, StateDRAINING)
// 方案 B:传入 Action
DoTransition(node.Status, ActionAdminDrain)方案 A 的问题在哪?
调用方自己需要判断 "当前状态能不能跳到目标状态"。比如 REMOVED 状态的节点能不能设成 DRAINING?能还是不能,取决于业务规则。但这些规则在方案 A 里没有一个统一的地方来表达——调用方各自 if-else 判断一下,问题又回到了 V3 代码的老路上。
还有一个问题:同样是到 REMOVED 状态,触发原因可能完全不同。HealthChecker 判断节点永久不可达(PermUnreachable),和 SRE 手动执行退役(AdminRemove),虽然目标状态都是 REMOVED,但后续处理不一样——前者要发 P1 告警,后者只是正常运维操作。用方案 A,日志里只能看到 "status: DRAINING → REMOVED",看不到是为什么。
方案 B 就不同了。调用方只需要说 "发生了什么事"(一个 Action),由状态机来裁定 "该怎么转"。审计日志里能清楚地看到:谁、什么时间、因为什么 Action、把状态从 A 改成了 B。
状态机成了唯一的裁判。 调用方不需要、也不应该关心转换规则。
4.3 Action 必须无前序依赖
这点非常重要,也是避免 FSM 爆炸的核心约束之一。(FSM 的状态,如果设计不当,也会爆炸。)
先看一个反面例子,假设我们设计了一条状态链:
UP → DRAINING → MIGRATING → REMOVED其中 MIGRATING 状态只能从 DRAINING 进入,表示 "数据迁移正在进行中"。逻辑上这很合理对不对?
但在分布式环境下,每一次状态变更的持久化都可能失败。
场景是这样的:SRE 发起 drain 操作,ControlPlane 的 Leader 算出新状态是 DRAINING,准备通过 Raft 写入 KV 存储。这时候 Raft 出了个短暂故障(Leader 切换、网络抖动、etcd 闪断——生产上这些都是家常便饭),写入失败了。
Leader 切换后,新 Leader 从持久化恢复状态——状态还是 UP,因为 DRAINING 没写进去。这时候迁移调度器检测到 "该做迁移了",发出 "开始迁移" 的 Action。状态机一查表:当前状态是 UP,不是 DRAINING,拒绝转换到 MIGRATING。
系统卡住了。
问题在于 MIGRATING 依赖了一个前序状态 DRAINING。这种 "必须先经过 A 才能到 B" 的状态链,在持久化可能失败的分布式环境里是脆弱的。
正确的做法:每个 Action 只依赖当前状态,不依赖 "之前经历过什么状态"。
nextState = DoTransition(currentState, action)纯粹的 (State, Action) → State 映射。任何时刻,只要知道当前状态和当前发生的事件,就能确定下一个状态。不需要知道这个节点之前经历过什么。
这样设计的好处是什么?持久化失败了也没关系。 下一次心跳来了,HealthChecker 又跑了一轮,或者 SRE 又点了一次按钮——同一个 Action 会被重新触发,状态机从当前状态重新计算,系统自然收敛到期望状态。
这和 Kubernetes controller 的 reconcile 模式2异曲同工:不去追踪 "之前做过什么操作",而是反复对比当前状态和期望状态,通过重复执行收敛。
4.4 没有未定义行为(UB)
回想一下 V3 的 if-else 代码。你能回答这个问题吗:DOWN 状态的节点收到 AdminDrain 操作会怎样?
翻代码——HealthChecker 那边没处理这个 case,Admin API 那边有个 if !node.IsAlive { return error } 但它检查的是 IsAlive flag 而不是 DOWN 状态……说不清楚。这其实就是业务逻辑层面的未定义行为(UB):对于某个 (状态, 操作) 组合,代码里根本没有明确的处理路径。线上跑到了这个分支会发生什么?取决于 if-else 的排列顺序和短路求值——换句话说,取决于运气。
状态机转换表天然消灭了这个问题。表是一个全量覆盖的矩阵:每一个 (State, Action) 组合,要么在转换表里(有明确的目标状态),要么在错误表里(明确拒绝),要么两者都不在(明确表示状态不变)。三种结果,没有第四种。所有的行为都是可预测的。
新人接手这个模块,不需要通读三个文件的 if-else 来理解 "某个 case 走到了哪个分支"。看一眼表,行列交叉,答案就在格子里。
4.5 需求变更时只改表
这一点看上去不起眼,但笔者在实际项目迭代中体会很深。
假设产品提了个新需求:增加一个 READONLY 状态,表示节点还能读但不接受新写入。在 if-else 模式下,你要做什么?打开 HealthChecker、Admin API、心跳处理三个文件,在每个文件的 if-else 树里小心翼翼地加分支,祈祷不要漏掉某个 case,改完之后写一堆集成测试来验证没有搞坏别的路径。
在状态机模式下?往表里加几行就完事了。给 READONLY 加上它和其他状态之间的转换规则,跑一遍表驱动的单元测试,确认新加的行和已有的行没有冲突。
反过来,如果要阻断某个转换——比如线上发现 DRAINING → UP(通过 AdminRestore)这条路径在某些场景下有问题,需要临时禁掉——也只需要把这一条从转换表挪到错误表里。一行代码的改动,一个 test case 的修改,PR review 的时候 diff 清清楚楚。
不用在三个文件里 grep "DRAINING" 然后逐个分析哪些分支需要改。
5 用一张表替代所有 if-else
道理说得差不多了,我们上代码看看。
5.1 状态机转换表
整个状态机的核心就是一张二维表。行是 Action(发生了什么事),列是当前状态,格子里填的是目标状态:
+-------------------+----------+----------+----------+----------+
| | UP | DOWN | DRAINING | REMOVED |
+-------------------+----------+----------+----------+----------+
| HealthOK | | UP | | |
| TempUnreachable | DOWN | | REMOVED | |
| PermUnreachable | REMOVED | REMOVED | REMOVED | |
| AdminDrain | DRAINING | | ERR | ERR |
| AdminRemove | REMOVED | REMOVED | | |
| AdminRestore | | UP | UP | UP |
+-------------------+----------+----------+----------+----------+
空格 = 状态不变(Action 被忽略)
ERR = 非法操作(返回错误)这张表把第 1 节的事故也覆盖了:DRAINING 状态下收到 HealthOK?查表——空格,状态不变。HealthChecker 不会把 DRAINING 改成 UP。
DRAINING 状态下节点临时不可达了?TempUnreachable → REMOVED。既然在 drain 过程中节点还挂了,那就别 drain 了,直接标为退役,剩下的数据走修复流程。
这些规则不藏在 if-else 的某个分支里,就在这张表上,PR review 的时候一目了然。
5.2 代码实现
有了表,代码实现就很直白了:
type NodeState int
type Action int
const (
StateUP NodeState = iota
StateDOWN
StateDRAINING
StateREMOVED
)
const (
ActionHealthOK Action = iota
ActionTempUnreachable
ActionPermUnreachable
ActionAdminDrain
ActionAdminRemove
ActionAdminRestore
)
type transKey struct {
Current NodeState
Action Action
}
// 非法操作表
var errTransitions = map[transKey]bool{
{StateDRAINING, ActionAdminDrain}: true,
{StateREMOVED, ActionAdminDrain}: true,
}
// 合法转换表
var transTable = map[transKey]NodeState{
{StateUP, ActionTempUnreachable}: StateDOWN,
{StateUP, ActionPermUnreachable}: StateREMOVED,
{StateUP, ActionAdminDrain}: StateDRAINING,
{StateUP, ActionAdminRemove}: StateREMOVED,
{StateDOWN, ActionHealthOK}: StateUP,
{StateDOWN, ActionPermUnreachable}: StateREMOVED,
{StateDOWN, ActionAdminRestore}: StateUP,
{StateDOWN, ActionAdminRemove}: StateREMOVED,
{StateDRAINING, ActionTempUnreachable}: StateREMOVED,
{StateDRAINING, ActionPermUnreachable}: StateREMOVED,
{StateDRAINING, ActionAdminRestore}: StateUP,
{StateDRAINING, ActionAdminRemove}: StateREMOVED,
{StateREMOVED, ActionAdminRestore}: StateUP,
}
func DoTransition(current NodeState, action Action) (NodeState, error) {
// 先检查是否非法
if errTransitions[transKey{current, action}] {
return current, fmt.Errorf(
"illegal transition: state=%v action=%v", current, action)
}
// 查找转换目标
if next, ok := transTable[transKey{current, action}]; ok {
return next, nil
}
// 表里没有 = 状态不变
return current, nil
}整个状态机就这么点代码。纯函数,没有副作用,没有锁,不持有任何状态。输入是 (当前状态, Action),输出是 (下一状态, error)。
5.3 怎么用
所有需要修改节点状态的地方,统一调用 DoTransition:
// HealthChecker:节点心跳超时
newState, err := DoTransition(node.Status, ActionTempUnreachable)
if err != nil {
log.Errorf("transition failed: %v", err)
return err
}
if newState != node.Status {
node.Status = newState
saveToRaftKV(node) // 持久化
}// Admin API:SRE 发起 drain
newState, err := DoTransition(node.Status, ActionAdminDrain)
if err != nil {
// 比如对一个已经 REMOVED 的节点做 drain,状态机拒绝
return err
}
if newState != node.Status {
node.Status = newState
saveToRaftKV(node)
}// 心跳处理:节点上报心跳
newState, err := DoTransition(node.Status, ActionHealthOK)
// ...同上三个调用方的代码结构一模一样,差别只在传入的 Action 不同。状态转换的规则集中在一张表里,调用方不需要操心 "当前状态能不能这么转"。
回到第 1 节的场景:SRE 设了 DRAINING,HealthChecker 收到心跳触发 ActionHealthOK。查表——(DRAINING, HealthOK) 不在转换表里,DoTransition 返回当前状态不变。问题消失了。
5.4 子资源级联
StorageNode 下面有多块磁盘,每块磁盘也有自己的状态。当节点级别的 Action 发生时,需要级联到所有磁盘:
func SetNodeStatus(node *StorageNode, action Action) error {
// 1. 节点状态变迁
newState, err := DoTransition(node.Status, action)
if err != nil {
return err
}
changed := newState != node.Status
node.Status = newState
// 2. 级联到所有磁盘
for _, disk := range node.Disks {
newDiskState, err := DiskDoTransition(disk.Status, action)
if err != nil {
log.Errorf("disk %d transition failed: %v", disk.ID, err)
return err
}
if newDiskState != disk.Status {
changed = true
disk.Status = newDiskState
}
}
// 3. 有变更才持久化
if changed {
saveToRaftKV(node)
}
return nil
}节点和磁盘的状态变更在同一个事务里提交到 Raft KV,要么全部生效,要么全部不生效。不会出现 "节点改了但磁盘忘改了" 的情况。
6 几个工程细节
先算后写:上面的代码有一个不起眼但很关键的特征:先用纯函数算出所有新状态,最后才批量写入 Raft KV。DoTransition 是纯函数,不修改任何外部状态,也不做 IO。算完发现 "状态没变",那就不写了——省掉一次 Raft 共识。算完发现 "Raft 写失败了",内存里的状态也没被改坏——下一轮健康检查或心跳会重新触发同样的 Action,自然收敛(4.3 节讨论过的)。
风控:HealthChecker 有一个容易被忽略的危险场景:假设 ControlPlane 刚切主,新 Leader 还没收到任何心跳,这时候跑一轮健康检查——所有节点都 "超时" 了。如果不加保护,一瞬间整个集群的节点都会被标成离线。所以生产环境里,HealthChecker 需要做一个风控检查:如果超过 1/3 的节点被判定异常,说明大概率是 ControlPlane 自身的问题(比如刚切主),而不是存储节点真的全挂了。这时候停止自动下线,发告警让人工介入。
可测试性:状态机是纯函数,测试写起来非常舒服——一条转换规则对应一个 test case,不需要 mock 任何外部依赖:
func TestTransitions(t *testing.T) {
tests := []struct {
current NodeState
action Action
expected NodeState
wantErr bool
}{
{StateUP, ActionTempUnreachable, StateDOWN, false},
{StateUP, ActionAdminDrain, StateDRAINING, false},
{StateDRAINING, ActionHealthOK, StateDRAINING, false}, // 不变!
{StateDRAINING, ActionAdminDrain, 0, true}, // 非法
{StateDOWN, ActionHealthOK, StateUP, false},
{StateREMOVED, ActionAdminDrain, 0, true}, // 非法
}
for _, tt := range tests {
got, err := DoTransition(tt.current, tt.action)
if tt.wantErr {
assert.Error(t, err)
} else {
assert.NoError(t, err)
assert.Equal(t, tt.expected, got)
}
}
}第三个 test case 就是第 1 节那个事故场景的验证:DRAINING 状态收到 HealthOK,状态不变。如果有人误改了转换表,这个测试会立刻挂掉。
7 什么时候该用状态机?
不是所有场景都需要状态机。如果你的系统只有两个状态(在线/离线)、一个操作来源(健康检查),一个 if-else 就搞定了,引入状态机是过度设计。
笔者的经验法则:状态 >= 3 个,且操作来源 >= 2 个时,就该考虑用声明式转换表了。杀鸡别用牛刀,但管理一个集群的节点生命周期——这显然不是杀鸡。
尤其是现在 LLM coding 很省力了,一开始就使用状态机模式,真的能省掉很多重构的力气。
下面是不同方案的适用范围,供参考:
| 方案 | 适用场景 | 局限 |
|---|---|---|
| if-else + bool flag | 2 状态 + 1 操作来源 | 状态多了就是灾难 |
| 枚举状态 + switch-case | 3-4 状态 + 1 操作来源 | 多操作来源时 switch 膨胀(不推荐,还不如直接使用状态机) |
| 声明式转换表 | 3+ 状态 + 2+ 操作来源 | 需要手动维护表(但这也是优点) |
| 状态机框架 | 复杂 UI 工作流 | 引入外部依赖,后端场景偏重,这个场景没有必要 |
声明式转换表的 "需要手动维护" 其实也是优点——每次修改都在 PR 里清清楚楚,reviewer 一眼就能看到 "你改了哪条转换规则"。比起在三个文件的 if-else 里翻来翻去,这舒服太多了。
8 小结
本文和读者一起探索了控制面节点状态管理的一种实践模式。
- 我们从一个虚构的 on call 事故出发,看到了 flag 驱动的意大利面代码是如何制造混乱的 (1-2 节)
- 分析了 if-else-flag 反模式的几个核心问题 (3 节)
- 讨论了有限状态机的思路:Action 驱动、无前序依赖、消灭未定义行为 (4 节)
- 用一张声明式转换表替代了所有散落的 if-else (5 节)
- 补充了先算后写、风控、可测试性等工程细节 (6 节)
说到底,这个模式本身并不复杂。难的不是写出一张状态转换表,而是意识到该从 if-else 切换到状态机了。希望这篇文章能帮读者省掉一次凌晨两点的 oncall ^_^。



