本系列文章是笔者阅读微软存储系统论文 《Windows Azure Storage: a highly available cloud storage service with strong consistency》的笔记和思考。

论文虽然为 11 年发表,但其经典的存储底座思想设计,仍然值得笔者研究学习。笔者也会结合论文内容,思考如何一步一步从单机存储构建分布式的高可用存储系统。希望能加深自己对存储系统的设计能力和理解,望读者不吝指教!
Table of Contents
概览
这篇文章描述是 Windows Azure Storage(WAS) 的论文。WAS 是当时 Azure 支撑微软服务和云平台客户的分布式存储系统。
WAS 对用户提供的产品形态为 Blobs(用户文件/对象存储)、Tables(结构化存储)、Queue(消息队列)。
笔者在和同事的交流学习中,大家认为这个系统最大的特色是三种形态的存储产品共用了一个统一的存储底座(stream layer, extent)。
关于容量,每个集群 10~20 racks,每个 rack 18 个存储密集型节点。集群原始容量 2PB,下一代做到 30PB。
在性能环节,我们可以看到其使用 16 个 VM,达到了 15k/s 小文件随机读或写 (1KB),1000MB/s 的大文件读或写 (4MB)。(注:11 年使用的 VM 仅有 1Gbps 的网络)。
分布式存储系统的要求
在今天看来云存储服务已经很常见了,但还是总结了几点需求:
- 强一致性:虽然同时提供 CAP 理论的三者是困难的,但是文章通过限制特定的失效模型,同时提供。(Section 8 中进行了详细讨论:如果网络分区仅限定在 node 失效或 rack 的交换机失效,可以实现)。
- 全球性的、可扩容的 namespace/storage: 给用户提供的一套命名空间,可以在全球各地使用。
- 灾难恢复(DR):跨区域存储,防止数据中心不可抗力破坏。
- 成本可控
命名空间、容量和规模
在阐述整体架构前,规定了资源的命名空间规则。考虑到了多租户,WAS 的资源 url 统一为
http(s)://AccountName.<service>
.core.windows.net/PartitionNa
me/ObjectName 集群规模
一个存储集群定义为 a storage stamp,由 N 个机架 (rack) 的存储型机器组成。每个机架作为一个容灾域(fault domain),有互不影响的网络和电源设备。一个集群通常由 10~20 个机架,每个机架 18 个存储密集型节点。
论文的第一代集群有 2PB 的原始容量,下一代有 30 PB 的原始容量。
容灾域 (fault domain),是分布式系统设计的常见概念,通常指电源设备、网络设备互不影响的一组拓扑接口,比如机架(rack)。
根据分布式系统可用性的需求,也可以考虑节点node、磁盘disk更小的组件。
比如
TiKV可以根据不同的labels配置集群拓扑方案,实现不同的容灾能力。比如:机房 (zone) -> 数据中心 (dc) -> 机架 (rack) -> 主机 (host)。
参考 [2]Tikv doc - 通过拓扑 label 进行副本调度。
水位
占用集群 70% 的容量、处理、带宽。避免超过 80%。预留 20% 的目的是:
- 预留容量有助于硬盘巡道,实现更高的吞吐
- 当机架级别灾难时,提供容量和可用性
整体架构
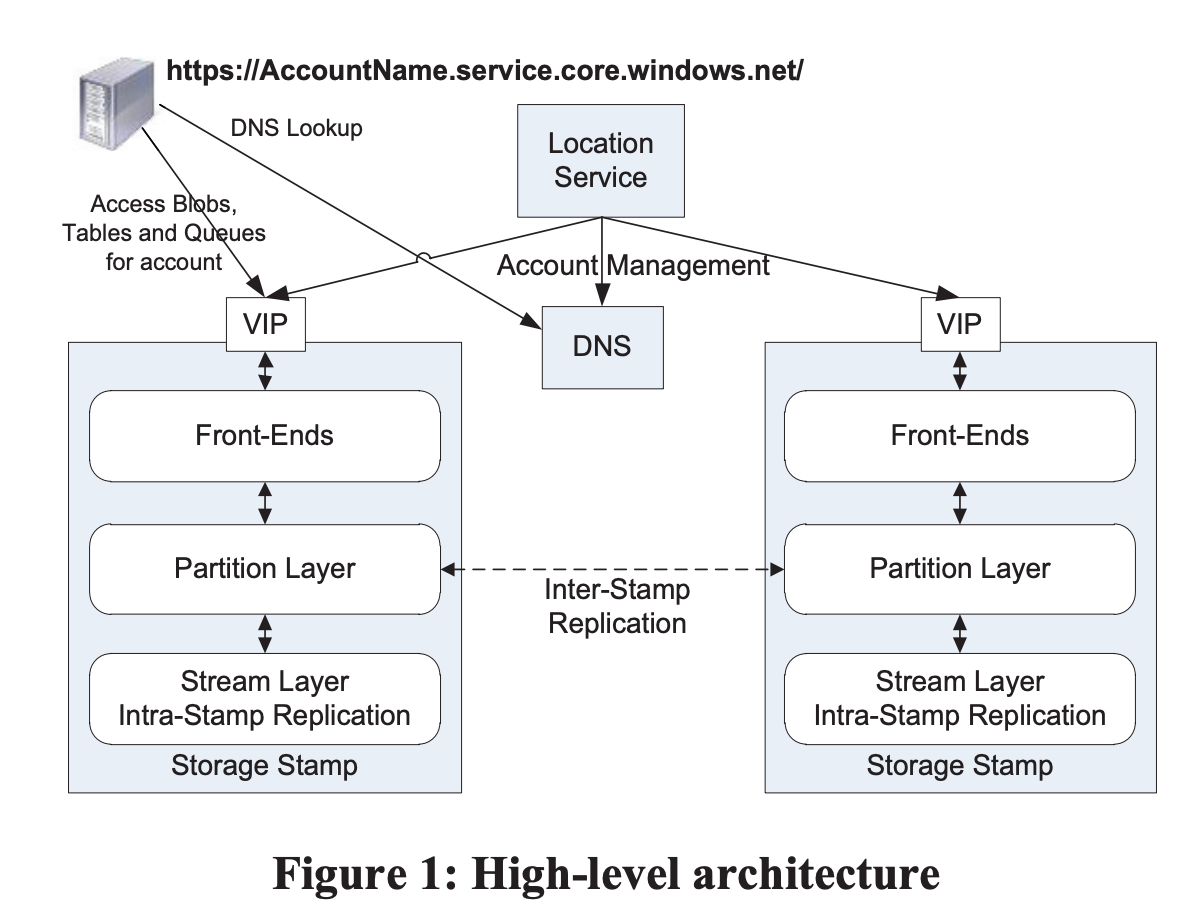
Location Services (LS)
负责
- storage stamps 级别的管理
- 管理用户账户、namespace 在 storage stamps 的分布
- 用户账户、namespace 在 storage stamps 级别的负载均衡和迁移
- 运营上,可以很方便地新部署一个 stamp,然后添加到 LS,由 LS 处理负载均衡和触发迁移。
LS 本身跨两个地域部署,保证可用性。
Storage Stamp 中的三层
Stream Layer
真正负责将数据存储到磁盘,并负责数据的复制,以保证可用性。
- 可以把 Stream Layer 看做分布式文件系统层
- 其中的“文件”,被称为
stream - 而
stream又由一串较大的文件块extent组成
Stream Layer 只懂得以上的概念。
后面会介绍,stream/extent 其实 append-only 的。可以认为 Stream Layer 是一个 append-only 的分布式文件系统。
Partition Layer
负责
- 管理、理解更高层的抽象(Blob, Table, Queue)
- 提供可伸缩的对象命名空间
- 负责对象操作的顺序以及强一致性
- 基于 stream layer 存储对象数据
- 缓存热点对象
- 让数据分散在集群 (通过 PartitionName 哈希)
Partition Layer 基于 Stream Layer 构建。可以认为 Stream Layer 是其数据底座。
Front-End Layer
可以看做存储的网关。内部掌握正确的 partition 路由,同时也做一层缓存。
当今,可以看做该层实现了 S3 接口。
两种复制引擎
系统里有两种复制。
Stamp 内复制 - stream layer
提供了同步复制,以提供数据持久性。在 stream layer 实现。
换句话说就是用户的写请求,必须同步复制到满足要求的容灾域中,才能返回。
用于应对常见故障(分布式系统中的常见故障):硬件损坏等。
Stamp 间复制 - parititon layer
后台异步复制。以对象为单位复制,可以增量或者全量复制。用于
- 实现跨地区的容灾恢复(DR)
- 统一账户跨 stamp 迁移
用于应对罕见故障: 地区级别的故障。
为什么要强调复制? 分布式系统构建的两大手段: 分片(partition)和复制(replicate)[3]。
小结
今天我们总结了这篇论文的开头部分
- append-only 存储底座的思想
- stream layer/partition layer
- 容灾域
- 复制、复制、还有复制
下篇文章我们将详细学习 Stream Layer 的构建。
参考资料
[1] Windows azure storage: a highly available cloud storage service with strong consistency
[2] 通过拓扑 label 进行副本调度 - TiKV docs
[3] Distributed systems for fun and profit
封面由 文心一格 生成。



