本文为一次笔者针对 SSD 调优存储软件的笔记。意外地发现很多 dev 同僚对一些现代数据中心的基础存储设备规格没有概念,遂调研整理此文,供读者 warm-up 阶段作为起步参考。

Table of Contents
1 性能
1.1 性能场景 [1]
| I/O访问模式 | 访问特点 | 典型的应用 |
|---|---|---|
| 流式读 Streaming Read | 全部读,大数据量顺序请求 | 流媒体服务、视频传输 |
| 流式写 Streaming Write | 全部写,大数据量顺序请求 | 存储备份、归档、录像监控 |
| 在线事务处理 OLTP | 大量的并发随机读写请求,4K~16K | 数据库系统,在线业务系统 |
| 文件服务器 File Server | 主要为随机访问,4K~64K,大并发 | 文件、打印、邮件、聊天、决策辅助系统 |
| Web服务器 | 大并发随机访问,4K~512K | Web服务、博客、在线电商、存储服务 |
| 工作站 WorkStation | 数据量中等,顺序/随机访问都有。 | 云游戏,云电脑,个人PC也属于此类 |
1.2 硬盘读写性能指标
存储行业有一些专门的企业级负载测试,如SPC-1,SPC-2。
这里一些关键的指标用于比较 HDD 和 SSD 的性能。[2]
- 吞吐量(Throughput):每秒的读写数据量,单位为MB/s。类似如:吞吐率、带宽、传输率等。
- 时延(Latency):I/O 操作的发送到接收确认所经过的时间,单位为毫秒。类似如:响应时间、请求时间等。
- IOPS(I/O per second):每秒读/写次数,单位为次(计数)。类似如:系统并发量、每秒请求RPS等。
注:一般 NVMe SSD 阵列成本非常高。
下面是笔者在工作中测过的一些性能经验值数量级
| HDD(SATA) | SSD(SATA) | SSD(SCSI/PCIe/NVMe) | |
|---|---|---|---|
| 顺序读 | ~150MB/s | ~400MB/s(受限SATA接口) | 4000MB/s |
| 顺序写 | ~100MB/s | ~150MB/s | 3000MB/s |
| 随机IOPS读 | \~2K(带缓存企业级,无缓存\~100) | ~50K | 400K |
| 随机IOPS写 | \~1K(带缓存企业级,无缓存\~100) | ~10K | 90K |
笔者常见的企业级 SSD 型号为 Intel S4610 3.84TB Mainstream SATA 6Gb Hot Swap SSD[3]。
1.3 SSD 性能特性
写入放大与垃圾回收 - 满载后性能会降低
对于 SSD,新数据只能写入驱动器的全新或已擦除单元。因为必须在写入之前清除空间,所以如果在写入文件时还没有足够的可用空间,则必须先将其擦除。这会对性能产生负面影响。
当FLASH中再也找不到可以直接写入的空白page时,GC就会启动,GC会在FLASH找已经废弃/删除的page,然后将这个page擦掉,用来存放你的新数据
企业级 SSD 提供的性能指标一般是多次满载后的稳态性能指标。
一般经验,不要让SSD满载要保留一定的空间(要预留SSD中10%的容量),这样更有利于发挥它的性能。而且满载下的固态硬盘会更容易出现崩溃的可能性。(因为主控的原因,一些SSD满载也不会掉速,而一些SSD满载则掉速严重。)
厂商主控影响较大
SSD 内部固件有较为复杂的缓存和垃圾回收调度,厂商固件对 SSD 性能影响更大,上述为SSD原理性能。
使用时间长性能会变差(寿命)
使用时间越长会导致SSD性能变差。使用时间变长之后,SSD内部NAND Flash的磨损会加重,NAND Flash磨损变大之后会导致bit错误率提升。
2 OS 层面优化
2.1 内核与驱动软件
SATA SSD 在 Linux 软件层中驱动和 SATA HDD 一致(NVMe则驱动有所不同,存在多队列模型,每个 CPU core 都可以开启 Queue Pair 数据交互)。
SATA SSD 在NUMA多核心结构的限制[4]
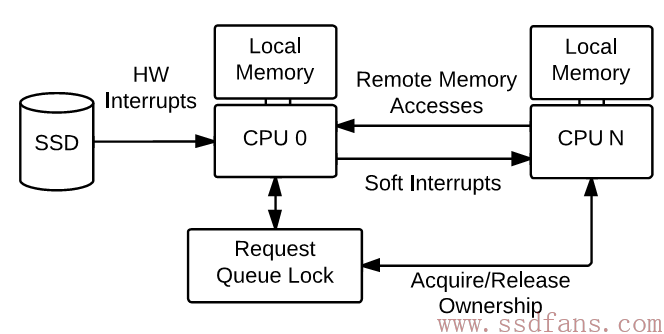
缺陷: 队列锁、硬件中断和跨 CPU 内存访问
若使用 PCIe/NVMe,则可以利用 Linux 多队列技术提升访问性能。
(注: 在现代 Linux 环境下,单 CPU 内核可以支持 80 万 IOPS 左右的 IO 提交率[6]。对于 SATA 固态硬盘,不是瓶颈。)
Linux 存储多队列的内容较多较深,一个好的 Start-Up 可参考: https://szp2016.github.io/linux/%E5%A4%9A%E6%A0%B8%E7%B3%BB%E7%BB%9F%E4%B8%8A%E5%BC%95%E5%85%A5%E5%A4%9A%E9%98%9F%E5%88%97SSD/
所有工具都应该自动将文件系统和分区对齐到 4096 字节的页面大小(4K对齐)。
2.2 Trim
文件系统只是引用磁盘上文件的位置,当文件被删除时,该引用被擦除,允许您在这些空白空间中的旧数据上写入新数据。但是,对于 SSD,新数据只能写入驱动器的全新或已擦除单元。因为必须在写入之前清除空间,所以如果在写入文件时还没有足够的可用空间,则必须先将其擦除。这会对性能产生负面影响。
Linux 的 fstrim 工具在文件系统层面操作。
2.3 I/O调度
/sys/block/sdb/queue/scheduler
该模块是一个决定如何处理I/O请求的核心组件。默认情况下就是非常公平的排队,对于普通的磁盘驱动器来说,这是很好的方案,但对于以期限调度为优势的固态硬盘来说,这并不是最好的。
默认的 I/O 调度程序对数据进行排队,以最大限度地减少 HDD 上的寻道,这对于 SSD 来说不是必需的。因此,使用deadline调度程序来确保批量事务不会减慢小事务[5]。
echo deadline > /sys/block/sdX/queue/scheduler
查看当前的调度算法
dmesg | grep -i scheduler
cat /sys/block/sda/queue/scheduler
3 应用层优化
存储引擎的设计,充分利用 SSD 的优势。
3.1 IO 模式
1.对于 SSD,全顺序读写仍然是最优的[7]
IO Pattern对性能产生影响。IO Pattern影响了SSD内部的GC数据布局,间接影响了GC过程中的数据搬移量,决定了后端流量。
当IO Pattern为全顺序时,这种Pattern对SSD内部GC是最为友好的,写放大接近于1,因此具有最好的性能;当IO Pattern为小块随机时,会产生较多的GC搬移数据量,因此性能大为下降。
在实际应用中,需要通过本地文件系统最优化IO Pattern,获取最佳性能。[7]
2.不同请求大小的IO之间会产生干扰;读写请求之间会产生干扰
小请求会受到大请求的干扰,从而导致小请求的延迟增加,这个比较容易理解,在HDD上同样会存在这种情况。
由于NAND Flash介质存在严重的读写不对称性,因此读写请求之间也会互相干扰,尤其是写请求对读请求产生严重的性能影响。
因此对于SSD,IO 模式的优化仍然是以合理的方式来逼近顺序写入的模式,从而最优化SSD的性能。
3.2 SSD-Friendly Applications [8]
本节经验翻译引述自参考资料[8]。
1.避免就近更新 in-place updating
原本用于减少 HDD 寻道时间的优化对 SSD 有副作用。因为包含数据的 SSD 页不能直接覆盖,必须经过擦除步骤
2.区分冷热数据
受制于SSD特性,冷热数据夹杂在一起,不仅会浪费 I/O 带宽,还会不必要地磨损 SSD。
3.数据结构:采用紧凑的数据结构
SSD 世界中最小的更新单元是页面(例如,4KB)。更新数据也考虑和 Page Size 对齐。
4. IO 处理:避免长时间、繁重的写入
SSD 通常具有 GC 机制,来离线收集块以供以后使用。
GC 可以在后台或前台工作。SSD 控制器通常会有一个空闲块的阈值。每当空闲块的数量低于阈值时,后台 GC 就会启动。后台 GC 是异步发生的,它不会影响应用程序的 I/O 延迟。但是,如果块的请求率超过了 GC 率,而后台 GC 跟不上,则会触发前台 GC,影响性能。
5. IO 处理:避免 SSD 满负荷使用
SSD 使用级别(即磁盘的满载程度)会影响写入放大系数和 GC 导致的写入性能。
在 GC 期间,需要擦除块以创建空闲块。擦除块需要保留包含有效数据的页面以获得空闲块。释放块所需压缩的块数取决于磁盘的满载程度。SSD 的使用率越高,移动的块就越多,这会占用更多的资源并导致更长的 IO 等待。
6. 线程:使用多个线程(相对于单个线程)来做小的 I/O
SSD 具有多个级别的内部并行性:通道、封装、芯片和平面。单个 I/O 线程将无法充分利用这些并行性,从而导致更长的访问时间。使用多个线程可以利用内部并行性。SSD 可以有效地跨可用通道分配读写操作,从而提供高水平的内部 I/O 并发。例如,我们使用一个应用程序来执行 10KB 写入 I/O。使用一个 I/O 线程,达到 115MB/s。两个线程基本上使吞吐量翻倍;四个线程再次将其翻倍。使用八个线程可以达到大约 500MB/s。
问题是:“小”究竟是有多小?答案是任何不能充分利用内部并行性的 I/O 大小都被认为是“小”。例如,对于 4KB 的页面大小和 16 的并行度,阈值应该在 64KB 左右。
7. 线程:使用更少的线程(相对于许多线程)进行大 I/O
对于大型 I/O,可以利用 SSD 的内部并行性,因此较少的线程(即一个或两个)应该足以实现最大的 I/O 吞吐量。吞吐量方面,许多线程没有看到好处。
此外,多线程会引发其他问题和开销。例如,线程之间的资源竞争(例如 SSD 映射表)和受干扰的后台活动(例如操作系统级别的预读和回写)都是复杂的示例。例如,根据我们的实验,当写入大小为 10MB 时,1 个线程可以达到 414MB/s,2 个线程可以达到 816MB/s,而 8 个线程实际上下降到 500MB/s。
4 杂记
笔者四处溜达问了几位新老司机。意外地发现,除了少数对对消费级 PC 硬件比较熟悉的玩家,大部分 dev 并不是很清楚当代数据中心物理机存储的规格和成本。
笔者推荐一个 B 站 UP 主,无情开评。UP 本身是数据中心硬件供应商,经常介绍一些企业级和数据中心的网络、存储、计算硬件。已然成为笔者的电子榨菜。
https://space.bilibili.com/514160575
比如这期,就能快速且有趣地了解现代数据中心的独立服务器规格。
参考
[1] 评测云硬盘读写性能
[3] Intel S4610 3.84TB Mainstream SATA 6Gb Hot Swap SSD
[5] SSD Optimization - debian wiki
比较好的专栏参考资料
[6] Linux 多队列技术




https://info.support.huawei.com/storageinfo/wikipedia/#/home
推荐阅读一下,这个写的很不错。
@某学生 谢谢,不过这个链接可能是内参,我的手机注册账号没有权限