嗨多磨。在之前的文章中,我们以Q-Learning为例,先入为主,对强化学习的基本要素和核心思想进行了学习。今天这篇文章,主要是将马尔科夫决策过程单独拿出来探究。它在很多领域都有应用,十分值得单独拿出进行探究和学习。
封面图片:Markov Decision Process - https://commons.wikimedia.org/wiki/File:Markov_Decision_Process.svg
Table of Contents
1 引入
也许我之前或多或少听过“马尔科夫(Markov)”相关的理论和模型。但作为新手,如何对它们有一个宏观的认识呢?来看一下它们的分类。
在概率论中,马尔可夫模型是用于模拟随机变化系统的随机模型。这些模型最显著的特点,就是“假设未来的状态仅依赖于当前状态,而不依赖于它之前发生的事件”。这也是著名的马尔科夫属性:
A stochastic process has the Markov property if the conditional probability distribution of future states of the process (conditional on both past and present states) depends only upon the present state, not on the sequence of events that preceded it.
即,如果过程的未来状态的条件概率分布(以过去和现在状态为条件)仅依赖于当前状态而不依赖于其之前的事件序列,则随机过程具有马尔可夫属性。
换句人话?那就是,如果我们观察到系统的一个状态,这个系统接下来的状态转换的概率只当前的这个状态有关,我们不用去揣测之前它的状态如何。
对马尔科夫模型进行分类,则常见模型可以这样布局在表格中(来自Wikipedia):

根据系统是自治的还是被控制的(autonomous or controlled),系统状态能不能全部观测(fully/partially observable),分为马尔可夫链(Markov Chain),隐马尔科夫模型(Hidden Markov Model,HMM),马尔科夫决策过程(Markov Decision Process),部分观测的马尔科夫决策过程(Partially observable Markov decision process)。
1.1 马尔科夫链 Markov Chain
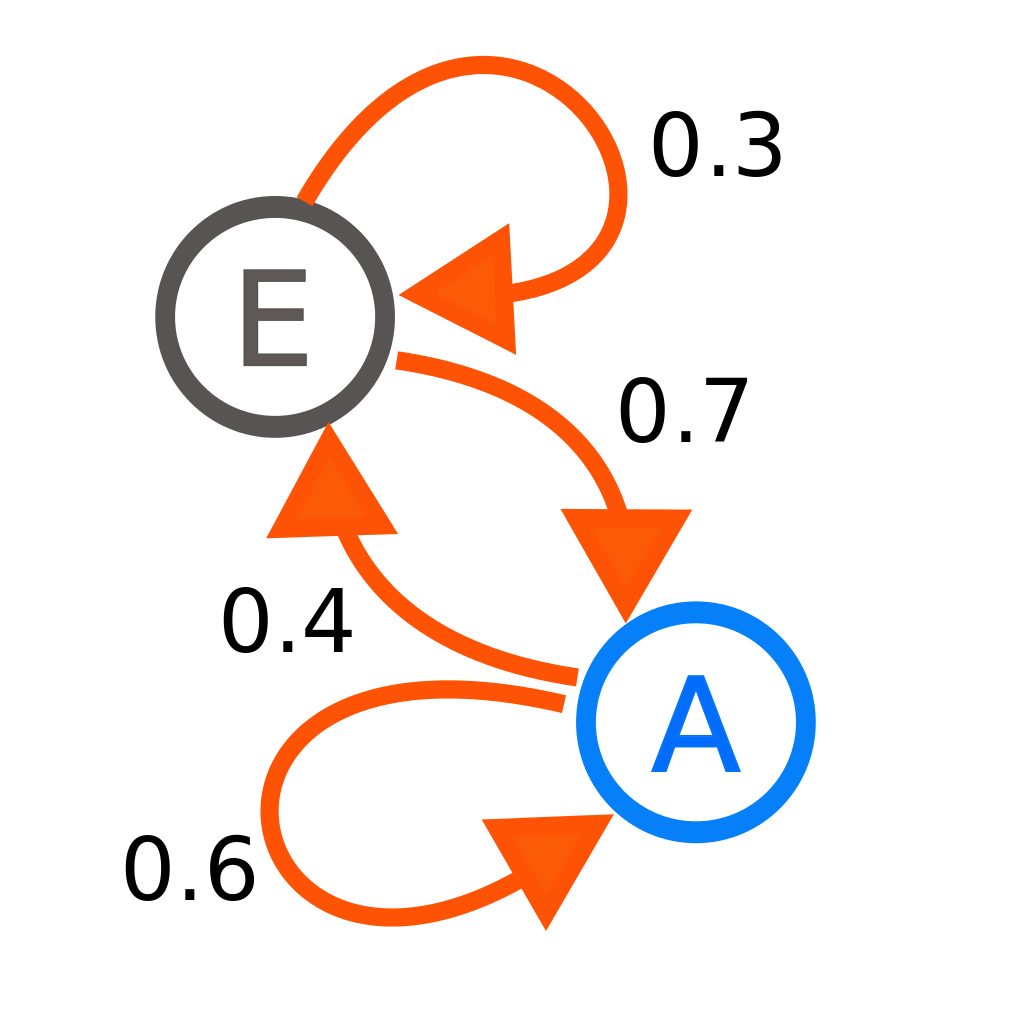
马尔科夫链是最简单的马尔科夫模型。使用马尔科夫性质可以对进行建模。利用这一性质,可以使用随机游走(Random Walk)在联合分布重采样,即马尔可夫链蒙特卡罗(MCMC)。
1.2 隐马尔科夫模型 Hidden Markov Model,HMM
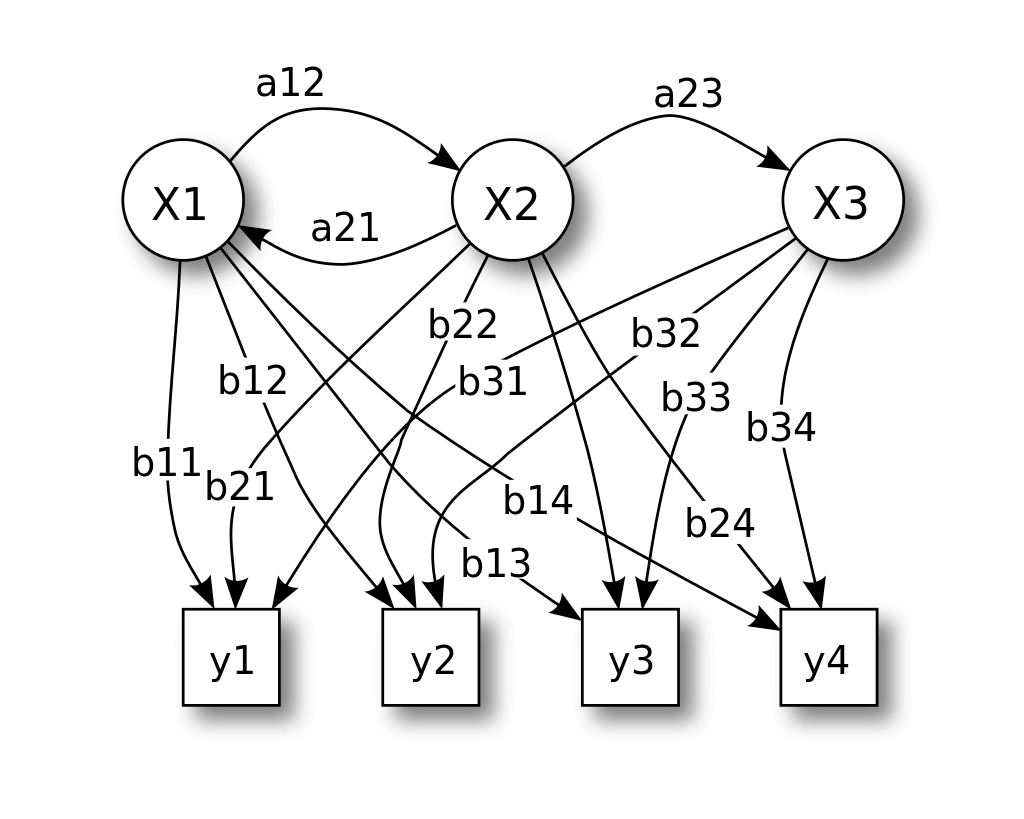
如果系统状态仅能部分观测到,换句话说是只能观察到和系统状态有关但不能直接精确确定系统状态的量。HMM在语音识别领域中经常被提到,观察到的波形,背后的隐藏状态是文本。
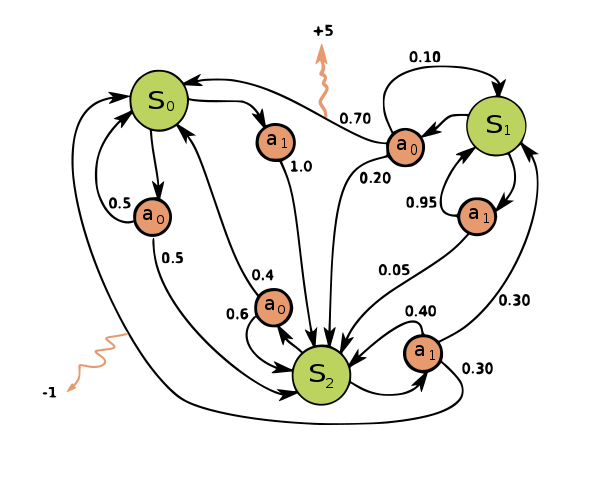
1.3 马尔科夫决策过程 Markov Decision Process
现在开始涉及到,我能够对系统施加影响了。状态转移依赖于当前状态和施加到系统中的矢量。MDP用于计算与决策,实现最高奖励的目标。这部分和强化学习息息相关。
1.4 部分观测的马尔科夫决策过程 Partially Observable Markov Decision Process
部分观测的马尔科夫决策模型。POMDP是NP完整问题。
马尔科夫决策过程是我们今天的主角,我们将依据材料,对其中部分原理进行推导。笔者有幸刚刚开始探讨这个问题,希望大牛们能多多指出其中的纰漏和错误,谢谢!
2 马尔科夫决策过程 Markov Decision Process
马尔科夫决策过程MDP可以说是强化学习算法的基石。本节的主要目的是通过对马尔科夫的决策过程进行数学推导,加强我们对强化学习的认识。
star——星星?并不是,其实是我在学习过程中看到马尔科夫决策过程分别由$latex s,t,a,r$等基本元素组成。: )
2.1 行动链条
第一节中我们已经对MDP的突出性质和特点进行讨论。考虑我们现在有个小扫地机器人,行驶在一维的直线上。这是一个典型的MDP模型——小机器人可以和环境进行控制交互。先不考虑连续系统的离散化问题。
现在我们用属于状态空间$latex S$中的$latex s_t$表达我们在$latex t$时刻观测到的状态,$latex a_t$表示我们在$latex t$时刻做出的行动,那么这个小机器人的交互过程可以用以下的行动链条表示:
$latex {\{s_0,a_0,s_1,a_1,...,s_{t-1},a_{t-1},a_t\}}$
我们在两个角度去看待这个链条:
- 下一个状态是环境决定的
- 下一个动作是小机器人的策略决定的
2.2 下一个动作
那么小机器人是以什么样的依据进行决定呢?实际上,它的策略映射到一个表征策略的概率函数上:
$latex a_t^*=argmax_{a_{t_i}}p(a_{t_i}|{\{s_0,a_0,s_1,a_1,...,s_{t-1},a_{t-1},a_t\}})$
argmax表示取使函数最大的自变量,星表示最优策略。
由于是马尔科夫过程,未来状态的条件概率分布(以过去和现在状态为条件)仅依赖于当前状态而不依赖于其之前的事件,即当前选择什么行动只和当前有关,最优就变成了
$latex a_t^*=argmax_{a_{t_i}}p(a_i|{s_t})$
使用了马尔科夫序列性质将寻优过程大大简化。
2.3 下一个状态
要知道我们的世界是充满不确定性的,机器人控制有一本很著名的书叫做《概率机器人》,也是在讲如何用概率的观点去解决不确定性问题——我们要用概率去理解这个不确定性过程。因此引入概率转移函数$latex T$,它实际上就是来回答:
$latex p(S_{t+1}|S_t,a_t)$
也就是说,小机器人做出行动后,是由一定概率才能跳到某一状态的。
2.4 奖励、近视远视与贝尔曼方程
聪明的你可能会想到,我们有了策略来选择行动,那么这个策略是怎么养成的呢?实际上,在MDP模型中,每次从一个状态到另一个状态时,环境会给我们一个汇报$latex r$。
这个汇报是短视的,只能体现这一步。那怎么样才能让它变成“远视”性的奖励?注意到,我们假设这个过程时间性上无穷的序列,在不停地重复迭代中,我们设置一个减弱的“打折”函数,来表示长期的回报:
$latex \sum{\gamma^t r_k}$
这样就可以随着未来的步数增长,逐渐指数减弱影响。这个减弱程度是可以调整的。
设$latex v_\pi$为依据回报得到的价值函数,那么根据我们之前设置的“远视”系数,可以表示为:
$latex v_\pi(s_t)=\sum^{\infty}_{k=0}\gamma^t r_k$
可是这仍然很麻烦,要算无穷步吗?接下来贝尔曼方程就来发威了。拆出来2项,大大不同了:
$latex v_\pi(s_t)=\sum^{\infty}_{k=0}\gamma^k r_k$
$latex = r_t + \gamma\sum^{\infty}_{k=1}\gamma^{k-1} r_k$
$latex = r_t + \gamma v_\pi(s_{t+1})$
贝尔曼方程把它变成了迭代的形式,只和下一步有关!因此我们可以使用迭代求值函数,也就是上一文章的Q-Learning方法。
3 总结
本文将MDP单独拿出进行探究和学习。首先了解了常见的马尔科夫模型,然后对马尔科夫决策模型进行数学的漫谈,最后通过贝尔曼方程,解释上一文章中的QL方法迭代的理论依据。
本文是笔者学习MDP的学习手记,比较主观,有建议或者发现错误之处请让告知我,多谢各位的指导!




[…] 2018-12-26 强化学习102 – 马尔科夫决策过程(Markov Decision Process)的学习笔记 […]
你好,文章最后部分出现的价值函数,衰减系数的次方是否字母有误?
@Alexander 您好,谢谢回复!我的行文可能不太严谨。
最后的价值函数,次方的字母k想表达的意思是,需要将t带入k中,k是一个中间变量。凭空出现的k可能给您带来了疑惑
近日处理学校事宜,回复晚了请见谅! ^_^
@Alexander 想表达的意思是,整体求和中取出k=0的一项,然后再从求和式中,提出1个系数lambda,发现 原式=当前奖励 + 衰减系数*下一状态s(t+1)的价值函数,这样的话就可以通过迭代探索出价值函数的解了
证书链错误
@平凡之路 仍然错误吗?网页本体和静态资源都交给了主机商做自动分发,有时候我挂美东代理会有ssl错误
一脸懵逼的进来,看完还是一脸懵逼的出去……
期待
存货先放出来 :) 这篇文章得大修