EC/LRC 纠删码的基本原理、优劣与成本性能模型,为分布式存储冗余与修复设计打基础。
理解本文,读者将收获
- EC/LRC 编码的基本数学原理
- EC/LRC 编码的优势和缺点
- EC/LRC 编码成本和性能核算模型
以下内容超出本文范围
- 如何编写一个工业级的 EC 编解码库

Table of Contents
1. 技术背景和动机
在前些篇文章中,我们已经使用了很大篇幅去描述 “复制(增加数据冗余度)” 的重要性。
一种广泛应用且简单的复制方式即副本复制。然而副本复制存在一些问题,使我们不得不寻找更加灵活的编码方式去增加数据冗余度。
单纯使用副本复制,存在以下局限性:
- 只能以数据整数倍扩增,比如 1 副本、2 副本、3 副本等等。
- 一般经验上,结合硬件的故障率,至少需要使用 3 副本才能满足数据的安全性保证。
- 成本因此至少承担 3 倍数据的存储、写带宽。
实际上不是所有的数据都值得使用 3 倍冗余去储存。梳理下就会发现,根本的技术障碍为:整数倍的冗余。
一旦能够打破这个限制,我们能够根据实际的硬件损坏概率,灵活地安排冗余度/成本/性能的平衡。
因此实际的技术需求变为:我们需要一种编码方式,能够
- 灵活安排数据和冗余的配比
- 冗余信息熵逼近故障容忍所需的熵增量
- 计算相对快速
- 易于理解和控制
Erasure Code (EC) 因符合上述需求,被分布式存储广泛使用。
2. EC 编码原理
关于 EC 编码的简明数学原理和工程经验。另可参考 OpenACID Blog 优秀的 EC 系列文章123。工程上一般直接使用成熟的编码库,如 Intel ISA-L4 等。
2.1 多项式插值
回忆一下代数基础:两点确定一条直线,三点确定一条抛物线。更严谨的表述为:k 个横坐标不同的点,可以唯一确定一个最高 k-1 次的多项式。 这就是拉格朗日插值定理,也是整个 EC 编码的数学基石。
不妨用一个具体例子来看它如何产生冗余。假设有 2 个数据值 d_0 = 3, d_1 = 5,将它们作为多项式系数,构造一次多项式:
f(x) = 3 + 5x这条直线上的每个点都编码了 d_0, d_1 的全部信息。在 x = 1, 2, 3, 4 处分别求值:
f(1) = 8, \quad f(2) = 13, \quad f(3) = 18, \quad f(4) = 234 个值中任取 2 个,就能通过解二元一次方程组还原 d_0 = 3, d_1 = 5。多出来的 2 个值就是冗余——丢掉任意 2 个,剩下的仍然够用。
推广到一般情形:将 k 个数据值作为多项式系数,
f(x) = d_0 + d_1 x + d_2 x^2 + \cdots + d_{k-1} x^{k-1}在 k + r 个不同的点上求值(r \geq 1),得到 k + r 个编码值。其中任意 k 个即可通过插值还原多项式,进而恢复全部数据。多出来的 r 个值,就是校验信息。
这就是 EC 编码的核心思路:用多项式的冗余求值产生校验数据,用插值恢复丢失数据。
2.2 EC 编解码:输入与输出
感性上,不妨先将 EC 编解码器当做一个黑盒来理解——输入数据块,输出校验块。
不妨想象一个 4MiB 的数据。由于内部是矩阵计算,我们需要确定这次编码的块的长度,不妨定为 1MiB。则我们得到 [D1, D2, D3, D4] 共 4 份,每份长度为 1MiB 的数据块。
我们也可以决定要输出多少个校验块出来,不妨设为 2 块。则编码器输出 [P1, P2] 共 2 份,每份长度为 1MiB 的校验块。
最终得到的块序列为 [D1, D2, D3, D4, P1, P2]。我们记为 EC(4,2)。
总结下,我们可控的 EC 编码器的参数为
- 块的长度:单个数据块的长度 B
- 数据块数量:m
- 校验块数量:n
则编码器的输入输出如下:
- 编码输入为: m 个 长度为 B 的数据块
- 编码输出为:n 个 长度为 B 的校验块
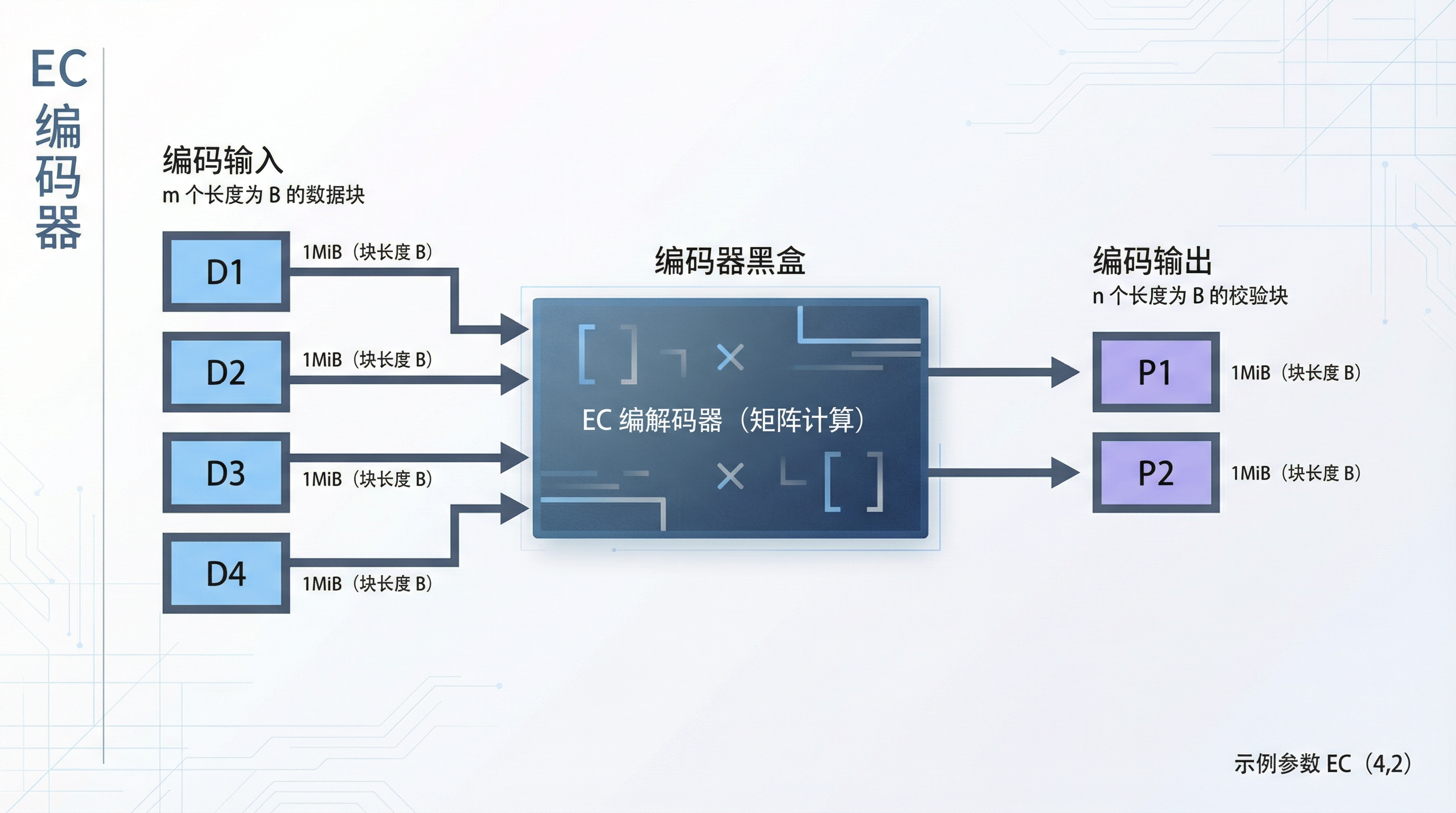
图: EC 的编码器
别忘了 EC 的目的是冗余和数据修复。我们因故缺失了一些数据块,则需要解码器修复原始数据。
对于我们上述的 EC(4,2),设序列为 [D1, D2, D3, D4, P1, P2]。假设丢失了 D1 和 D4,则可根据 [D2, D3, P1, P2] 解出 [D1, D4]。
图: EC 的解码器
2.3 有限域与精确计算
上面的例子用的是实数运算,直观易懂。但在工程实现中,直接对实数做多项式插值有一个致命问题:浮点精度。
考虑一个 k = 10 的多项式,系数都在 0~255 之间。在较大的求值点上,x^9 的量级已经很大,浮点乘法和加法的累积误差不可忽视。而数据恢复要求精确到每一个 bit——差一个 bit 就是数据损坏。
解决办法是将运算搬到有限域(Galois Field)上。EC 编码中最常用的是 \text{GF}(2^8),即由 256 个元素构成的有限域,恰好对应一个字节的取值范围 [0, 255]。
\text{GF}(2^8) 有几个工程上非常友好的性质:
| 性质 | 说明 |
|---|---|
| 运算封闭 | 加减乘除的结果仍在 [0, 255] 内,无溢出 |
| 加法 = XOR | 按位异或即可,CPU 一条指令完成 |
| 乘法可查表 | 256 \times 256 的乘法表仅 64KB,可预计算;现代实现用 SIMD 指令并行查表 |
| 精确可逆 | 不存在精度损失,编解码完全可逆 |
将前面的实数多项式替换为 \text{GF}(2^8) 上的多项式后,所有运算在单字节内完成,结果精确且高效。实际的 EC 编码库(如 Intel ISA-L、Jerasure5 等)内部都基于有限域运算。
2.4 编码矩阵
多项式在不同点上的求值过程,可以写成矩阵乘法的形式。这让 EC 编码的结构变得更加清晰。
对于 \text{EC}(m, n)(m 个数据块,n 个校验块),编码过程为:
\vec{c} = G \times \vec{d}其中 \vec{d} 是 m \times 1 的数据向量,\vec{c} 是 (m+n) \times 1 的编码输出,G 是 (m+n) \times m 的生成矩阵。生成矩阵的结构如下:
G = \begin{bmatrix} I_m \\ C \end{bmatrix}上半部分 I_m 是 m \times m 单位矩阵,保证数据块原样输出,即系统码(systematic code)。下半部分 C 是 n \times m 的编码子矩阵,决定校验块的计算方式。
编码子矩阵 C 的常见选择有两种:
-
Vandermonde 矩阵:最经典的构造方式,直接来源于多项式在不同点上的求值。理论上清晰直观,但要构造系统码(上半部分为单位矩阵),需要对原始 Vandermonde 矩阵做一次行变换,实现上多一步。早期的 RS 编码库大多基于这种构造。
-
Cauchy 矩阵:任意子矩阵天然可逆,构造系统码时可以直接使用,省去行变换的步骤。更重要的是,基于 Cauchy 矩阵的编解码可以进一步优化为纯 XOR 操作6,避免了有限域乘法的开销,编解码吞吐量通常优于 Vandermonde 方案。现代工业级编码库(如 Intel ISA-L)普遍采用这一构造。
无论选用哪种矩阵,核心要求只有一个:G 的任意 m 行构成的 m \times m 子矩阵必须可逆。 只有满足这个条件,丢失任意 n 个块时,才能从剩余的 m 个块恢复全部数据。
解码过程也由此矩阵定义。设丢失了若干块,将剩余 m 个块对应的行从 G 中取出,组成子矩阵 G'。对 G' 求逆,乘以剩余块的数据,即可还原原始数据:
\vec{d} = {G'}^{-1} \times \vec{c'}满足"任意 m 行可逆"这一性质的码,称为最大距离可分码(MDS, Maximum Distance Separable)。Reed-Solomon 码就是一种 MDS 码,它达到了编码理论中 Singleton 界的上限——在相同冗余度下,容错能力最优。
3. EC 的工程考量
理解了 EC 编码的数学原理之后,接下来从工程视角审视它的冗余效率、数据布局、性能、成本和数据安全性。
3.1 冗余度与 MDS 最优性
引入存储放大率来量化冗余的代价:
\text{存储放大率} = \frac{m + n}{m}对于 \text{EC}(4,2),存储放大率为 6/4 = 1.5,即每存 1 字节的有效数据,实际占用 1.5 字节。与 3 副本的 3.0x 相比,存储成本几乎减半。
MDS 码的意义在于:在给定的存储放大率下,容错能力达到理论上限。 编码理论中的 Singleton 界指出,一个编码的最小距离 d 满足 d \leq n + 1(此处 n 为校验块数)。MDS 码恰好取到等号,即 \text{EC}(m, n) 可以容忍任意 n 个块同时丢失,不多不少。
以下是几种常见配置下 EC 与副本方式的对比:
| 编码方式 | 存储放大率 | 可容忍故障数 | 说明 |
|---|---|---|---|
| 2 副本 | 2.0x | 1 | 容错能力不足,生产环境少用 |
| 3 副本 | 3.0x | 2 | 分布式存储的经典选择 |
| EC(4,2) | 1.5x | 2 | 同等容错,成本减半 |
| EC(6,3) | 1.5x | 3 | 容错更强,放大率不变 |
| EC(10,4) | 1.4x | 4 | 大规模冷数据常见配置 |
| EC(12,4) | 1.33x | 4 | 存储放大率更优 |
从表中可以看出 EC 相对于副本的成本优势。但天下没有免费的午餐——EC 在性能和修复代价上付出的额外代价,后续小节会详细讨论。
3.2 数据条带化布局
EC 编码以条带(stripe)为单位组织数据。一个条带由 m 个数据块和 n 个校验块组成,共 m + n 个块分别存放在不同的节点或磁盘上。
以 \text{EC}(4,2) 为例,一个条带包含 6 个块 [D1, D2, D3, D4, P1, P2],分布在 6 个不同节点上。每个块的大小(Block Size)通常在 256KB ~ 4MB 之间,具体取决于系统设计。
条带化布局带来一个核心问题:写入粒度与条带大小的匹配。
全条带写入(Full-stripe Write)
当一次写入的数据恰好填满一个条带的 m 个数据块时,编码器直接计算 n 个校验块,将 m + n 个块并行写入各节点。这是最高效的写入方式:一次编码,一次并行写入。
部分条带写入(Partial-stripe Write)
更常见的情况是用户写入的数据不足以填满整个条带。此时有两种处理策略:
-
缓存凑齐:将不完整的写入缓存在内存中,凑齐一个完整条带后再编码写入。写放大低,但引入了写延迟和内存压力,且需要额外手段保证缓存期间的数据安全。
-
读-改-写(Read-Modify-Write):读取条带中已有的数据块和校验块,合并新数据后重新计算校验块,再写回。写放大较高,但延迟可控。
写入策略对系统设计的影响
实际的分布式存储系统中,不少采用折中策略:数据写入时先以副本形式落盘(通常为 3 副本),由后台任务异步地将冷数据转码为 EC 格式。Azure Storage7 和 CubeFS 等系统采用了类似的方案。这种做法兼顾了写入延迟(副本写入简单快速)和长期存储成本(EC 存储放大率低)。
3.3 性能模型
EC 的性能开销主要体现在三个维度:编解码计算、读路径和写路径。
编解码的 CPU 开销
EC 编解码本质上是 \text{GF}(2^8) 上的矩阵运算。早期实现确实有可观的 CPU 开销,但现代编码库已经将其压到很低的水平。以 Intel ISA-L 为例,利用 AVX-512 指令集,编码吞吐量可达数十 GB/s(取决于 EC 参数和 CPU 型号)4。对 HDD 集群而言,磁盘 IO 远先于 CPU 成为瓶颈。对全闪集群则需要实际测量。
读路径
正常读取时,由于 EC 采用系统码,数据块原样保存,读一个数据块只需访问一个节点,与副本方式无异。
当某个数据块所在节点不可用时,需要进行降级读(degraded read):从其他节点读取 m 个存活块,解码恢复目标数据块。降级读的延迟约为:
T_{\text{degraded}} \approx \max(T_{\text{read}_1}, T_{\text{read}_2}, \dots, T_{\text{read}_m}) + T_{\text{decode}}即取 m 次并行读取中最慢的那个,再加上解码时间。m 越大,撞到某个慢节点的概率就越高,尾延迟问题越明显。
对比 3 副本的降级读——只需从另一个健康副本读取即可,延迟基本不变。这是 EC 在延迟敏感场景下的主要劣势。
写路径
每次全条带写入需要写 m + n 个块,写放大率为 (m + n) / m。写入延迟同样取决于最慢的那个节点。m + n 越大,尾延迟越明显。
EC 参数对性能的影响趋势:
| EC 参数变化 | 降级读代价 | 写延迟 | 编解码 CPU | 正常读 |
|---|---|---|---|---|
m 增大 |
需读更多块,尾延迟上升 | 总块数增加 | 矩阵更大,计算量上升 | 无影响 |
n 增大 |
不直接影响 | 总块数增加 | 矩阵更大,计算量上升 | 无影响 |
一般来讲,EC 更适合以大块顺序写为主、读取频率较低的冷温数据场景。对延迟敏感的热数据,副本方式通常更合适。
3.4 成本模型
EC 的成本优势主要体现在存储空间上,但在带宽和修复方面需要付出额外代价。
存储成本
如前所述,\text{EC}(m, n) 的存储放大率为 (m+n)/m。相比 3 副本的 3.0x,常见的 EC 配置通常在 1.25x ~ 1.5x 之间。对于 PB 级别的集群,这意味着可观的硬件成本节省。
简单估算:假设集群有 100PB 有效数据,3 副本需要 300PB 原始容量,EC(10,4) 只需要 140PB。节省的 160PB 按当前 HDD 成本约 \$20/TB 计算,硬件差异约 320 万美元。
带宽成本
带宽成本体现在两个方面:
- 写入带宽放大:每写入
m块有效数据,实际传输m + n块,放大率为(m+n)/m。 - 修复带宽放大:单个块损坏时,需要从其他节点读取
m个块才能恢复 1 个丢失块。修复带宽放大率为m : 1。对比副本方式,修复一个副本只需复制另一个健康副本,带宽放大率为1 : 1。
| 编码方式 | 存储放大 | 写带宽放大 | 单块修复读取量 |
|---|---|---|---|
| 3 副本 | 3.0x | 3.0x | 读 1 块 |
| EC(4,2) | 1.5x | 1.5x | 读 4 块 |
| EC(10,4) | 1.4x | 1.4x | 读 10 块 |
| EC(12,4) | 1.33x | 1.33x | 读 12 块 |
m 越大,存储越省,但修复时需要读取的数据量越大。这是 EC 编码中最核心的 trade-off 之一,也是后续 LRC 编码试图优化的方向。
3.5 数据安全性模型
\text{EC}(m, n) 可以容忍任意 n 个块同时丢失。但"同时"这个词值得仔细审视——在大规模集群中,磁盘故障不是瞬间事件,修复也需要时间。真正的风险在于:修复完成之前,是否会有更多块接连损坏。
修复窗口与 MTTR
一个典型的场景:集群中某块磁盘损坏,该磁盘上所有条带都进入降级状态(缺少一个块)。系统需要尽快修复这些条带——从其他节点读取 m 个存活块,解码出丢失块,写到新的位置。
修复时间(MTTR, Mean Time To Repair)取决于:
\text{MTTR} \approx \frac{\text{磁盘容量} \times m}{\text{可用修复带宽}}分子中的 \times m 来自修复放大:每恢复 1 个块需要读 m 个块的数据。假设一块 10TB 磁盘使用 \text{EC}(10,4),集群分配给修复任务的带宽为 500MB/s:
\text{MTTR} \approx \frac{10\text{TB} \times 10}{500\text{MB/s}} \approx 55 \text{ 小时}55 小时的修复窗口意味着:在此期间,若同一条带再损坏 3 个块(概率虽小但非零),数据就永久丢失了。
MTTDL 估算
MTTDL(Mean Time To Data Loss)是衡量数据安全性的核心指标。粗略估算8时:
- 单盘年故障率(AFR)约为 1~4%
- 集群共
N块磁盘 - 使用
\text{EC}(m, n),需要同一条带的n + 1个块在修复窗口内同时损坏才会丢失数据
磁盘数量越多、单盘容量越大、m 越大,修复窗口就越长,连续故障的概率就越高。反过来,提高修复带宽、缩短 MTTR 是最直接的安全手段。
集群修复的连锁效应
一块磁盘故障后,修复流量会涌入集群的网络和磁盘 IO。如果此时另一块磁盘也损坏(这在大集群中并不罕见),修复压力进一步叠加。更糟糕的是,修复流量会与正常业务流量竞争带宽,导致用户侧延迟升高。
这种连锁效应在 m 较大时尤为明显:修复每个条带需要读 m 个块,集群中需要修复的条带越多,修复风暴的压力就越大。因此生产环境中的 EC 参数选择,需要在存储成本与修复安全之间仔细权衡。
3.6 EC 编码小结
总结 EC 编码的核心性质:
- 数学基础:基于有限域上的多项式插值和矩阵运算,编解码精确可逆。
- 冗余效率:MDS 码在给定冗余度下达到最优容错,存储放大率远低于多副本。
- 性能代价:降级读需读
m个块并解码;写入需计算校验块;m和n越大,尾延迟越明显。 - 修复代价:恢复 1 个丢失块需读取
m个块,修复带宽放大为m : 1。这是 EC 最突出的工程痛点。
EC 编码适合大块顺序写为主、读取频率较低的冷温数据。对热数据或延迟敏感的场景,通常仍首选副本方式。
值得注意的是,修复带宽 m : 1 的放大是 EC 方案中一个持续的工程负担。能否在保持存储效率的同时降低修复代价?这正是下一节 LRC 编码要解决的问题。
4. LRC 编码:降低修复代价
上一节指出,EC 编码最突出的工程痛点是修复带宽放大:恢复 1 个丢失块需要读取 m 个块。在大规模集群中,单盘故障是常态事件,m 较大时的修复风暴会严重影响集群的正常业务。
一个自然的想法是:能不能在条带内部分块建立"局部校验",使得单块故障只需读取少量块就能修复,而不必惊动整个条带的全部 m 个块?
LRC(Locally Repairable Code,局部可修复码)正是沿着这个思路设计的。其核心论文由 Microsoft Research 发表9,并在 Azure Storage 中大规模部署。
4.1 LRC 编解码器
LRC 的核心思路是在标准 EC 的基础上,增加一层局部校验块(Local Parity)。
以 Azure Storage 使用的 \text{LRC}(12, 2, 2) 为例。12 个数据块被分为 2 个局部组,每组 6 个数据块:
- 局部组 1:
[D_1, D_2, D_3, D_4, D_5, D_6]→ 计算局部校验块LP_1 - 局部组 2:
[D_7, D_8, D_9, D_{10}, D_{11}, D_{12}]→ 计算局部校验块LP_2 - 全局校验:基于全部 12 个数据块,计算 2 个全局校验块
GP_1, GP_2
最终一个条带包含 16 个块:12 个数据块 + 2 个局部校验块 + 2 个全局校验块。
局部校验块 LP_i 的计算方式与普通 EC 校验块相同,只是作用范围限定在本组内。实际实现中通常就是组内数据块的 XOR(即 \text{EC}(6,1) 的特殊情况)。
单块修复:局部修复的优势
当 D_3 丢失时,传统 \text{EC}(12,4) 需要读取 12 个块来修复。而 LRC 只需要读取同组的 [D_1, D_2, D_4, D_5, D_6, LP_1] 共 6 个块,通过局部校验即可恢复 D_3。
修复读取量从 12 块降到了 6 块——修复带宽减半。更一般地,如果每个局部组有 l 个数据块,单块修复只需读取 l 个块(而非全部 m 个块)。
多块修复:全局校验兜底
局部校验只能应对组内单块故障。如果同一组内有 2 个块同时丢失,局部校验不够用,此时需要借助全局校验块 GP_1, GP_2,将整个条带视为一个更大的编码来修复。
因此 LRC 的容错结构是分层的:
| 故障场景 | 修复方式 | 所需读取 |
|---|---|---|
| 单块故障 | 局部修复(组内) | l 个块 |
| 同组双块故障 | 全局修复(全条带) | m 个块 |
| 跨组多块故障 | 全局修复 | m 个块 |
4.2 性能模型
LRC 的性能特征与 EC 类似,但在修复路径上有明显改善。
正常读写
与 EC 相同:系统码设计使得正常读只需访问 1 个数据块所在的节点。写入需要写 m + n_l + n_g 个块(n_l 为局部校验块数,n_g 为全局校验块数),放大率略高于同参数的纯 EC。
降级读
单块不可用时,LRC 的降级读只需读取同组的 l 个块,而非全部 m 个块。l 通常远小于 m(以 \text{LRC}(12,2,2) 为例,l = 6 vs m = 12),降级读延迟和尾延迟都显著降低。
修复速度
这是 LRC 相对于 EC 最核心的改进。继续使用前面的假设(10TB 磁盘,500MB/s 修复带宽),对比 \text{EC}(12,4) 和 \text{LRC}(12,2,2) 的单盘修复时间:
| 编码方式 | 单块修复读取量 | 修复带宽放大 | 10TB 磁盘 MTTR |
|---|---|---|---|
| EC(12,4) | 12 块 | 12 : 1 |
\approx 67 小时 |
| LRC(12,2,2) | 6 块 | 6 : 1 |
\approx 33 小时 |
MTTR 减半意味着修复窗口内再发生故障的概率大幅降低,直接提升了数据安全性。
4.3 成本模型
LRC 降低修复代价的手段是增加局部校验块,这意味着额外的存储开销。
存储放大率
\text{LRC}(12, 2, 2) 共 16 个块(12 数据 + 2 局部 + 2 全局),存储放大率为 16/12 \approx 1.33。对比几种方案:
| 编码方式 | 总块数 | 存储放大率 | 可容忍故障数 | 单块修复读取 |
|---|---|---|---|---|
| 3 副本 | 3 | 3.0x | 2 | 1 块 |
| EC(12,4) | 16 | 1.33x | 4 | 12 块 |
| LRC(12,2,2) | 16 | 1.33x | 3(见下文) | 6 块 |
| EC(6,3) | 9 | 1.5x | 3 | 6 块 |
值得注意的是,\text{LRC}(12,2,2) 和 \text{EC}(12,4) 的总块数相同(都是 16 块),存储放大率也相同。但 LRC 将 4 个校验块拆分为 2 个局部 + 2 个全局,用容错能力的少量让步换取了修复效率的大幅提升。
修复带宽节省
LRC 的修复带宽节省在大集群中尤为显著。假设集群有 1000 块磁盘,平均每天发生 1~2 次单盘故障。对于 \text{EC}(12,4),每次修复产生约 120TB 的读流量(10TB × 12);换成 \text{LRC}(12,2,2),每次修复读流量约 60TB。日常修复带宽减半,对业务流量的影响自然也更小。
4.4 数据安全性模型
LRC 在修复效率上的收益并非没有代价——它牺牲了一部分容错能力。
容错能力分析
\text{LRC}(12, 2, 2) 共有 4 个校验块(2 局部 + 2 全局),但它不能容忍任意 4 个块同时丢失。考虑一个极端情况:D_1, D_2, D_3, LP_1 同时丢失(共 4 个块)。此时局部组 1 的局部校验 LP_1 丢失,无法提供帮助;而需要恢复的数据块有 3 个(D_1, D_2, D_3),全局校验只有 2 个(GP_1, GP_2),2 < 3,超出了全局校验的能力,数据永久丢失。
类似地,如果 D_1, D_2, D_3, D_4 同时丢失,同组的 LP_1 虽然存活但只能提供 1 个方程,加上 2 个全局校验共 3 个方程,仍无法解出 4 个未知数据块。
准确地说,\text{LRC}(12, 2, 2) 能够容忍:
- 任意 3 个块同时丢失(最坏情况即同组 3 个数据块丢失,可用 2 个全局校验 + 1 个局部校验恢复)
- 特定模式下的 4 个块丢失(如两组各丢 1 个数据块 + 2 个全局校验块丢失等)
- 不能保证容忍任意 4 块丢失
与同样 16 块的 \text{EC}(12,4)(可容忍任意 4 块丢失)相比,LRC 的最坏情况容错能力从 4 降到了 3。
实际安全性权衡
在实际生产环境中,这个 trade-off 通常是值得的:
-
单盘故障占绝大多数:Google 的研究8表明,同时发生多块故障的概率远低于单块故障。LRC 对最常见的故障场景(单块故障)修复更快,MTTR 更短,反而降低了窗口期内再次故障的概率。
-
MTTR 缩短的安全增益 > 容错数减少的风险:虽然最坏情况容错从 4 降到 3,但修复速度翻倍带来的安全增益往往大于这一个容错数的损失。数据丢失需要在修复窗口内连续故障,MTTR 越短,这个概率越低。
-
Azure 的实战数据:Microsoft 在论文9中报告,采用 LRC 后集群的整体数据持久性反而优于同等存储开销的纯 EC 方案,原因正是修复速度的提升。
4.5 LRC 编码小结
LRC 编码的核心特征:
- 局部修复:通过在条带内建立局部校验组,将单块修复的读取量从
m降低到l(局部组大小)。 - 分层容错:局部校验处理常见的单块故障,全局校验兜底多块故障。
- 存储效率:与纯 EC 相比,总校验块数相同时存储放大率不变,但最坏情况容错数略有下降。
- 工程定位:相比 EC 更适合大规模冷数据集群,在修复带宽敏感的场景下优势尤为突出。
5. 动手做:为用户选择合适的编码策略
副本、EC、LRC 三种编码方式各有适用场景。选择时通常围绕以下几个维度:
| 决策维度 | 关键问题 |
|---|---|
| 数据温度 | 热数据还是冷数据?读写频率如何? |
| 延迟要求 | 能否接受降级读的额外延迟? |
| 成本预算 | 存储放大率 1.3x 和 3.0x 的差异是否显著? |
| 集群规模 | 磁盘数量是否大到修复风暴成为问题? |
| 可靠性要求 | 数据的 SLA 等级?能容忍多长的修复窗口? |
一条粗略的经验法则:热数据用副本,冷数据用 EC,大规模冷数据集群用 LRC。
关于具体的参数选择方法、成本核算模型和不同场景下的配置建议,将在下一节中专门展开讨论。
6. 小结
本文从副本复制的局限性出发,介绍了 EC 和 LRC 两种纠删编码方案。
EC 基于有限域上的多项式插值和矩阵运算,在给定冗余度下达到最优容错(MDS 性质),存储放大率远低于多副本。代价是降级读和修复时需要读取 m 个块,带来性能和修复带宽上的压力。
LRC 在 EC 基础上引入局部校验组,将最常见的单块修复读取量从 m 降低到局部组大小 l,以少量容错能力的让步换取修复效率的大幅提升。在大规模集群中,更短的 MTTR 反而带来了更高的数据持久性。
三种方案的选择本质上是成本、性能、可靠性三角的权衡,没有放之四海皆准的最优解——只有最适合当前业务需求的配置。
除了本文介绍的 RS 码和 LRC 之外,学术界还有不少结构更复杂、在某些指标上更优的编码方案(如 Pyramid Code、Hitchhiker 等)。
笔者的个人观点是:分布式存储工程师往往偏爱结构美观、对称、易于推演的编码方式。在混沌的分布式环境中,凌晨三点机房发生灾难时,如果一种编码方案不能在 1 分钟内用白纸推演清楚、给一个没有上下文的同事讲明白,那它在生产环境中的可控性就值得怀疑。编码理论上的最优和工程实践中的可靠,相当一部分需要考虑是可理解性这道门槛~
-
Plank, James S. "Jerasure: A library in C facilitating erasure coding for storage applications." Technical Report UT-CS-07-603, University of Tennessee, 2007. ↩
-
Blomer, J. et al. "An XOR-based erasure-resilient coding scheme." Technical Report, ICSI, 1995. ↩
-
Huang, Cheng, et al. "Erasure coding in Windows Azure Storage." USENIX ATC 2012. ↩
-
Ford, Daniel, et al. "Availability in globally distributed storage systems." OSDI 2010. ↩ ↩
-
Huang, Cheng, et al. "Erasure coding in Windows Azure Storage." USENIX ATC 2012. ↩ ↩



