作为 go 开发者,我们可能忽略了一名英雄:在内存垃圾标记之后,拾荒器 (scavenging) 最终负责把无用内存归还给操作系统。本文结合例子和源码,分析 go scavenging 的策略,为内存关键型程序提供一些小建议。

阅读本文前,希望读者已经对以下内容已有了解
- go gc 调优指南
- go pprof
Table of Contents
0 引例: 一次诡异的内存突增
在线上服务中,遇到了一次诡异的内存突增。服务在执行后台任务时,RSS 内存由 5GB 量级突增到 30GB,远远超过预期。
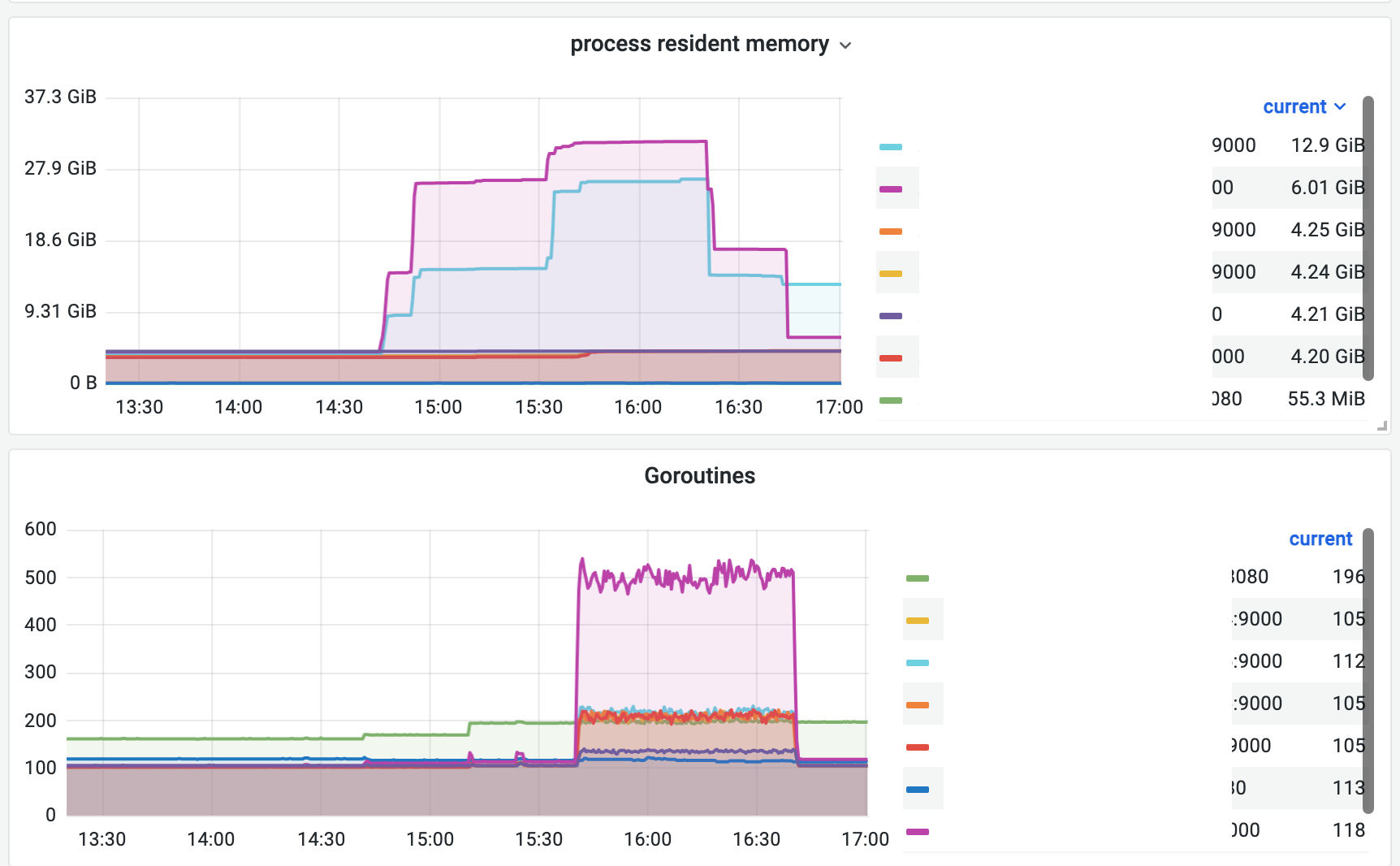
执行的后台任务是数据密集型任务,需要大量读写本地磁盘和网络 IO。笔者下意识想到内存泄漏,随即进行 go pprof heap 查看内存使用情况。

可以确定并不是内存泄漏:
- go pprof heap 前后对比区别不大
- 内存不是缓慢增长,是突增一定水平
- 后台任务结束一段时间后,RSS 回到正常水平
多出来的内存,在 go runtime heap 采样是看不到的!有可能是大量内存在申请、释放。而 cpu pprof 发现有一定量的 cpu 集中在 GC mem。
笔者着实头大了一阵,决定重新翻看 go gc 与内存文档。发现 mem stat 中,唯一变化剧烈的是 heap released。
测试同学提醒服务由空闲转到 api 调用时候,内存也有相当幅度的增长。逐渐锁定 go scavening 机制。但为什么变化如此剧烈?
提前揭秘结论:
- go scavening 负责将多余的内存归还给操作系统。而归还的内存量基于
target heap size计算得来。 - 巧合的是服务中包含了一大块内存索引数据结构,提前申请了虚拟内存高达 80GB 的
map。虽然实际占用的物理内存不大,但对于 go gc 和 scavening,它是实打实的堆内存空间。 - 因此 scavening 向操作系统归还内存的步长会变大,表现为 RSS 突增。
- 但这其实是合理的,因为对于
100 GB的堆内存,变化10%不算剧烈,服务器理当提供充足的冗余。
1 go scavenging
runtime 除了垃圾收集外,还要需要权衡向操作系统返还多少内存:
- 返还太少,这期间不断有新内存创建,进程占用 RSS 大,占用过多内存资源,有引起 OOM 的风险
- 返还过多,不能满足期间内存需求突增。向操作系统重新借用内存的成本巨大,长时间占用 heap lock,导致程序性能下降
本文参考的源码是 go 1.20.12,scanvening 主要基于以下提案
相关源码位于 runtime/mgcscanvenge.go
接下来会搞明白:
- 何时执行 scavening?
- scavenge 多少内存?
- 如何 scavenge 内存?
scavening 包括
- 后台异步清除
- 堆增长时,同步调用清除
本文将两种情况分开说明。
2 何时执行 scavening?
在讨论 go 如何计算归还多少内存之前,必须先明确其运行的时机。
文档提到有两种方式执行 scavening,后台异步执行和堆增长同步执行。
- 后台异步清除
- 堆增长时,同步调用清除
另外,执行 runtime_debug_freeOSMemory 也可以强制触发。
2.1 background sacvening 后台异步清除
对于后台异步清除,启动了一个协程,for 循环执行。
func bgscavenge(c chan int) {
scavenger.init()
c <- 1
scavenger.park()
for {
released, workTime := scavenger.run()
if released == 0 {
scavenger.park()
continue
}
atomic.Xadduintptr(&mheap_.pages.scav.released, released)
scavenger.sleep(workTime)
}
}执行 scavenger.run() 后,如果没有释放内存,则暂时 park。等待唤醒。
scavenger.sleep(workTime) 通过 cpu 时间计算本次休眠时间。最小为 1ms。
scavenger.wake 是非阻塞的,在以下情况会唤醒
- 所有的 span 已经被清扫:
finishsweep_m()。此时位于 GCSweepTermination阶段,STW 状态 sysmon执行时调用
后台异步清扫的内存具体大小,由计算公式得到,下文将详细分析。
2.2 heap-increase scavening 堆增长时
mheap.allocSpan 会触发同步的 scavening。
值得注意的是,这里直接调用了 (p *pageAlloc) scavenge,自行设置回收大小。
2.3 runtime_debug_freeOSMemory
func runtime_debug_freeOSMemory() {
GC()
systemstack(func() { mheap_.scavengeAll() })
}强制 GC 和归还内存,值得注意的是,会取得 heap 锁,全部清除可归还内存。
// scavengeAll acquires the heap lock (blocking any additional
// manipulation of the page allocator) and iterates over the whole
// heap, scavenging every free page available.
func (h *mheap) scavengeAll() {
// ...
// 这里的 shouldStop 传参为 nil,scavenge 会清除全部可归还内存
released := h.pages.scavenge(^uintptr(0), nil)
// ...
}3 scavenging 多少内存?
3.1 background sacvening 后台异步清除
未开启 soft mem limit
由于 go 1.19 引入了 soft mem limit,可以分两种情况。当无软限制时:
goal:期望的内存使用值retainExtraPercent:额外的内存系数,目前取常数 10。即后面计算结果 *1.1,额外留一些 buffer。heapGoal:堆大小的目标值,来自GC的输出,下面会详细看计算公式lastHeapInuse上次 GC 标记终止阶段的HeapInuse
该公式多次调用,随着时间尽量让 RSS 追踪 heap 大小,同时留有一定 buffer 应对内存需求。
开启 soft mem limit
reduceExtraPercent: 稍小的常数,取 5。让实际参与计算的 memoryLimit 更小,从而在逼近内存极限时更积极地工作。
3.2 heap-increase scavening 堆增长时
scavening 大小要计算三个值。
A. 若开启 mem limit,计算内存超额值
内存超额值 = 本次申请的内存 + 使用的内存 - 内存限制这里考虑的是 go heap 内 alloc 的增长。
B. 堆增长值 growth
growth, ok = h.grow(npages + extraPages)这里考虑的 go heap 向操作系统申请内存。
C.如果 gcPercentGoal 存在(具体计算见 3.3 节),计算堆超额值
堆超额值 = (heapInuse + heapFree) + growth - goal其中 heapInuse + heapFree 即为堆 RSS 占用估计值。
最终的大小为
bytesToScavenge = max(内存超额值, min(堆增长值, 堆超额值))由于 scavenging 需要取得 heap 锁,是相对昂贵的操作,因此权衡计算 bytesToScavenge。当 bytesToScavenge=0 时,不启动 scavenging。
3.3 heapGoal 的计算
其中,heapGoal 是怎么计算的呢?
heapGoal 可以理解为 GC 目标堆大小。
这里也分两种情况。
开启 GOGC 时
runtime/mgcpacer.go
func (c *gcControllerState) commit(isSweepDone bool) {
//...
gcPercentHeapGoal := ^uint64(0)
if gcPercent := c.gcPercent.Load(); gcPercent >= 0 {
gcPercentHeapGoal = c.heapMarked + (c.heapMarked+c.lastStackScan.Load()+c.globalsScan.Load())*uint64(gcPercent)/100
}
//...
c.gcPercentHeapGoal.Store(gcPercentHeapGoal)
//...
}即
gcPercentHeapGoal = 标记终止后的存活堆大小+(存活堆大小+栈大小+全局变量大小)*(gcPercent/100)开启 soft mem limit 时
runtime/mgcpacer.go 中,memoryLimitHeapGoal() 给出了比较详细的解释。
// memoryLimit - ((mappedReady - heapFree - heapAlloc) + max(mappedReady - memoryLimit, 0)) - memoryLimitHeapGoalHeadroom
// ^1 ^2 ^3计算策略中考虑了比较多的因素,
- 1: 非堆内存
- 2: 超出的内存量,纳入考虑后得到更小的 heap goal
- 3: 固定为
1 << 20。意图减去一个固定数值,对于更小的堆,产生更大的影响
此处为了方便,可以理解为堆内存的预估+补偿值,更详细的分析超出本文范围。可以搜索 soft mem limit 相关的提案。
最终的 heapGoal 取 gcPercentHeapGoal 和 memoryLimitHeapGoal 两者最小值。
4 何时计算 scavening?
4.1 background sacvening 后台异步清除
scavening 值的计算发生在 MarkTermination, 标记终止阶段。即每次 gc 都会计算。
在更新 GC trigger 和 pacing 后,调用 gcPaceScavenger,以上述的公式计算。
func gcControllerCommit() {
assertWorldStoppedOrLockHeld(&mheap_.lock)
gcController.commit(isSweepDone())
//...
gcPaceSweeper(trigger)
gcPaceScavenger(gcController.memoryLimit.Load(), heapGoal, gcController.lastHeapGoal)
}4.2 heap-increase scavening 堆增长时
mheap.allocSpan 中同步计算(见 3.2)。
5 怎么 scavening?
从高地址到低地址释放。该过程会数次取得 heap 锁。
对于 linux,使用的是 madvise 方式,
将 heapFree 扣减对应大小,heapReleased 加上对应大小。
将 heapStats.committed 扣减对应大小,heapStats.released加上对应大小。
也侧面证明了我们引例中,确实是 scavenging 导致的现象。
6 实验: 自带大型数据结构, 观察 scavening 粒度
6.1 实验程序
在实验程序中,启动多个 goroutine:
- 每 5 s 打印内存状态
- 申请一个 cap 为 5GB 的切片,但只占用 1GB
- 频繁申请 10MB 内存,模拟 rpc 请求
主程序如下
package main
import (
"time"
)
var hugeSlice []byte
func main() {
done := make(chan bool)
// alloc a huge slice
go func() {
hugeSlice = make([]byte, 1024*1024*512*1, 1024*1024*1024*5) // 5GiB cap, 1GiB used
select {
case <-done:
return
}
}()
// simulate mem alloc in rpc
rpcDone := make(chan bool)
for i := 0; i < 100; i++ {
go func() {
for {
select {
case <-rpcDone:
return
default:
_ = make([]byte, 1024*1024*10) // 10MiB
}
}
}()
}
// wait
time.Sleep(time.Second * 30)
close(rpcDone)
time.Sleep(time.Second * 3600)
close(done)
}6.2 稳态运行
开启 gctrace=1 和 scavtrace=1,观察 GC 和 scavenging 情况。(各版本 GODEBUG 可用参数不同,请参考对应版本的 runtime 文档)。
GODEBUG=gctrace=1,scavtrace=1 go run main.go运行 20s 后,退出频繁申请内存的 goroutine。发现当前稳态 RSS 为 12.7GB。
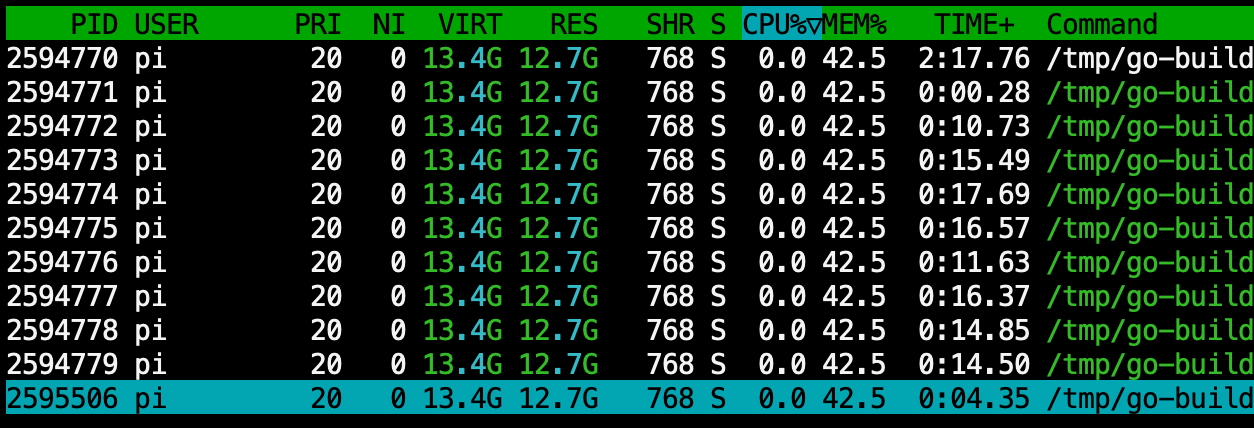
观察 trace 记录:
gc 1 @0.018s 84%: 102+1.6+0.053 ms clock, 819+2.0/1.0/0+0.43 ms cpu, 740->5860->5850 MB, 5860 MB goal, 0 MB stacks, 0 MB globals, 8 P
scav 0 KiB work, 27248 KiB total, 99% util
gc 2 @0.260s 39%: 0.44+3.3+0.39 ms clock, 3.5+1.2/2.6/0+3.1 ms cpu, 11720->12030->5900 MB, 11740 MB goal, 0 MB stacks, 0 MB globals, 8 P
scav 0 KiB work, 8688 KiB total, 96% util
...
gc 44 @21.447s 1%: 2.8+36+0.18 ms clock, 22+0.41/9.8/0+1.4 ms cpu, 12340->12570->5860 MB, 12520 MB goal, 0 MB stacks, 0 MB globals, 8 P
scav 0 KiB work, 7568 KiB total, 46% util
...gc goal 约为 12 GB,和 RSS 较为接近。
6.3 scavenging
在 270s 后,几次时间触发的 GC,开始归还操作系统内存。
...
gc 63 @270.805s 0%: 0.033+0.47+0.008 ms clock, 0.27+0/0.89/0+0.067 ms cpu, 5120->5120->5120 MB, 10240 MB goal, 0 MB stacks, 0 MB globals, 8 P
scav 3121664 KiB work, 3179888 KiB total, 54% util
GC forced
gc 64 @393.266s 0%: 0.035+0.72+0.008 ms clock, 0.28+0/1.3/0+0.068 ms cpu, 5120->5120->5120 MB, 10240 MB goal, 0 MB stacks, 0 MB globals, 8 P
scav 3934208 KiB work, 7114096 KiB total, 90% util
GC forced
gc 65 @513.287s 0%: 0.022+0.51+0.006 ms clock, 0.17+0/0.92/0+0.049 ms cpu, 5120->5120->5120 MB, 10240 MB goal, 0 MB stacks, 0 MB globals, 8 P
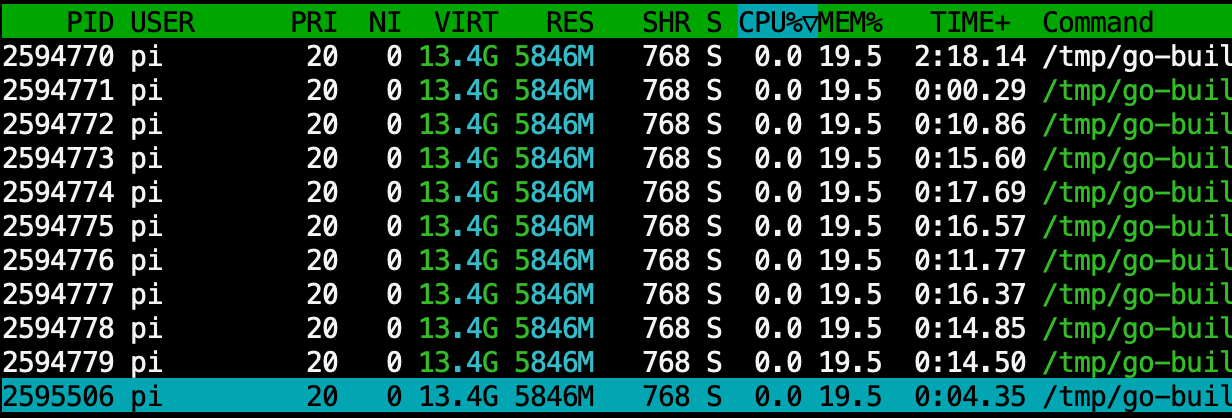
scav 0 KiB work, 7114064 KiB total, 90% utilRSS 最终回归 ~5.8GB,VIRT 约为 13.4GB,符合预期。
7 小经验
本节的经验,更加值得 go heap 中有大量数据(即使已经创建但未使用)的程序注意。
GOGC 与 go mem limit
可以通过调节 GOGC 和 内存限制调节,控制 go 程序对 GC 的积极性和粒度。
在内存限制功能出现前,有一种 Go Memory Ballast 的技巧,通过强行创建一个大数组,令 Go GC 迟钝,从而避免频繁 GC 引起性能抖动。
另外,GOGC 和 go mem limit 可以配合使用,可参考 go memory tuning 的官方文档[1]。
混合部署时,注意 scavening 粒度
当 go heap 中有大量数据结构的程序,即使创建但未使用,也会被 GC 和 scavenging 视为 heap 内存。
当与很多程序共存时,容易发生负载突然上升、scavenging 不及时,系统 OOM 的风险。
参考资料
[1] A Guide to the Go Garbage Collector
[2] A Guide to the Go Garbage Collector - 中文翻译
[3] runtime: smarter scavenging
[4] runtime/debug: soft memory limit
[5] 聊聊两个Go即将过时的GC优化策略
[6] 一次线上内存使用率异常问题排查
[7] go runtime doc
[8] 封面由 StableDiffusionXL 生成




go heap pprof 可能不准确,默认为采样统计。可以参考鸟窝老师的博客
https://colobu.com/2024/04/30/what-s-wrong-with-go-heap-profile