Cloudflare 对 2025 年 12 月 5 日故障的复盘报告,和一些自己的思考。

Table of Contents
TL;DR
逻辑链和时间线
- 为防护 React 漏洞(CVE-2025-55182),Cloudflare 将 WAF 请求体缓冲区从 128KB 扩容至 1MB;
- 扩容部署中内部测试工具报错,遂通过全局配置系统(无灰度)禁用该工具;
- 禁用操作触发 FL1 代理规则模块的 Lua 代码漏洞(未处理 “execute” 动作被跳过的空值场景);
- 启用 Cloudflare 托管规则集的 FL1 代理用户受影响,出现 HTTP 500 错误,波及 28% HTTP 流量;
- 08:47 事故触发,09:12 revert 配置后服务全恢复,全程影响 25 分钟。
团子的一些小想法
还是为了一个紧急发布,未进行详尽的灰度和观察。这个发布覆盖范围直接就是全网,并且在部分工具发出警告时选择了忽略。说实话这也不能责怪上游 React 的高危漏洞,本质上还是整个的发布流程有瑕疵,质量没有控制好。
另外是最近两次故障相隔时间太近了,非常尴尬,以至于有用户质疑之前的复盘改进措施有无行动起来。
灰度策略
还是要控制灰度策略,即使是紧急修复,如果因发布导致系统不可用,会导致更大的影响范围。
然而现实世界是需要权衡的……很多时候的功能开发和发布,没办法做到零风险,只能是尽量降低。
基于 LLM,对陈旧代码常态推演和 Review?
有部分代码逻辑线上从未走到过,然而随着后续功能迭代和发布,可能随时成为雷。
我们经常会在大型分布式软件测试中,引入 Fuzz 测试和 Chaos 测试,也会打造一个 24H 运行的模拟环境运行长时间测试。
这部分是否可以引入高参数的模型(比如 Claude Opus 这种等级的模型),使用大量的 Token 长时间对陈旧的系统也进行详尽的 Review。并给与员工一些时间去修复其中显而易见的雷点。
这点 token 的成本,对于企业来说,也许比多雇佣一个员工、或承担服务不可用的商誉损失要划算多了。
下面对原文进行全文翻译,以供对原始材料感兴趣的读者参考。
原文链接 Cloudflare outage on December 5, 2025
原文翻译: 2025年12月5日Cloudflare网络中断事件
2025年12月5日08:47(本博客中所有时间均为世界协调时间UTC),Cloudflare部分网络开始出现严重故障。该事件于09:12得到解决(整体影响时长约25分钟),此时所有服务已完全恢复。
此次事件影响了部分客户,约占Cloudflare处理的全部HTTP流量的28%。只有满足以下多个条件的客户才会受到影响,具体如下。
本次故障并非由针对Cloudflare系统的网络攻击或任何恶意活动直接或间接导致,而是源于我们在检测和缓解本周披露的React服务端组件(React Server Components)行业级漏洞时,对请求体解析逻辑所做的变更。
任何系统中断都是不可接受的,我们深知继11月18日的事件后,我们再次让整个互联网失望了。下周我们将公布相关细节,说明我们为杜绝此类事件再次发生所开展的工作。
事件经过
下图展示了事件期间Cloudflare网络返回的HTTP 500错误请求量(底部红线),并与未受影响的Cloudflare整体流量(顶部绿线)进行了对比。
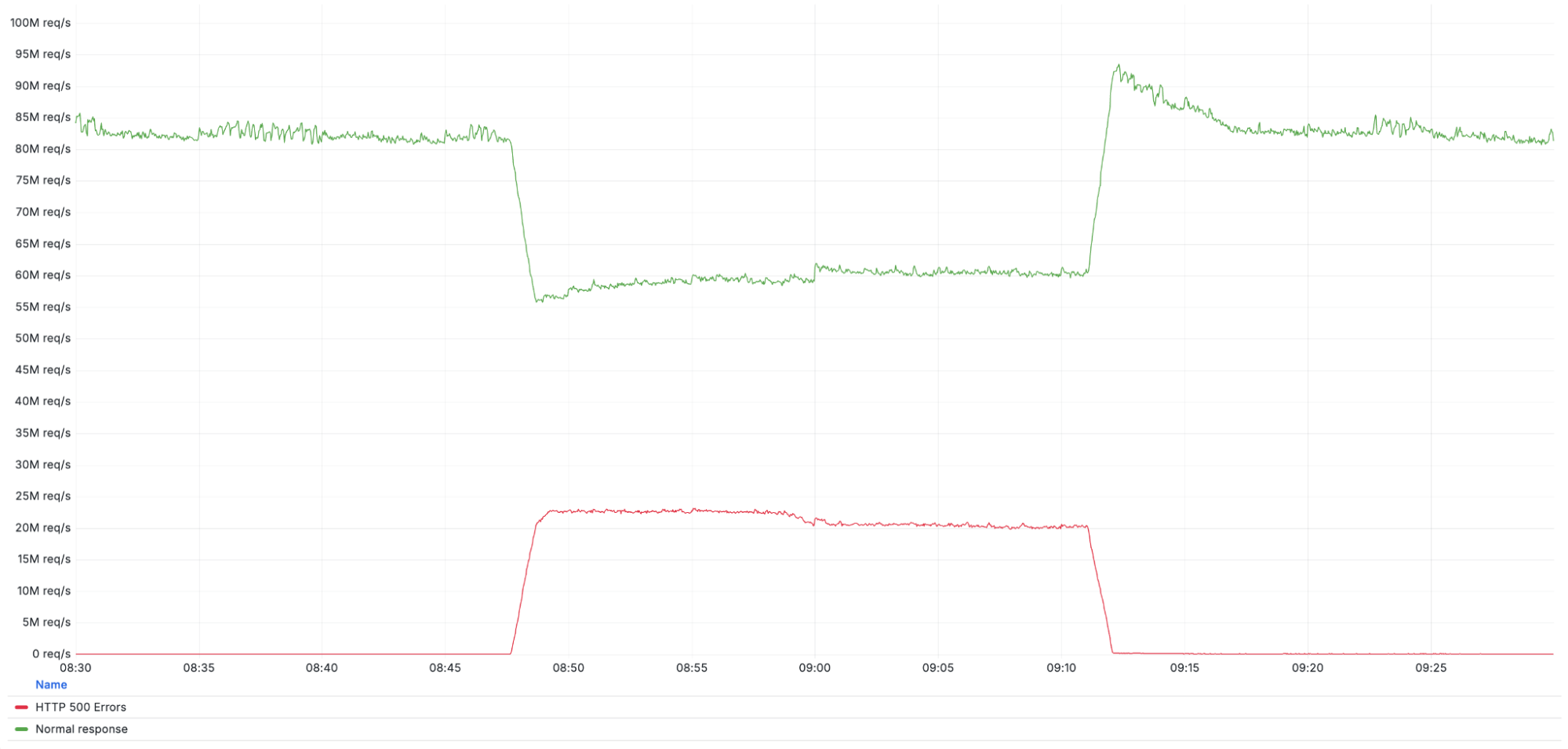
Cloudflare的Web应用防火墙(WAF)可为客户提供恶意载荷防护能力,实现对恶意请求的检测与拦截。为实现这一功能,Cloudflare的代理会在内存中缓存HTTP请求体内容以进行分析。在此之前,缓存区大小被设置为128KB。
为保护使用React框架的客户免受高危漏洞CVE-2025-55182的威胁,我们启动了缓存区扩容工作,将其调整至1MB(该数值为Next.js应用的默认限制),以确保尽可能多的客户得到防护。
该变更通过我们的渐进式部署系统推进,在部署过程中,我们发现一款用于测试和优化新WAF规则的内部工具出现了错误数量上升的情况。但由于这只是内部工具,且此次部署的修复方案属于安全层面的优化,我们决定暂时禁用该工具——毕竟它并非支撑客户流量或提供防护的必要工具。
禁用操作通过我们的全局配置系统完成。该系统不支持渐进式部署,变更会在数秒内同步至整个网络;鉴于11月18日的中断事件,目前该系统正处于审查阶段。
在特定情况下,上述变更导致我们FL1版本的代理进入错误状态,进而使网络开始返回HTTP 500错误码。
变更在全网生效后,FL1代理的代码执行触发了规则模块中的一个漏洞,引发了如下Lua语言异常:
[Lua] Failed to run module rulesets callback late_routing: /usr/local/nginx-fl/lua/modules/init.lua:314: attempt to index field 'execute' (a nil value)最终导致HTTP 500错误的产生。
我们在变更生效后不久便定位到了问题,并于09:12完成了变更回滚,此后所有流量均恢复正常处理。
受影响客户范围:使用旧版FL1代理且部署了Cloudflare托管规则集的客户会受到本次事件影响。此类客户的网站所有请求均会返回HTTP 500错误,仅部分测试端点(如/cdn-cgi/trace)除外。
未受影响客户范围:未满足上述配置的客户未受波及,中国区网络所承载的客户流量也未受到任何影响。
运行时错误详情
Cloudflare的规则集系统由多组规则构成,系统会对进入网络的每一个请求执行规则评估。每条规则包含两部分:一是筛选器,用于指定目标流量范围;二是动作指令,用于定义对流量的处理方式。常见的动作指令包括block(拦截)、log(日志记录)、skip(跳过),此外还有execute(执行)指令,用于触发另一规则集的评估流程。
我们的内部日志系统便利用了这一特性,在新规则面向公众发布前对其进行评估——顶层规则集会调用包含测试规则的子规则集。而本次事件中,我们正是试图禁用这些测试规则。
规则集系统内置了“应急关停”(killswitch)子系统,旨在快速禁用异常规则。该子系统会接收前文提及的全局配置系统下发的指令,过去我们曾多次通过该系统缓解事件,且有明确的标准操作流程,本次事件也严格遵循了该流程。
但此前我们从未对execute动作类型的规则执行过应急关停操作。当关停指令生效后,代码虽成功跳过了execute动作的评估、未执行其指向的子规则集,却在处理规则集整体评估结果时出现了错误:
if rule_result.action == "execute" then
rule_result.execute.results = ruleset_results[tonumber(rule_result.execute.results_index)]
end这段代码默认:若规则集的动作为execute,则rule_result.execute对象必然存在。但由于该规则已被跳过,rule_result.execute对象实际并未生成,Lua语言因尝试访问空值的属性而抛出错误。
这是一个存在多年却未被发现的低级代码错误,此类问题在强类型编程语言中本可避免。在新版FL2代理中,我们已使用Rust语言重写了这部分代码,因此未出现该错误。
关于2025年11月18日事件后的整改措施
两周前的11月18日,我们曾因一项不相关的变更引发了性质类似但持续时间更长的可用性事件。两次事件的共性在于:为保护客户而部署的安全相关变更在全网同步后,导致了近乎全量客户的服务异常。
11月事件后,我们已与数百家客户直接沟通,并分享了我们的整改计划,以避免单次更新引发大规模影响。我们本相信这些措施能有效防范本次事件,但遗憾的是,相关整改工作尚未完成部署。
我们深知整改工作未按时落地令人失望,这仍是全公司的首要工作任务。具体而言,以下项目将有助于控制此类变更的影响范围:
- 强化部署与版本管理:如同我们对软件进行严格健康校验的渐进式部署流程,用于快速威胁响应和常规配置的数据也需具备同等的安全防护与影响范围控制能力,包括健康状态校验、快速回滚等功能。
- 简化应急操作能力:确保在更多类型故障发生时,仍能完成关键操作。这既适用于内部服务,也适用于所有客户使用的Cloudflare控制平面交互方式。
- “故障开放”(Fail-Open)错误处理机制:作为韧性建设的一部分,我们将在所有核心数据平面组件中替换不合理的“故障阻断”逻辑。若配置文件损坏或超出范围(如超过功能上限),系统会记录错误并默认切换至已知安全状态,或在不进行规则评分的情况下放行流量,而非直接丢弃请求。部分服务还将为客户提供特定场景下“故障开放”或“故障阻断”的选项,并配备漂移预防能力以确保策略持续生效。
下周结束前,我们将发布一份详细的韧性建设项目拆解报告,涵盖上述所有项目。在整改期间,我们将暂停所有网络变更,待相关防护与回滚系统完善后再恢复操作。
对于网络服务提供商而言,此类事件的发生及集中爆发是完全不可接受的。我谨代表Cloudflare团队,就本次事件再次给客户及整个互联网生态带来的影响与困扰,致以诚挚的歉意。
事件时间线
| 时间(UTC) | 状态 | 描述 |
|---|---|---|
| 08:47 | 事件开始 | 配置变更完成部署并同步至全网 |
| 08:48 | 全面影响 | 变更在全网完全生效 |
| 08:50 | 事件声明 | 自动告警触发 |
| 09:11 | 变更回滚 | 启动配置变更回滚及同步流程 |
| 09:12 | 事件结束 | 回滚操作全网生效,所有流量恢复正常 |



