嗨多磨!今天我们要切入一个相当有趣的主题:Reinforcement Learning。最后,大家可以亲眼看到,一个人工智障使用Q-Learning,最终成为人工智能的过程。

Table of Contents
1 强化学习初见
1.1 引入

嗨多磨!今天我们要切入一个相当有趣的主题,强化学习。经过今天最后的例程,大家可以亲眼看到,一个人工智障使用Q-Learning方法,吃了不少苦头最终成为人工智能的过程。
“强化学习”一词的英文表述为Reinforcement Learning。也有人把它表述成为“增强学习”。既然这个词是舶来的,让我们先看看Reinforcement的英文表述:
the process of encouraging or establishing a belief or pattern of behavior, especially by encouragement or reward.
对某种行为模式的促进或者建立过程,尤其是使用“鼓励”和“奖励”的手段。
我国的某些俗语也反映了Reinforcement这一过程:
三天不打,上房揭瓦。
就是使用“惩罚”的手段,避免主体做出不符合期望的行动。
1.2 俄罗斯方块与玩家

其实强化学习就在我们的身边,试想以下的问题:为什么我们经过任何人的教学,就学会了玩儿“俄罗斯方块”?是什么驱使我们尽最大努力消除方块继续游戏?
我们从几个角色要素分解考虑。
- 玩家:游戏游玩者
- 玩家操作:按自己的意志操作,输入给游戏
- 游戏机:玩家面对的环境载体。
- 方块状态:让玩家获知现在的方块堆叠状态
- 特效(爆炸消除/游戏结束):给予玩家的反馈
然后,我们用一个模板,套入这个场景
- 玩家:Agent。可以翻译为“智能体”,一般是场景中行动主体。
- 玩家操作:Action,行动。
- 游戏机:Environment,环境。
- 方块状态:Observation,观察值,反馈给Agent。
- 特效(爆炸消除/游戏结束):Reward,反馈。
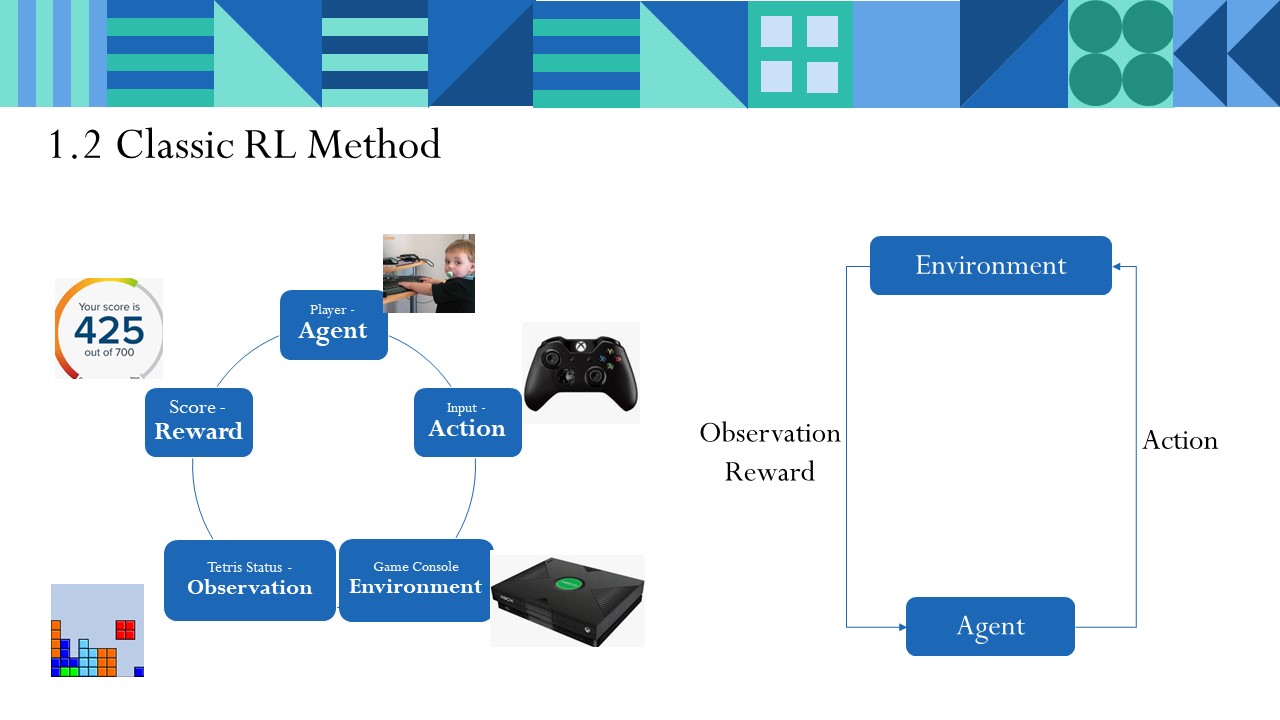
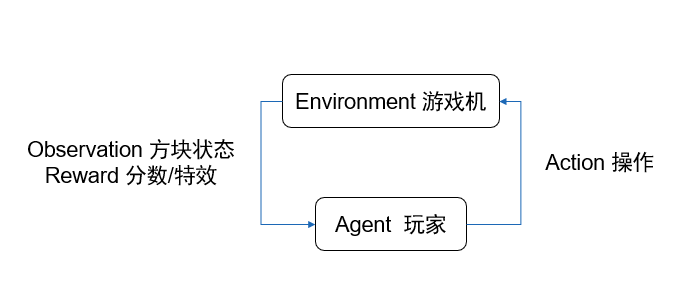
在这个过程中。玩家Agent根据方块状态Observation不断地在游戏机Envrionment上操作,一下消除4行让你很爽,给予你好的快感Reward,堆满方块导致游戏失败让你不甘心、不爽,因此给你消极Reward。
这就形成了经典的强化学习模式。学习的目标是:最大化获得的汇报。
1.3 强化学习的特点和评价
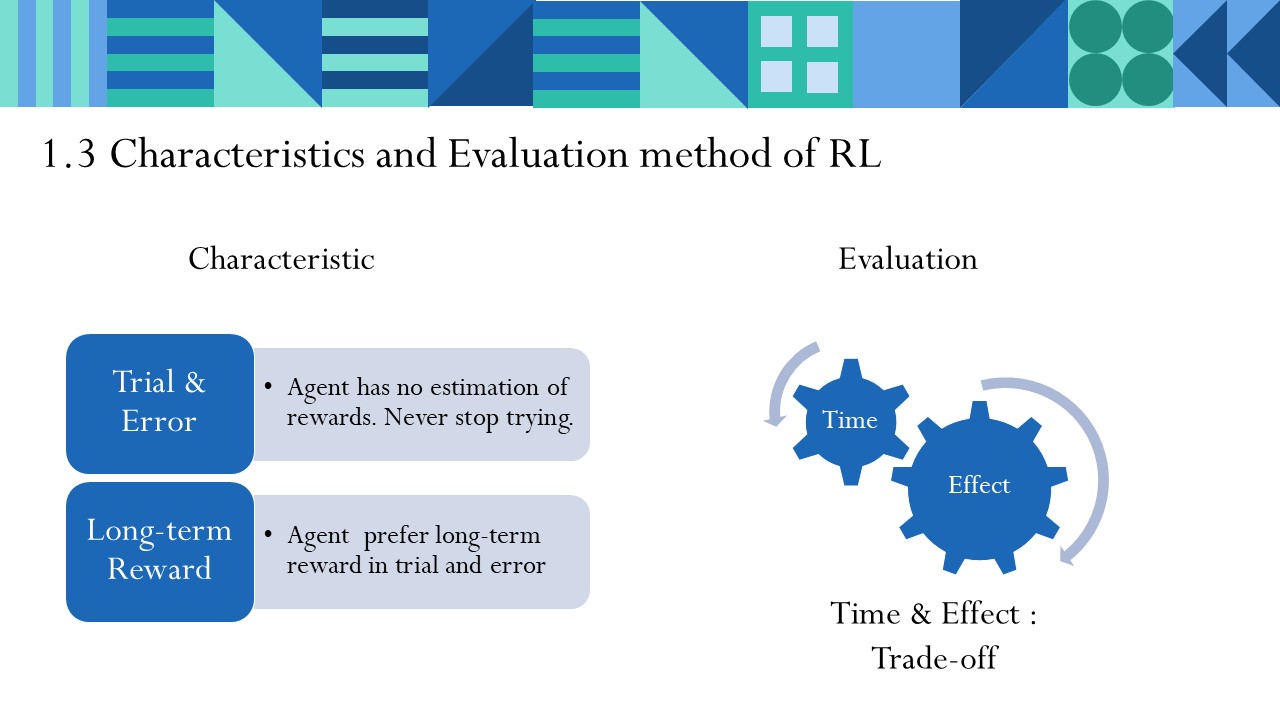
不断试错
Agent不知道自己给出行动会收到怎样的奖励,因此Agent必须不断尝试(Trial & Error),才能得到成功。
长期回报
Agent在不断试错之中,更加看中长时间尺度内能获得的回报,即使会遇到更多失败挫折。
因此评价强化学习的效果,常常看训练样本中学习的学习时间和学习效果。两者通常是Trade-off的关系。
1.4 强化学习与机器学习
强化学习是机器学习的一种。随着人工智能领域的发展,各分支开花结果。
人工智能、强化学习、深度学习,参考 https://zhuanlan.zhihu.com/p/36597546。
2 Q-Learning
好吧,你用心理学阐述的道理我都懂,那么,有没有一种算法,能让我立刻从数学的角度来看看强化学习的实现呢?那么请我们的Reinforcement Learning 101,Q-Learning登场。
2.1 Q-Learning决策
以将我们上述的俄罗斯方块进行量化:
在某个状态$latex S_1$,我能做出以下操作Action,并得到以下反馈Reward:
- $latex a_1$ 一下消除4行!结果爽到!!
- $latex a_2$ 一下消除1行,感觉还行。
- $latex a_3$ 一行都没消除!你在逗我?距离Gameover又近了一步!
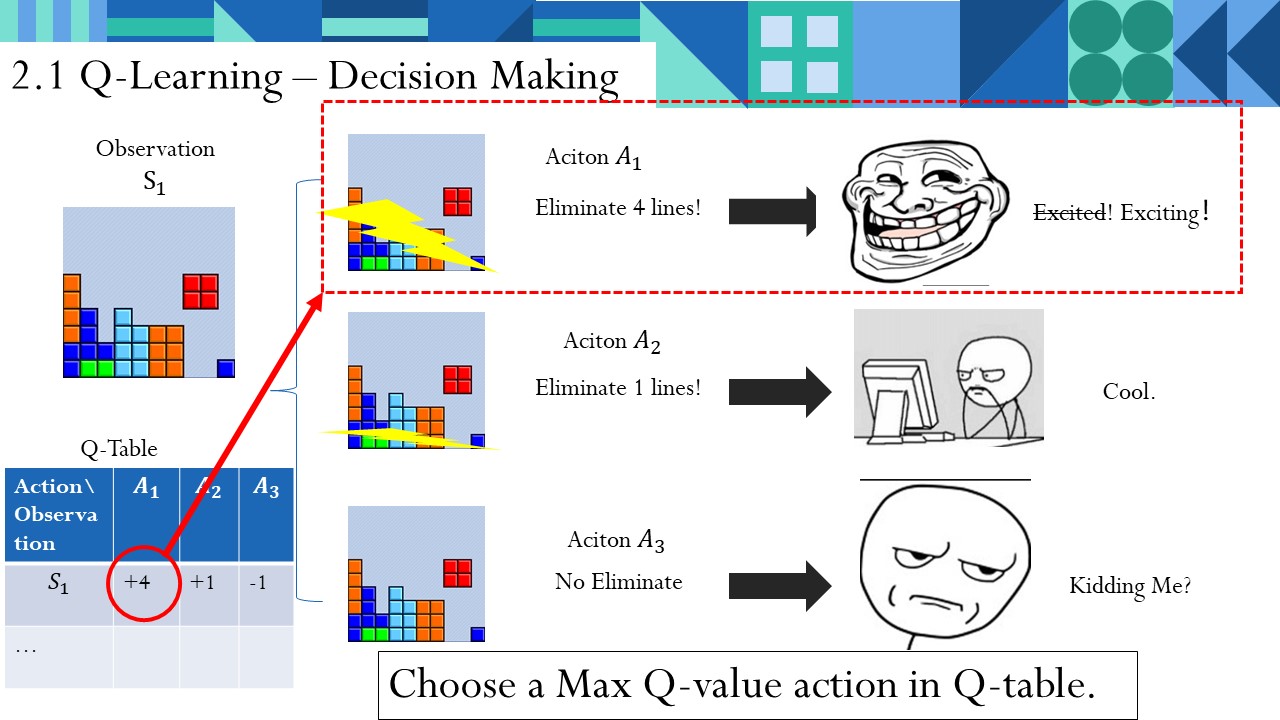
我是如何做出这些判断的呢?我的依据其实就是脑子中的一个叫做“Q-table”Q表的矩阵!
Q表:描述我在所有状态中所有行动的数值矩阵,我不管,我就在Q表中选这其中的最大值行动。
2.2 Q-Learning 更新
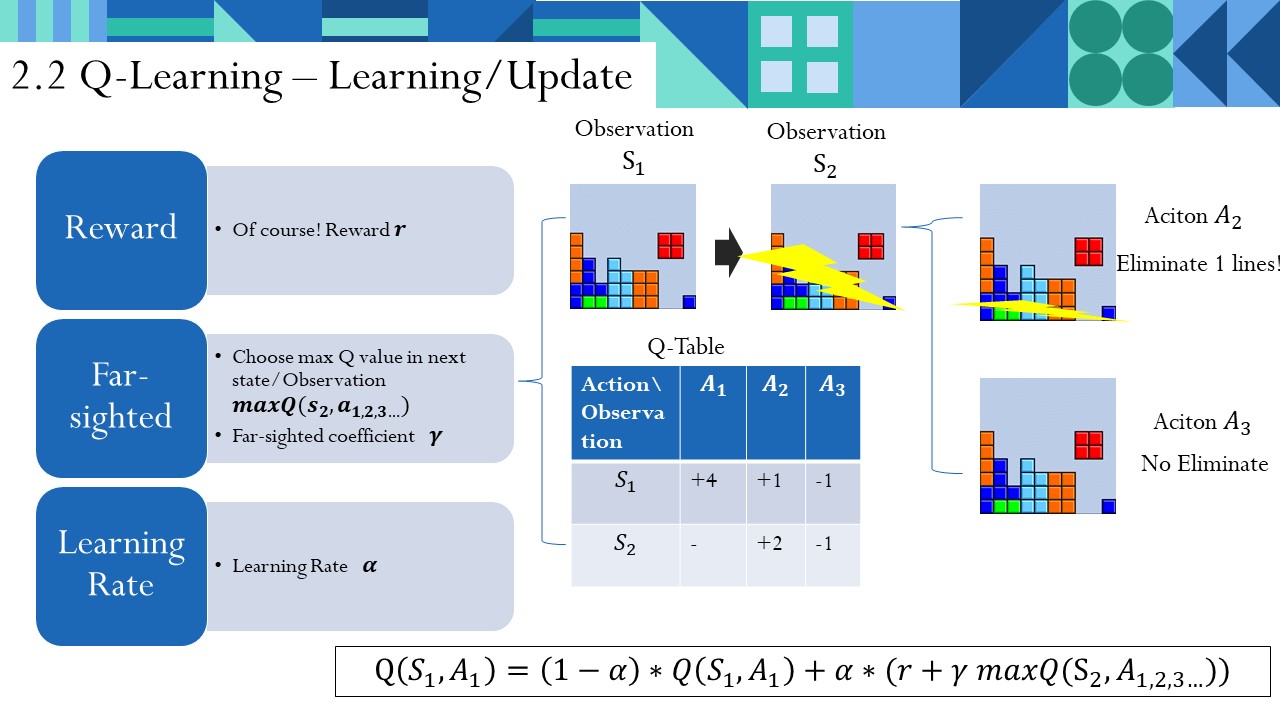
之前我们说了,我们是在不断地试错中学习,实际上就是在不断地以某种策略更新这个Q表。这个更新策略也是Q-Learning的特色。
经过在$latex S_1$做了$latex A_1$,我们有什么收获呢?
首先当然是Reward $latex r$。
但是,我们不能太短视,我们也要考虑下一步会给我带来的收益(依据Q表之前的经验)!我们选取下一状态$latex S_2$下,所有可能动作Aciton的Q值中最大的那个,代表我对下一步的远见。表示为: $latex $ 。我对这个远见要有一定的接受度,也就是说我要对这个远见有一定的加权系数处理,用 $latex \gamma$ 表示。
因此我在获得的对Q表中 $latex Q(S_1,A_1)$ 的总刺激就是 $latex r+\gamma maxQ(s_2,a_{1,2,3...})$ 。
我不能一下就将一下的刺激更新成我的Q表,因为可能有尖刺的数据。我总是要多试几次,逐渐迭代更新我的Q值。因此我设置一个学习率,$latex \alpha$ 。
因此我的Q值更新公式为:
$latex Q(S_1,A_1) = (1-\alpha)*Q(S_1,A_1)+\alpha*(r+\gamma maxQ(s_2,a_{1,2,3...}))$
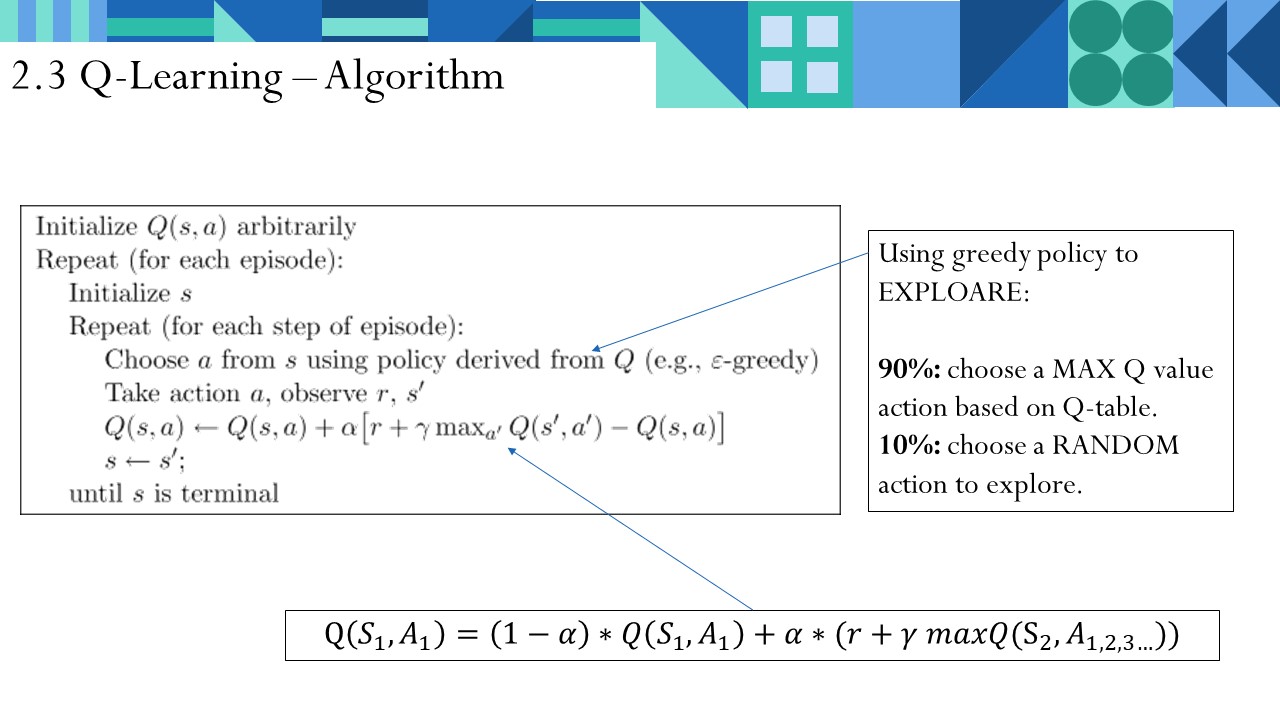
2.3 Q-Learning算法流程

Q-Learning算法流程如上图。在一定的episode里,我不断地重复、试错,更新Q表,直到某个时间点收敛。
2.4 Q-Learning性质
- 无环境模型 - QL不理解所处环境,没有对环境进行建模。是根据环境反馈,学习做出决策。
- 基于价值 - QL一定是选当前价值最高的action,十分“贪婪”。其他有基于概率的算法,如Policy Gradients。
- 单步更新 - QL在每走一步就更新Q表。有的算法是回合结束后更新。
3 实验
多说无益,Show me your code。
我参考了许多教程,大家一般是以“人工智障自己走迷宫”作为第一个RL实验。
我非常喜欢莫凡做的RL教程,通俗易懂。当然深入学习需要数学推导和专著论文的支持。我们可以来看下莫凡的基于Q-Learning的迷宫实验。
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/2-2-tabular-q1/
当然,做完上述迷宫实验后,我提出自己的问题,尝试用RL解决。
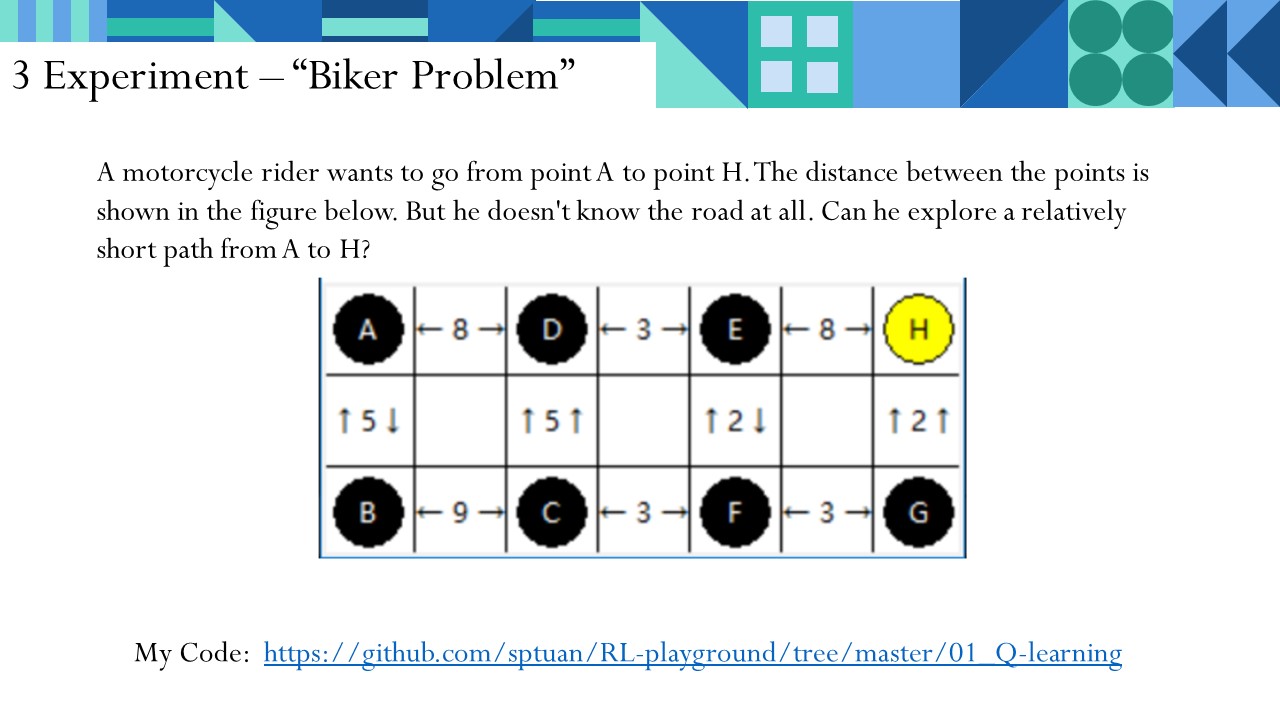
我的代码详见:
https://github.com/sptuan/RL-playground/tree/master/01_Q-learning/ex2
3.1 问题描述
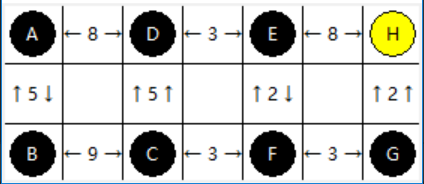
现在我们有这样的问题:
一个摩托车骑手,准备从A点出发,前往H点。各点之间的距离如下图所示。但他根本不知道道路,只能闷头尝试。能不能自己探索出一条相对短的路,从A点到H点?
3.2 问题抽象
env_tk.py
在此我们先建立我们的Environment。
我们将问题这样处理:是一个图。初始化有,给出一个目前的Observation。接收到action后,返回下一个Observation和这步action的Reward。在每步的action空间都为“上下左右”
关于Reward,我在本实验中,如下处理:将路的长度乘以-1作为reward。如A到了D,则给予-8的奖励(或者说是8的惩罚)。到达H后,给予100的奖励,结束回合。若做出不可能的动作,如A向上走,则给予-10000的奖励,结束回合。
"""
Reinforcement learning maze example.
This script is our Q-Learning brain.
This script is modified from https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
import os
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
#state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
action = state_action.idxmax()
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'H1':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
os.system('cls')
print(self.q_table)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
主要是对Q-Learning算法功能上的实现。分为决策choose_action(),Q-table更新learn()。
调度RL-brain和env_tk。主要是对Q-Learning算法流程上的实现
"""
Reinforcement learning maze example.
This script is our main script, in which a bike driver tries to arrive at FINAL POINT.
This script is modified from https://morvanzhou.github.io/tutorials/
"""
from env_tk import Maze
from RL_brain import QLearningTable
def update():
for episode in range(10000):
# initial observation
# return state, format "A B C ..."
action_space = env.action_space
observation = env.reset()
while True:
# fresh env, tkinter
env.render()
# RL choose action based on observation
#while True:
action = RL.choose_action(str(observation))
if action == 0:
action_step = 'UP'
elif action == 1:
action_step = 'DOWN'
elif action == 2:
action_step = 'RIGHT'
elif action == 3:
action_step = 'LEFT'
#if action_step in action_space:
# break
# RL take action and get next observation and reward
observation_, reward, done, action_space = env.step(action_step)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(4)))
env.after(50, update)
env.mainloop()
3.3 实验结果
约100秒后结果收敛。
- 成功找到了终点。
- 但是结果不是最优解,陷入了局部最优解中。
虽然不是最优解,但人工智障经过不停地碰壁后,成为了合格的人工智能!
4 总结
本文从例子引入强化学习,先从心理学分析了Reinforcement Learning。然后以“俄罗斯方块”为线索,介绍了Q-Learning的基本算法。最后通过实验,解决“摩托车手最短路径问题”。人工智障经过不停地碰壁后,成为了合格的人工智能!可喜可贺,可喜可贺!
5参考资料
[1] 莫凡的强化学习教程 https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/
[2] Q-Learning Tutorial by Kardi Teknomo - Published by Revoledu.com
[3] Reinforcement Learning: An Introduction. Richard S. Sutton and Andrew G. Barto




哈哈,人工智障,博主很萌啊
@汽修软件 能稍微引起读者的兴趣,就算是我小小文章的成功啦
@SPtuan 哈哈
这难道是研究生课题
@xywang 呵呵,那是不可能的
国庆快乐!
impppppppport
@John Raymond
import 毕业启动!
import 公务员启动!
import 养老启动!
@John Raymond
import 退学