Stream Layer 扮演 WAS 数据存储的角色。本文阅读论文,思考并学习 stream/extent 的实现机制。

Table of Contents
1 Stream Layer
可以看成一个分布式的 append-only 文件系统。为上层 Partition Layer 提供了内部接口,对 stream 进行如下操作。
- open
- close
- delete
- rename
- append to
- concatenate(连接)
stream 可以看作一个大文件,由一串有序的 extent 指针组成。
而 extent 由一串 block append 形成。
思考:
extent组成了stream。append-only 不允许修改中间文件内容,尽可能利用磁盘的顺序写能力。考虑分布式数据库常用的数据结构 LSM 树,思想是把批量随机写转化成为顺序写。实际上只用到文件系统的 append-only 接口。
在后续介绍索引层 Partition Layer 时,很容易联想到 LSM 树,比如 commit-log、checkpoint。 stream layer 不仅提供了 append-only 的文件系统,还负责了数据复制 (副本、EC 等持久性的工作),为索引层构建提供了基石。
可参阅对比单机的 LSM key-value 数据库,如 RocksDB。
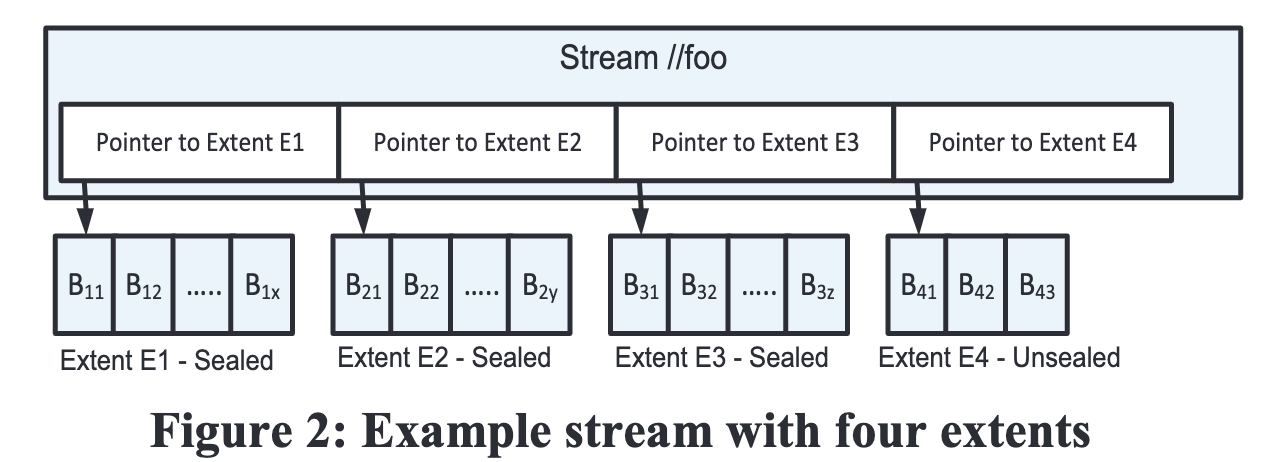
图 2 中展示了一个名字为 "//foo" 的 stream。其包含 4 个 extent,每个 extent 由 blocks 追加而成。
其中 E1~E3 被 seal,不可再写。
seal 是本文存储引擎的一个重要概念。类似于 LSM 数据库,一个数据块 Extent 一旦被 seal,就不可再追加写。
重要的数据结构如下:
1.1 Block
RW 的最小单位,可至 4MB。每次写时,可有若干 block 追加到 extent,block 的大小不必相同。
写时,由客户端 append blocks 并控制 blocks 的大小。
读时,由客户端给出 stream 或者 extent 的 offset。由于 block 级别做了校验,因此必须读出完整的 block。
巡检时,在 Block 层面做校验,防止数据静默损坏。
1.2 Extent
Stream Layer 做复制的单位。默认 3 副本,直接存储在文件系统上。 Extent 的目标大小是 1GB。
对于小文件,上层可以将若干个写在一个 extent 甚至是同一个 block 中。对于大文件,分割写到若干个 extent。
再次强调,stream layer 不关心具体的对象,这些大小文件策略实际由上层 partition layer 执行。
1.3 Stream
由一串 extent 指针组成。顺序写,随机读。只有最后的 extent 才能追加写。
其包含的 extent 组成了一个连续的空间。
新 stream 可以由存在的 extent 组成,直接复制指针即可。
2 Stream Manager / Extent Nodes
讲完数据结构,来看服务划分。
2.1 Stream Manager (SM)
SM 是一个大总管,使用 paxos 保证高可用性。负责
- 管理 stream namespace 和所有
stream/extent状态(定期查询) - 监控健康 EN 的状态
- 创建并分配
extent给 EN - 异步地故障修复和迁移
- 容灾选择(不同 rack、电力区域等)
- GC
extent - 规划 replica 转 EC
SM 不了解任何 block 级别,只管理 stream 和 extent,其状态可以全部放在内存中。一个集群的规模:
extent数量 < 50Mstream数量 < 100,000
可以放到 32GB 的内存中。
2.2 Extent Nodes (EN)
EN 是数据节点,注册到 SM,负责存储 extent。
EN 不了解 stream,只处理 extent 和 blocks。存储在文件系统上,每个 extent 是一个文件。extent 包含了 peer 节点的信息(以 SM 给出的为准)。
EN 和 EN 之间的交互只包括
- 写时的
block复制 - 创建已存在副本的备份
stream级别的 GC 由 SM 负责计算 (删除悬空的 extent),EN 接收指令并执行。暂时不考虑对象、表级别的 GC,由上层负责。
3 Append 和 Seal
允许一次原子 append 多个 data block。读的时候,允许只读一个,以达到更好的写入速度。
为了应对可能的写失败,Client (指 stream layer 的 client,即 partition layer) 需要
- 写 metadata 或者 commit log stream 时,携带序列号。重试写时携带,以识别写重试
- 写 row data 或者 blob data 时候,只有最后一次成功写入返回的位置会返回。多余的写入在后续 GC 中即可回收。(partition layer 的 GC)
extent 有一个目标大小,达到后由 client seal。但不是硬限制,extent 可能有不一样的大小。一旦 sealed,extent 即不可修改。
4 stream layer 集群内复制
stream layer 和 partition layer 协作实现强一致性。系统给出以下一致性保证:
- 一旦一个写入被返回给 client,那么任意副本的读都能读到一样的数据。
- 一旦 extent sealed,从任意副本的读都能读到一样的数据。
4.1 复制流程
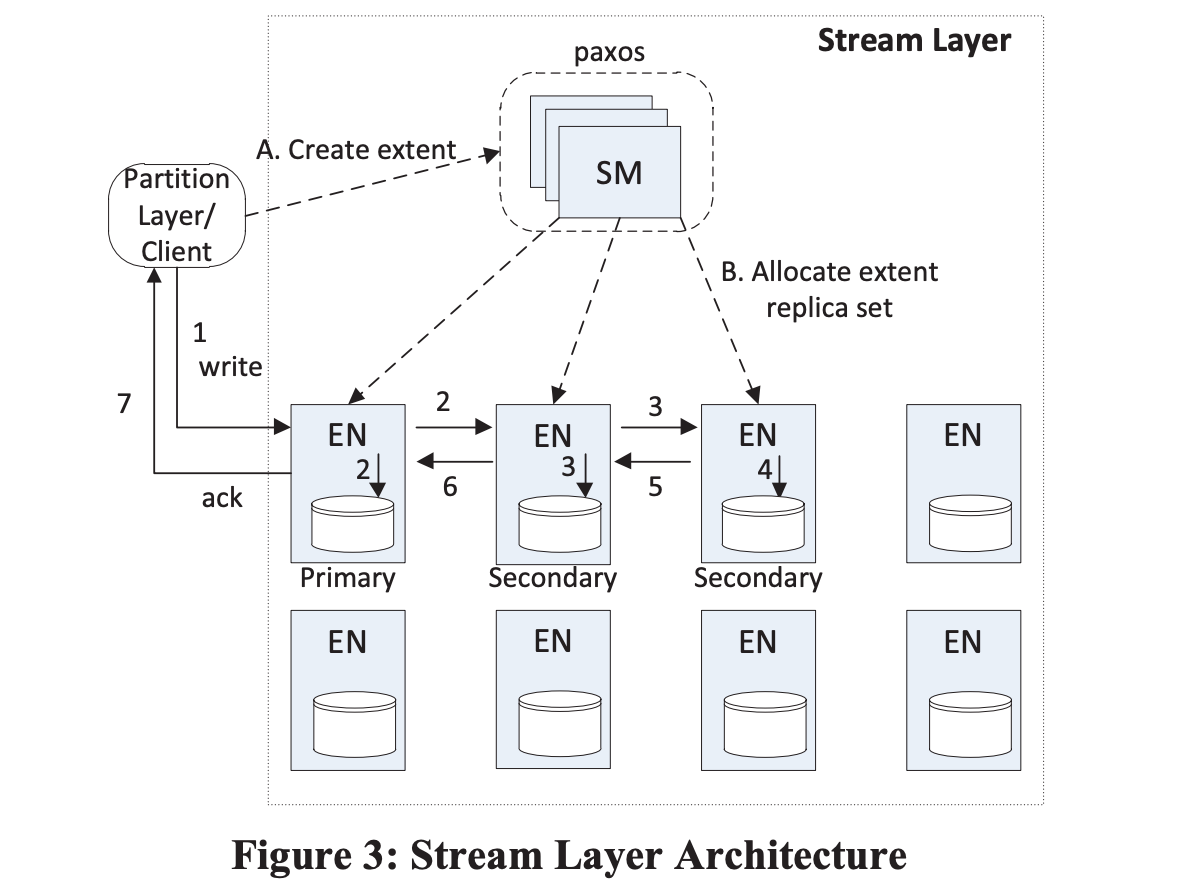
参看图3。
A. client 初次创建 stream
B. SM 从容灾隔离条件中,选出 3 副本创建第一个 extent,指定 1 主 2 从,发给 EN
1-7. client 写发给主 EN,主 EN 复制给两个从 EN
其中:
extentunsealed 时,主从关系不会再变化,避免extent层面的令牌和选举。- 当最后的
extent被 sealed,重复上述过程。
如何应对并发写和潜在的写失败?
由主 EN 来决定:
- 决定 offset
- 并发时决定请求顺序,且回复 client 的顺序与之相同
- 发送 offset 到其余从 EN
- 只有全部写成功后才返回 success
将最后写入的位置作为commmit length。
写失败的处理流程?
- client 直接写 EN
- 因硬盘失效或网络分区写失败,client 通知 SM
- SM seal extent,位置为当前的
commmit length - SM 创建新的 extent,作为 stream 的最后一个 extent
- seal 并创建平均耗时 20ms
SM 会异步的尝试故障迁移,以补全可用的 3 副本。
4.2 Seal
怎么保证 seal 后,extent 长度是强一致性的?
由 SM 负责协调 EN Seal:
- SM 询问 EN 的该 extent 的长度
- 可能有 EN 网络不可达。选择可用 EN 返回的最小长度
- 该长度一定 >= client 所确认写入成功的长度
- 补全 extent 到该长度。这个长度即 SM 所确认的长度
- 不可用的 EN 一旦恢复,扩展到该长度
由此保证了所有可用副本的数据,在 client 可访问范围内是一致的。
思考:
极端情况下,上述的补全机制可能产生额外的数据。Partition Layer 应如何管理收到的 commit offset,才能避免受 “意外补全数据” 影响?
4.3 与 partition layer 的交互
1 从已知位置读
row 和 blob 读取的形式,是 extent+offset,length。只会用显式返回成功的 offset 去读取。
2 partition 加载时,顺序迭代
每个 partition 还有 2 种 stream: metadata 和 commit log。只有这两种在加载时候顺序读。
上文提到,在 partition layer 写 metadata 或者 commit log stream 时,携带序列号并重试。因此可以应对 “意外补全数据” 的重试写场景。
4.4 Replica 转换 EC
应该是以 extent 为单位,转为 EC 存储,降低成本。
5 其他 IO 优化
包含
- IO 调度算法
- 增加 journal 盘并行写
6 小结
笔者阅读后,有以下的收获
- 一个经典的 append-only 分布式文件系统的设计
- 好的分层设计,可以让每个模块各司其职
- Extent 一开始便固定了主从关系,避免额外的令牌管理和选举操作
- 分层不代表两耳不闻窗外事。每层明确自己的可用性和一致性边界,通过协作共同实现系统的可用性和一致性。(比如 stream layer 明确了自己重复写尝试时,可能会有垃圾数据产生,由 parititon layer 去应对)



